pandas中的read_csv参数详解
1.官网语法
pandas.read_csv(filepath_or_buffer, sep=NoDefault.no_default**,** delimiter=None**,** header='infer’, names=NoDefault.no_default**,** index_col=None**,** usecols=None**,** squeeze=False**,** prefix=NoDefault.no_default**,** mangle_dupe_cols=True**,** dtype=None**,** engine=None**,** converters=None**,** true_values=None**,** false_values=None**,** skipinitialspace=False**,** skiprows=None**,** skipfooter=0**,** nrows=None**,** na_values=None**,** keep_default_na=True**,** na_filter=True**,** verbose=False**,** skip_blank_lines=True**,** parse_dates=False**,** infer_datetime_format=False**,** keep_date_col=False**,** date_parser=None**,** dayfirst=False**,** cache_dates=True**,** iterator=False**,** chunksize=None**,** compression='infer’, thousands=None**,** decimal=’.', lineterminator=None**,** quotechar=’"', quoting=0**,** doublequote=True**,** escapechar=None**,** comment=None**,** encoding=None**,** encoding_errors='strict’, dialect=None**,** error_bad_lines=None**,** warn_bad_lines=None**,** on_bad_lines=None**,** delim_whitespace=False**,** low_memory=True**,** memory_map=False**,** float_precision=None**,** storage_options=None**)**
read_csv()函数在pandas中用来读取文件(逗号分隔符),并返回DataFrame。
2.参数详解
2.1 filepath_or_buffer(文件)
注:不能为空
filepath_or_buffer: str, path object or file-like object
设置需要访问的文件的有效路径。
可以是URL,可用URL类型包括:http, ftp, s3和文件。
对于多文件正在准备中本地文件读取实例:😕/localhost/path/to/table.csv
# 本地相对路径:
pd.read_csv('data/data.csv') # 注意目录层级
pd.read_csv('data.csv') # 如果文件与代码文件在同目录下
pd.read_csv('data/my/my.data') # CSV 文件扩展名不一定是 csv
# 本地绝对路径:
pd.read_csv('/user/data/data.csv')
2.2 sep(分隔符)
sep: str, default ‘,’
指定分隔符。如果不指定参数,则会尝试使用逗号分隔。分隔符长于一个字符并且不是‘\s+’,
将使用python的语法分析器。并且忽略数据中的逗号。正则表达式例子:’\r\t’
# 数据分隔转化是逗号, 如果是其他可以指定
pd.read_csv(data, sep='\t') # 制表符分隔 tab
pd.read_table(data) # read_table 默认是制表符分隔 tab
pd.read_csv(data, sep='|') # 制表符分隔 tab
pd.read_csv(data,sep="(?<!a)\|(?!1)", engine='python') # 使用正则
2.3 delimiter(分隔符)
delimiter: str, default None
定界符,sep的别名。
2.4 header(表头)
header: int, list of int, default ‘infer’
指定行数用来作为列名,数据开始行数。
如果文件中没有列名,则默认为0,否则设置为None。如果明确设定header=0 就会替换掉原来存在
列名。
header参数可以是一个list例如:[0,1,3],这个list表示将文件中的这些行作为列标题(意味着
每一列有多个标题),介于中间的行将被忽略掉(例如本例中的2;本例中的数据1,2,4行将被作为多
级标题出现,第3行数据将被丢弃,dataframe的数据从第5行开始)。
注意:如果skip_blank_lines=True 那么header参数忽略注释行和空行,所以header=0表示第一
行数据而不是文件的第一行。
# 默认系统会推断,如果指定列名会被忽略
pd.read_csv(data, header=0) # 第一行
pd.read_csv(data, header=None) # 没有表头
pd.read_csv(data, header=[0,1,3]) # 多层索引 MultiIndex
2.5 names(列名)
names: array-like, optional
用于结果的列名列表,如果数据文件中没有列标题行,就需要执行header=None。默认列表中不
能出现重复,除非设定参数mangle_dupe_cols=True。
pd.read_csv(data, names=['列1', '列2']) # 指定列名列表
2.6 index_col(索引列)
index_col: int, str, sequence of int / str, or False, default None
用作行索引的列编号或者列名,如果给定一个序列则有多个行索引。
如果文件不规则,行尾有分隔符,则可以设定index_col=False 来是的pandas不适用第一列作为行
索引。
# 默认为 `None`, 不自动识别索引
pd.read_csv(data, index_col=False) # 不再使用首列作为索引
pd.read_csv(data, index_col=0) # 第几列是索引
pd.read_csv(data, index_col='年份') # 指定列名
pd.read_csv(data, index_col=['a','b']) # 多个索引
pd.read_csv(data, index_col=[0, 3]) # 按列索引指定多个索引
2.7 usecols(使用部分列)
usecols: list-like or callable, optional
返回一个数据子集,该列表中的值必须可以对应到文件中的位置(数字可以对应到指定的列)或者是
字符传为文件中的列名。例如:usecols有效参数可能是 [0,1,2]或者是 [‘foo’, ‘bar’,
‘baz’]。使用这个参数可以加快加载速度并降低内存消耗。
# 读取部分列
pd.read_csv(data, usecols=[0,4,3]) # 按索引只读取指定列,顺序无关
pd.read_csv(data, usecols=['列1', '列5']) # 按列名,列名必须存在
# 指定列顺序,其实是 df 的筛选功能
pd.read_csv(data, usecols=['列1', '列5'])[['列5', '列1']]
# 以下用 callable 方式可以巧妙指定顺序, in 后边的是我们要的顺序
pd.read_csv(data, usecols=lambda x: x.upper() in ['COL3', 'COL1'])
2.8 squeeze(返回序列)
squeeze: bool, default False
如果文件值包含一列,则返回一个Series,如果是多个列依旧还是DataFrame。
# 只取一列会返回一个 Series
pd.read_csv(data, usecols=[0], squeeze=True)
# 如果是两列则还是 df
pd.read_csv(data, usecols=[0, 2], squeeze=True)
2.9 prefix(表头前缀)
prefix: str, optional
在没有列标题时,给列添加前缀。例如:添加‘X’ 成为 X0, X1, …
# 表头为 c_0、c_2
pd.read_csv(data, prefix='c_', header=None)
2.10 mangle_dupe_cols(处理重复列名)
mangle_dupe_cols: bool, default True
重复的列,将‘X’…’X’表示为‘X.0’…’X.N’。如果设定为False则会将所有重名列覆盖。
data = 'a,b,a\n0,1,2\n3,4,5'
pd.read_csv(StringIO(data), mangle_dupe_cols=True)
# 表头为 a b a.1
# False 会报 ValueError 错误
2.11 dtype(数据类型)
dtype: Type name or dict of column -> type, optional
每列数据的数据类型。例如 {‘a’: np.float64, ‘b’: np.int32}
pd.read_csv(data, dtype=np.float64) # 所有数据均为此数据类型
pd.read_csv(data, dtype={'c1':np.float64, 'c2': str}) # 指定字段的类型
pd.read_csv(data, dtype=[datetime, datetime, str, float]) # 依次指定
2.12 engine(引擎)
engine: {‘c’, ‘python’}, optional
Parser engine to use. The C engine is faster while the python engine is currently more feature-complete.
使用的分析引擎。可以选择C或者是python。C引擎快,但是Python引擎功能更加完备。
2.13 converters(列数据处理)
converters: dict, optional
列转换函数的字典。key可以是列名或者列的序号。
from io import StringIO
data = 'x,y\na,1\nb,2'
def foo(p):
return p+'s'
# x 应用函数, y 使用 lambda
pd.read_csv(StringIO(data), converters={'x': foo,
'y': lambda x: x*3})
# 输出:
x y
0 as 111
1 bs 222
# 使用列索引
pd.read_csv(StringIO(data),
converters={0: foo, 1: lambda x: x*3})
2.14 true_values(真值转换)
true_values: list, optional
Values to consider as True 将指定的文本转换为 True, 可以用列表指定多个值。
from io import StringIO
data = ('a,b,c\n1,Yes,2\n3,No,4')
pd.read_csv(StringIO(data),
true_values=['Yes'], false_values=['No'])
# 输出
a b c
0 1 True 2
1 3 False 4
2.15 false_values(假值转换)
false_values: list, optional
Values to consider as False将指定的文本转换为 False, 可以用列表指定多个值。
2.16 skipinitialspace(忽略分隔符后的空白)
skipinitialspace: bool, default False
忽略分隔符后的空白(默认为False,即不忽略).
data = 'a, b, c\n 1, 2, 3\n 4 ,5, 6'
pd.read_csv(StringIO(data), skipinitialspace=True)
# 输出
a b c
0 1 2 3
1 4 5 6
2.17 skiprows(跳过指定行)
skiprows: list-like, int or callable, optional
需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始)。
# 跳过前2行
pd.read_csv(data, skiprows=2)
# 跳过前2行
pd.read_csv(data, skiprows=range(2))
# 跳过指定行
pd.read_csv(data, skiprows=[24,234,141])
# 跳过指定行
pd.read_csv(data, skiprows=np.array([2, 6, 11]))
# 隔行跳过
pd.read_csv(data, skiprows=lambda x: x % 2 != 0)
2.18 shipfooter(尾部跳过)
skipfooter: int, default 0
从文件尾部开始忽略。 (c引擎不支持)
pd.read_csv(filename, skipfooter=1) # 最后一行不加载
2.19 nrows(读取行数)
nrows: int, optional
需要读取的行数(从文件头开始算起)。一般用于较大的数据文件
pd.read_csv(data, nrows=1000)
2.20 na_values(空值替换)
na_values: scalar, str, list-like, or dict, optional
一组用于替换NA/NaN的值。如果传参,需要制定特定列的空值。默认为‘1.#IND’, ‘1.#QNAN’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘nan’`.
# 5 和 5.0 会被认为 NaN
pd.read_csv(data, na_values=[5])
# ? 会被认为 NaN
pd.read_csv(data, na_values='?')
# 空值为 NaN
pd.read_csv(data, keep_default_na=False, na_values=[""])
# 字符 NA 字符 0 会被认为 NaN
pd.read_csv(data, keep_default_na=False, na_values=["NA", "0"])
# Nope 会被认为 NaN
pd.read_csv(data, na_values=["Nope"])
# a、b、c 均会被认为 NaN 等于 na_values=['a','b','c']
pd.read_csv(data, na_values='abc')
# 指定列的指定值会被认为 NaN
pd.read_csv(data, na_values={'c':3, 1:[2,5]})
2.21 keep_fault_na(保留默认空值)
keep_default_na: bool, default True
析数据时是否包含默认的NaN值,是否自动识别。
如果指定na_values参数,并且keep_default_na=False,那么默认的NaN将被覆盖,否则添加。
# 不自动识别空值
pd.read_csv(data, keep_default_na=False)
| keep_default_na | na_values | 逻辑 |
|---|---|---|
| True | 指定 | na_values 的配置附加处理 |
| True | 未指定 | 自动识别 |
| False | 指定 | 使用 na_values 的配置 |
| False | 未指定 | 不做处理 |
注:如果
na_filter为 False (默认是 True), 那么 keep_default_na 和 na_values parameters 均无效。
2.22 na_filter(丢失值检查)
na_filter: bool, default True
是否检查丢失值(空字符串或者是空值)。对于大文件来说数据集中没有空值,设定na_filter=False可以提升读取速度。
# boolean, default True
pd.read_csv(data, na_filter=False) # 不检查
2.23 verbose(解析信息)
verbose: bool, default False
是否打印各种解析器的输出信息,例如:“非数值列中缺失值的数量”等。
# 可以看到解析信息
pd.read_csv(data, verbose=True)
# Tokenization took: 0.02 ms
# Type conversion took: 0.36 ms
# Parser memory cleanup took: 0.01 ms
2.24 skip_blank_lines(跳过空行)
skip_blank_lines: bool, default True
如果为True,则跳过空行;否则记为NaN。
# 不跳过空行
pd.read_csv(data, skip_blank_lines=False)
2.25 parse_dates(日期时间解析)
parse_dates: bool or list of int or names or list of lists or dict, default False
- boolean. True -> 解析索引
- list of ints or names. e.g. If [1, 2, 3] -> 解析1,2,3列的值作为独立的日期列;
- list of lists. e.g. If [[1, 3]] -> 合并1,3列作为一个日期列使用
- dict, e.g. {‘foo’ : [1, 3]} -> 将1,3列合并,并给合并后的列起名为"foo"
pd.read_csv(data, parse_dates=True) # 自动解析日期时间格式
pd.read_csv(data, parse_dates=['年份']) # 指定日期时间字段进行解析
# 将 1、4 列合并解析成名为 时间的 时间类型列
pd.read_csv(data, parse_dates={'时间':[1,4]})
2.26 infer_datetime_format(自动识别日期时间)
infer_datetime_format: bool, default False
如果设定为True并且parse_dates 可用,那么pandas将尝试转换为日期类型,如果可以转换,转换
方法并解析。在某些情况下会快5~10倍。
pd.read_csv(data, parse_dates=True, infer_datetime_format=True)
2.27 keep_date_col(保留被时间组合列)
keep_date_col: bool, default False
如果有多列解析成一个列,自动会合并到新解析的列,去掉此列,如果设置为 True 则会保留。
pd.read_csv(data, parse_dates=[[1, 2], [1, 3]], keep_date_col=True)
2.28 date_parser(日期时间解析器)
date_parser: function, optional
用于解析日期的函数,默认使用dateutil.parser.parser来做转换。Pandas尝试使用三种不同的方
式解析,如果遇到问题则使用下一种方式。
1.使用一个或者多个arrays(由parse_dates指定)作为参数;
2.连接指定多列字符串作为一个列作为参数;
3.每行调用一次date_parser函数来解析一个或者多个字符串(由parse_dates指定)作为参数。
# 指定时间解析库,默认是 dateutil.parser.parser
date_parser=pd.io.date_converters.parse_date_time
date_parser=lambda x: pd.to_datetime(x, utc=True, format='%d%b%Y')
date_parser = lambda d: pd.datetime.strptime(d, '%d%b%Y')
pd.read_csv(data, parse_dates=['年份'], date_parser=date_parser)
2.29 dayfirst(日期日在前)
dayfirst: bool, default False
DD/MM格式的日期类型,如日期 2000-01-06 如果 dayfirst=True 则会转换成 2000-06-01。
pd.read_csv(data, dayfirst=True, parse_dates=[0])
2.30 cache_dates(日期缓存)
cache_dates: bool, default True
如果为 True,则使用唯一的转换日期缓存来应用 datetime 转换。 解析重复的日期字符串时,尤其是带有时区偏移的日期字符串时,可能会大大提高速度。
pd.read_csv(data, cache_dates=False)
2.31 iterator(读取文件对象)
iterator: bool, default False
返回一个TextFileReader 对象,以便逐块处理文件。
pd.read_csv(data, iterator=True)
2.32 chunksize(文件块)
chunksize: int, optional
文件块的大小, See IO Tools docs for more informationon iterator and chunksize.
pd.read_csv(data, chunksize=100000)
# 分片处理大文件
df_iterator=pd.read_csv(file,chunksize=50000)
def process_dataframe(df):
pass
return processed_df
for index,df_tmp in enumerate(df_iterator):
df_processed=process_dataframe(df_tmp)
if index>0:
df_processed.to_csv(path)
else:
df_processed.to_csv(path,mode='a',header=False)
2.33 compression(压缩)
compression: {‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None}, default ‘infer’
直接使用磁盘上的压缩文件。如果使用infer参数,则使用 gzip, bz2, zip或者解压文件名中以‘.gz’, ‘.bz2’, ‘.zip’, or ‘xz’这些为后缀的文件,否则不解压。如果使用zip,那么ZIP包中国必须只包含一个文件。设置为None则不解压。
新版本0.18.1版本支持zip和xz解压
pd.read_csv('sample.tar.gz', compression='gzip')
2.34 thousands(千分位分隔符)
thousands: str, optional
千分位分割符,如“,”或者“."
pd.read_csv('test.csv', thousands=',') # 逗号分隔
2.35 decimal(小数点)
decimal: str, default ‘.’
字符中的小数点 (例如:欧洲数据使用’,‘).
pd.read_csv(data, decimal=",")
2.36 lineterminator(行结束符)
lineterminator: str (length 1), optional
行分割符,只在C解析器下使用。
data = 'a,b,c~1,2,3~4,5,6'
pd.read_csv(StringIO(data), lineterminator='~')
2.37 quotechar(引号)
quotechar: str (length 1), optional
引号,用作标识开始和结束的字符,引号内的分割符将被忽略。
pd.read_csv(file, quotechar = '"')
2.38 quoting(引号常量)
quoting: int or csv.QUOTE_* instance, default 0
控制csv中的引号常量。可选 QUOTE_MINIMAL (0), QUOTE_ALL (1), QUOTE_NONNUMERIC (2) or QUOTE_NONE (3)
import csv
pd.read_csv('input_file.csv', quoting=csv.QUOTE_NONE)
2.39 doublequote(双引号)
doublequote: bool, default True
双引号,当单引号已经被定义,并且quoting 参数不是QUOTE_NONE的时候,使用双引号表示引号内的元素作为一个元素使用。
import csv
pd.read_csv('data.csv', quotechar='"', doublequote=True, quoting=csv.QUOTE_NONNUMERIC)
2.40 escapechar(不受分隔符限制)
escapechar: str (length 1), optional
当quoting 为QUOTE_NONE时,指定一个字符使的不受分隔符限值。
pd.read_csv(StringIO(data), escapechar='\\', encoding='utf-8')
2.41 comment(注释标识)
comment: str, optional
标识着多余的行不被解析。如果该字符出现在行首,这一行将被全部忽略。这个参数只能是一个字符,空行(就像skip_blank_lines=True)注释行被header和skiprows忽略一样。例如如果指定comment=’#’ 解析‘#empty\na,b,c\n1,2,3’ 以header=0 那么返回结果将是以’a,b,c’作为header。
s = '# notes\na,b,c\n# more notes\n1,2,3'
pd.read_csv(StringIO(s), sep=',', comment='#', skiprows=1)
2.42 encoding(编码)
encoding: str, optional
指定字符集类型,通常指定为’utf-8’. List of Python standard encodings
pd.read_csv('gairuo.csv', encoding='utf8')
pd.read_csv("gairuo.csv",encoding="gb2312") # 常见中文
# 其他常用编码 ISO-8859-1 latin-1 gbk
2.43 encoding_errors
encoding_errors: str, optional, default “strict”

2.44 dialect
dialect: str or csv.Dialect, optional
如果没有指定特定的语言,如果sep大于一个字符则忽略。具体查看csv.Dialect 文档
import csv
csv.register_dialect(
'mydialect',
delimiter = ',',
quotechar = '"',
doublequote = True,
skipinitialspace = True,
lineterminator = '\r\n',
quoting = csv.QUOTE_MINIMAL)
pd.read_csv("gr.csv", encoding="gbk", dialect='mydialect')
2.45 error_bad_lines(坏行处理)
error_bad_lines: bool, default None
如果一行包含太多的列,容易出现错误,那么默认不会返回DataFrame ,如果设置成false,那么会将"坏行"剔除(只能在C解析器下使用)。
pd.read_csv(StringIO(data), error_bad_lines=False)
2.46 warn_bad_lines(坏行警告)
warn_bad_lines: bool, default None
如果error_bad_lines =False,并且warn_bad_lines =True 那么所有的“bad lines”将会被输出(只能在C解析器下使用)。
pd.read_csv(StringIO(data), warn_bad_lines=False)
2.47 on_bad_lines
on_bad_lines: {‘error’, ‘warn’, ‘skip’}, default ‘error’

2.48 delim_whitespace(空格分隔符)
delim_whitespace: bool, default False
指定是否将空格(例如’‘或’\ t’)用作分隔符。 等效于设置sep =’\s+’。 如果此选项设置为True,则不应该为delimiter参数传递任何内容。
pd.read_csv(StringIO(data), delim_whitespace=False)
2.49 low_memory(低内存)
low_memory: bool, default True
分块加载到内存,再低内存消耗中解析。但是可能出现类型混淆。确保类型不被混淆需要设置为False。或者使用dtype 参数指定类型。注意使用chunksize 或者iterator 参数分块读入会将整个文件读入到一个Dataframe,而忽略类型(只能在C解析器中有效)
pd.read_csv(StringIO(data), low_memory=False)
2.50 memory_map(内存映射)
memory_map: bool, default False
如果使用的文件在内存内,那么直接map文件使用。使用这种方式可以避免文件再次进行IO操作。
pd.read_csv('gr.csv', low_memory=False)
2.51 float_precison(高精度转换)
float_precision:str, optional
指定C引擎应使用哪个转换器进行浮点运算,对于普通转换器,选项为“None”或“high”,原始低精度转换器的“legacy”,以及 round-trip 换器的“ round_trip”。
val = '0.3066101993807095471566981359501369297504425048828125'
data = 'a,b,c\n1,2,{0}'.format(val)
abs(pd.read_csv(StringIO(data), engine='c',float_precision='high')['c'][0] - float(val))
2.52 storage_options(存储选项)
storage_options:dict, optional
注:pandas 1.2.0 新增。
fsspec 还允许使用复杂的URL,以访问压缩档案中的数据,文件的本地缓存等。 要在本地缓存上面的示例,可以增加参数配置:
# Amazon S3, 安装支持库 fsspec
pd.read_csv(
"simplecache::s3://ncei-wcsd-archive/data/processed/SH1305/18kHz/"
"SaKe2013-D20130523-T080854_to_SaKe2013-D20130523-T085643.csv",
storage_options={"s3": {"anon": True}},
)
指定“anon”参数用于实现的“ s3”部分,而不是用于缓存实现。 请注意,仅在会话期间缓存到临时目录,但是您也可以指定永久存储。更多参数可参考fsspec文档
注:pandas 1.3.0 新增。
从fsspec未处理的远程URL(例如HTTP和HTTPS)读取时,传递到存储的字典将用于创建请求中包含的头()。这可用于控制用户代理标头(User-Agent header)或发送其他自定义标头。例如:
headers = {"User-Agent": "pandas"}
df = pd.read_csv(
"https://download.bls.gov/pub/time.series/cu/cu.item",
sep="\t",
storage_options=headers
)
3.返回值
DataFrame or TextParser
A comma-separated values (csv) file is returned as two-dimensional data structure with labeled axes.
参考链接:
1.https://www.gairuo.com/p/pandas-read-csv
相关文章:
Python — — turtle 常用代码
目录 一、设置画布 二、画笔 1、画笔属性 2、绘图命令 (1) 画笔运动命令 (2) 画笔控制命令 (3) 全局控制命令 (4) 其他命令 3. 命令详解 三、文字显示为一个圆圈 四、画朵小花 一、设置画布 turtle为我们展开用于绘图区域,我们可以设置它的…...

【我是土堆 - PyTorch教程】学习随手记(已更新 | 已完结 | 10w字超详细版)
目录 1. Pytorch环境的配置及安装 如何管理项目环境? 如何看自己电脑cuda版本? 安装Pytorch 2. Python编辑器的选择、安装及配置 PyCharm PyCharm神器 Jupyter(可交互) 3. Python学习中的两大法宝函数 说明 实战操…...
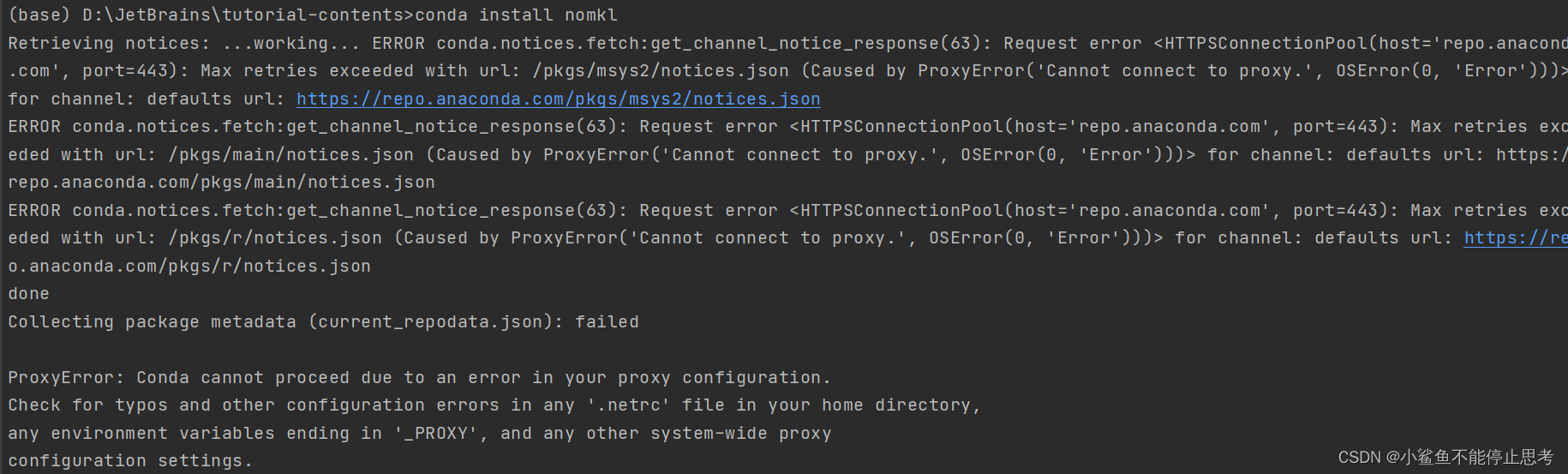
“OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.”解决方法总结
一、问题描述 跑了点神经网络的代码,想画几个激活函数的图像,代码如下: 运行后报了以下错误: 翻译如下: OMP:错误 #15:正在初始化 libiomp5md.dll,但发现 libiomp5md.dll 已经初…...
python3.11.2安装 + pycharm安装
下载 :https://www.python.org/ 2.双击下载的软件: 3.进入安装界面 下一步,点击 是 上一步点击后就看到如下: 安装成功了,接下来检测一下:cmd 安装pycharm PyCharm是一种Python IDE(Integr…...

Python中numpy.polyfit的用法详解
numpy中polyfit的用法 参数 polyfit(x, y, deg, rcondNone, fullFalse, wNone, covFalse):x:M个采样点的横坐标数组; y:M个采样点的纵坐标数组;y可以是一个多维数组,这样即可拟合相同横坐标的多个多项式; deg:多项式…...
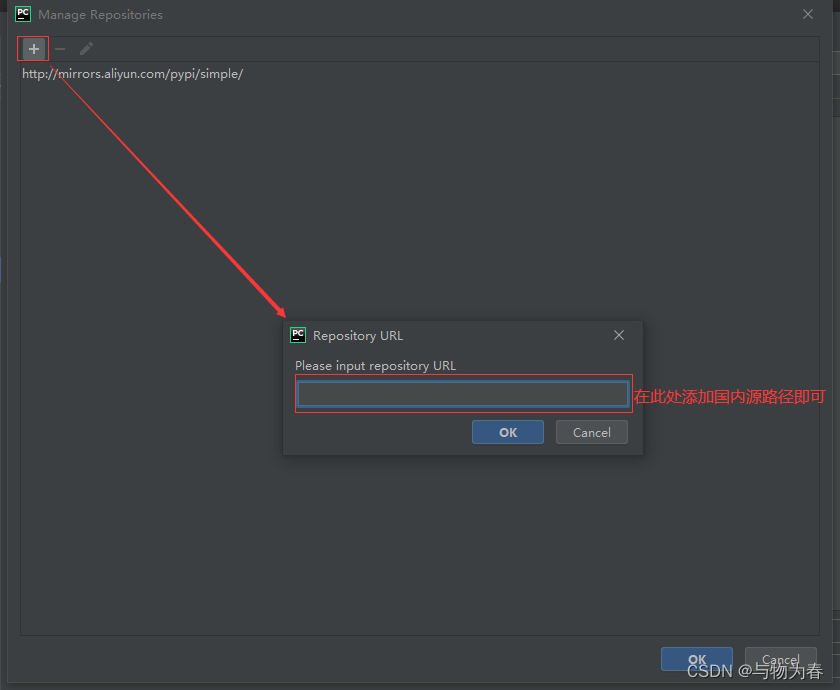
彻底解决Python包下载慢问题
python默认使用的是国外镜像,有时候下载非常慢,最快的办法就是在下载命令中增加国内源: 常用的国内源如下: 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/ 阿里云:http://mirrors.aliyun.com/pypi/…...
Anaconda 使用指南,少走弯路
anaconda包管理器和环境管理器,强烈建议食用 1.下载 官网下载太慢可选用镜像下载 官网下载 :Anaconda | Individual Editionhttps://www.anaconda.com/products/distribution 镜像下载:Index of /anaconda/archive/ | 清华大…...
使用stable diffusion webui时,安装gfpgan失败的解决方案(windows下的操作)
1.问题描述 初次打开stable diffusion webui时,需要安装gfpgan等github项目。但在安装gfpgan时,显示RuntimeError: Couldnt install gfpgan 2.解决方案 无法安装gfpgan的原因是网络问题,就算已经科学上网,并设置为全局&#x…...

Python 中导入csv数据的三种方法
这篇文章主要介绍了Python 中导入csv数据的三种方法,内容比较简单,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下微点阅读小编收集的文章介绍。 Python 中导入csv数据的三种方法,具体内容如下所示: 1、通过…...
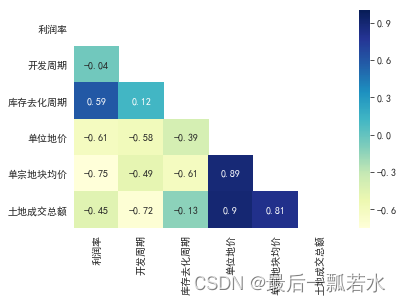
相关性分析、相关系数矩阵热力图
相关性 相关性分析是研究两组变量之间是否具有线性相关关系,所以做相关性分析的前提是假设变量之间存在线性相关性,得到的结果也是描述变量间的线性相关程度。除此之外,相关性分析方法还会有其他的假设条件。而灰色关联度分析首先对数据量要求…...
【python123】题目答案整理 ------更多答案见专栏
目录 二老鼠打洞 来自计算机的问候-任意数量参数 自定义幂函数 来自计算机的问候-多参函数 编写函数输出自除数 最大素数 求数列前n项的平方和 生兔子 计算圆周率——割圆法 数列求前n项和 素数: *如有错误请私聊纠正 二老鼠打洞 nint(input()) # 每日打…...
Python编程题汇总
Python编程复习 1.1找出列表中单词最长的一个 找出列表中单词最长的一个def test():a ["hello", "world", "yoyo", "congratulations"]length len(a[0])# 在列表中循环for i in a:if len(i) > length:length ireturn length p…...
Matplotlib详解
视频教程 1.什么是matplotlib matplotlib: 最流行的Python底层绘图库,主要做数据可视化图表,名字取材于MATLAB,模仿MATLAB构建 2.样例 2.1折线图 eg:假设一天中每隔两个小时(range(2,26,2))的气温(℃)分别是[15,13,14.5,17,20,25,26,26,…...

Jetson AGX Orin安装Anaconda、Cuda、Cudnn、Pytorch、Tensorrt最全教程
文章目录一:Anaconda安装二:Cuda、Cudnn安装三:Pytorch安装四:Tensorrt安装一:Anaconda安装 Jetson系列边缘开发板,其架构都是arm64,而不是传统PC的amd64,深度学习的环境配置方法大…...
pytorch入门篇2 玩转tensor(查看、提取、变换)
上一篇博客讲述了如何根据自己的实际需要在pytorch中创建tensor:pytorch入门篇1——创建tensor,这一篇主要来探讨关于tensor的基本数据变换,是pytorch处理数据的基本方法。 文章目录1 tensor数据查看与提取2 tensor数据变换2.1 重置tensor形状…...

随机森林算法
随机森林1.1定义1.2随机森林的随机性体现的方面1.3 随机森林的重要作用1.4 随机森林的构建过程1.5 随机森林的优缺点2. 随机森林参数描述3. 分类随机森林的代码实现1.1定义 随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法。随机森林非常简单&am…...
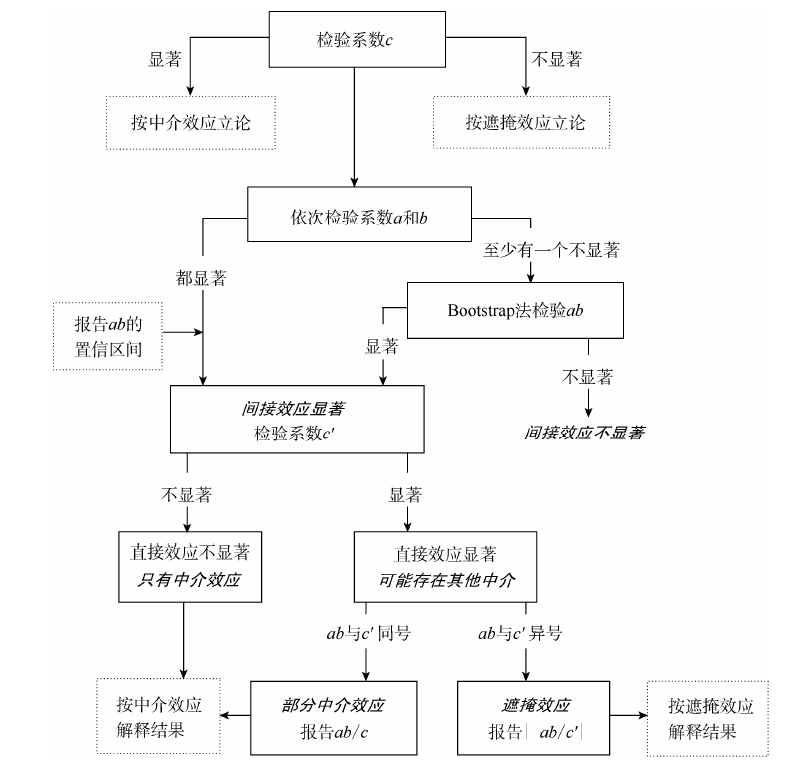
实证分析 | 中介效应检验原理与Stata代码实现
前言 本文是温忠鳞和叶宝娟2014年刊载于《心理科学进展》的论文《中介效应分析:方法和模型发展》的简要笔记与拓展。 温忠麟、叶宝娟:《中介效应分析:方法和模型发展》,《心理科学进展》,2014年第5期 中介效应检验 要…...

几个代码画出漂亮的词云图,python最简单的词云图教程(建议收藏)
在开始编写程序之前,我们先了解一下词云图的作用,我们拿到一篇文章,想得到一些关键词,但文章篇幅很大,无法短时间得到关键词,这时我们可以通过程序将文章中的每个词组识别出来,统计每个词组出现…...

mac m1,m2 安装 提供GPU支持的pytorch和tensorflow
mac m1,m2 安装 提供GPU支持的pytorch和tensorflowAnaconda安装测试Pytorch参考链接安装步骤安装 Xcode创建conda环境测试加速效果注意Tensorflow参考链接安装步骤安装 Xcode指定安装环境加速效果测试The Endmac m1 刚出的时候,各种支持都不完善。那时候要使用conda…...
如何用Python优雅的合并两个Dict
假设有两个dict x和y,合并成一个新的dict,不改变 x和y的值,例如 x {a: 1, b: 2}y {b: 3, c: 4} 期望得到一个新的结果Z,如果key相同,则y覆盖x。期望的结果是 >>> z {a: 1, b: 3, c: 4} 在PEP448中ÿ…...
python读取文件的几种方式
下面是不同场景较为合适的数据读取方法: 1.python内置方法(read、readline、readlines) 纯文本格式或非格式化、非结构化的数据,常用语自然语言处理、非结构文本解析、应用正则表达式等后续应用场景下,Python默认的三…...

python常用模块大全
目录 时间模块time() 与 datetime()random()模块os模块sys模块tarfile用于将文件夹归档成 .tar的文件shutil 创建压缩包,复制,移动文件zipfile将文件或文件夹进行压缩 shelve 模块 json和pickle序列化hashlib 模块subprocess 模块re模块 时间模块time() 与 datetime() time()模…...

成本降低90%,OpenAI正式开放ChαtGΡΤ
今天凌晨,OpenAI官方发布ChαtGΡΤ和Whisper的接囗,开发人员现在可以通过API使用最新的文本生成和语音转文本功能。OpenAI称:通过一系列系统级优化,自去年12月以来,ChαtGΡΤ的成本降低了90%;现在OpenAI用…...

Python:ModuleNotFoundError错误解决
前言: 大家都知道python项目中需要导入各种包(这里的包引鉴于java中的),官话来讲就是Module。 而什么又是Module呢,通俗来讲就是一个模块,当然模块这个意思百度搜索一下都能出来,Python 模块(…...
python案例——利用python画图
1、画直线 问题描述: 利用python中的 turtle (海龟绘图)模块提供的函数绘制直线 算法设计: turtle.penup(): 画笔抬起turtle.color(): 设置颜色turtle.goto(): 画笔移动到下一目标turtle.pendown(): …...

pandas.DataFrame设置某一行为表头(列索引),设置某一列为行索引,按索引取多行多列
pandas读取文件 pandas.DataFrame 设置索引 pandas.DataFrame 读取单行/列,多行多列 pandas.DataFrame 添加行/列 利用pandas处理表格类型数据,快捷方便,不常用但是有的时候又是必要技能,在这里记录一下一些常用函数和自己的踩坑…...

主成分分析(PCA)算法模型实现及分析(MATLAB实现)PCA降维
主成分分析(PCA)算法模型实现及分析(源码在文章后附录)1 引言2 关于PCA原理和算法实现2.1 PCA基本原理2.2 协方差计算2.3 PCA实现步骤 (1)PCA算法实现步骤 (2)基于特征值分解协…...

python 识别图片验证码/滑块验证码准确率极高的 ddddocr 库
前言 验证码的种类有很多,它是常用的一种反爬手段,包括:图片验证码,滑块验证码,等一些常见的验证码场景。 识别验证码的python 库有很多,用起来也并不简单,这里推荐一个简单实用的识别验证码的…...
华为OD机试 - 称砝码(Java JS Python)
题目描述 现有n种砝码,重量互不相等,分别为 m1,m2,m3…mn ; 每种砝码对应的数量为 x1,x2,x3...xn 。现在要用这些砝码去称物体的重量(放在同一侧),问能称出多少种不同的重量。 输入描述 对于每组测试数据: 第一行:n --- 砝码的种数(范围[1,10]) 第二行:m1 m2 m3 ... m…...

DataFrame转化为json的方法教程
网络上有好多的教程,讲得不太清楚和明白,我用实际的例子说明了一下内容,附档代码,方便理解和使用 DataFrame.to_json(path_or_bufNone, orientNone, date_formatNone, double_precision10, force_asciiTrue, date_unitms, defau…...
requests库的使用(一篇就够了)
urllib库使用繁琐,比如处理网页验证和Cookies时,需要编写Opener和Handler来处理。为了更加方便的实现这些操作,就有了更为强大的requests库。 request库的安装 requests属于第三方库,Python不内置,因此需要我们手动…...
Pytorch+PyG实现MLP
文章目录前言一、导入相关库二、加载Cora数据集三、定义MLP网络四、定义模型五、模型训练六、模型验证七、结果完整代码前言 大家好,我是阿光。 本专栏整理了《图神经网络代码实战》,内包含了不同图神经网络的相关代码实现(PyG以及自实现&a…...
PYcharm怎么用,一篇教会你
文章目录一、界面介绍二、设置中文(无需汉化包)三、常用快捷键四、Python 标识符和关键字1、标识符2、 关键字五、行和缩进六、Python 引号七、Python注释1、单行注释2、多行注释八、Python空行九、输入和输出1、print 输出2、input 输入十、多行语句一、…...
如何在pycharm中使用anaconda的虚拟环境
最近项目中有许多同学咨询如何在pycharm中使用anaconda的虚拟环境(envs),这里就给大家简单介绍一下。 首先我们需要安装anaconda,这里就不在追述了,网上安装教程非常多。anaconda的安装路径大家需要记着因为后面会使用…...
Pytorch环境安装+Pycharm环境安装
我的配置: CUDA版本:11.7 Pytorch版本:1.13.0 Anaconda版本:anaconda3.2022.10(64-bit) Pycharm版本:2022社区版 具体配置过程如下: 1.Anaconda安装 本次安装的anaconda为win6…...
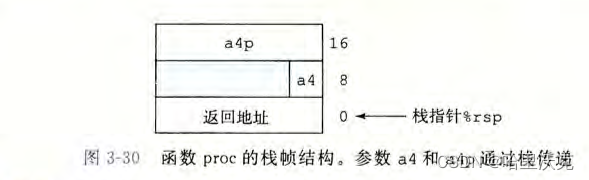
csapp第三章(2) --- 程序的机器级表示
csapp第三章(1) --- 程序的机器级表示https://blog.csdn.net/m0_63488627/article/details/129470787?spm1001.2014.3001.5501本章大纲 目录 3.4.过程 3.4.1运行中的栈 3.4.2转移控制 3.4.3数据传送 3.4.4栈上的局部存储 3.4.5栈的递归实现 3.5.数组分配和访问 3.6结…...
使用Ananconda进行Pytorch配置
为什么选择pytorch: 活跃度:逐渐形成了完整的开发生态,资源多。动态图:动态图架构,且运行速度较快。代码简洁:易于理解,设计优雅,易于调试。 可能有的疑惑: 深度学习框架太多不知道…...

python实现定时任务的8种方式详解
在日常工作中,常常会用到需要周期性执行的任务,一种方式是采用 Linux 系统自带的 crond 结合命令行实现。另外一种方式是直接使用Python。 当每隔一段时间就要执行一段程序,或者往复循环执行某一个任务,这就需要使用定时任…...
强大的数据分析工具——Pandas操作、易错点、知识点三万字详解
一、 Pandas数据结构 1.Series 2.DataFrame 3.从DataFrame中查询出Series DataFrame: 二维数据、整个表格、多行多列 Series:一维数据,一行或者一列 import pandas as pd import numpy as np 1、Series Series是一种类似于一维数组的对象,它由一组数…...

第一章 使用 matplotlib 绘制折线图
系列文章目录 第一章 使用 matplotlib 绘制折线图 第二章 使用 matplotlib 绘制条形图 第三章 使用 matplotlib 绘制直方图 第四章 使用 matplotlib 绘制散点图 第五章 使用 matplotlib 绘制饼图 第六章 使用 matplotlib 绘制热力图 第七章 使用 matplotlib 绘制堆叠条形图 第…...
jupyter notebook运行代码没反应且in[ ]没有*
前言: 在刚解决jupyter notebook打不开网页的问题后,我迫不及待地写了Python的代码,看看运行的结果如何。于是,我输入了print("Hello, world"),期待地点了一下运行,结果它直接跳到下一行了......…...

(超详细)python环境安装
耀风也是python初学者,文章可能会有不严谨的地方,如有发现希望帮我指正 1.python环境的安装 (1)为什么要安装python环境? python是一个解释性语言,所谓解释性语言就是代码不会进行预编译,而是…...
matplotlib绘图设置刻度线朝内、不显示刻度等常用代码
文章内容设置刻度线朝里坐标轴不显示刻度设置x轴0刻度从y轴开始绘制直线x某个值设置刻度线朝里 plt.rcParams[‘xtick.direction’] ‘in’ # 将x轴的刻度线方向设置向内 plt.rcParams[‘ytick.direction’] ‘in’ # 将y轴的刻度线方向设置向内 坐标轴不显示刻度 plt.xti…...
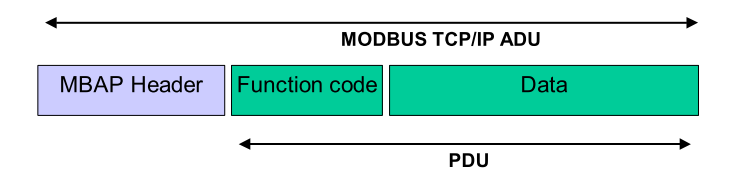
用Python实现ModbusTcp协议
用Python实现ModbusTcp协议 去年2021年写了两篇用Python实现Modbus-RTU串行通信协议的文章,今年有个项目用现场上位计算机通过ModbusTcp网关来读写现场的Modbus-RTU协议的仪表设备和IO设备。我则写了一个Python程序来测试采购的这台ModbusTcp网关设备。 首先是需要设…...

python绘制混淆矩阵
之前就了解过混淆矩阵,但是一直没有实践,今天刚好有数据实践一下,这里记录一下代码实现过程,方便以后查阅。 python绘制混淆矩阵matplotlib实现sklearn实现sklearn.metrics.ConfusionMatrixDisplayfrom_estimatorfrom_predictions…...
如何快速下载Python解决在官网下载缓慢问题以及如何安装Python
不知道你们碰到过这样的情况没有,在Python官网下载Python却很慢,刚开始我还以为是被限速了,后来才了解到这是因为Python官网的服务器是在外网,所以呢那我找到了一个Python的国内下载网址:CNPM Binaries Mirror (npmmir…...
FPN网络详解
1 特征金字塔 特征金字塔(Feature Pyramid Networks, FPN)的基本思想是通过构造一系列不同尺度的图像或特征图进行模型训练和测试,目的是提升检测算法对于不同尺寸检测目标的鲁棒性。但如果直接根据原始的定义进行FPN计算,会带来大额的计算开…...

python操作Excel
前言: Python操作Excel需要三方库的支持,如果要兼容Excel 2007以前的版本,也就是xls格式的Excel文件,可以使用三方库xlrd和xlwt,前者用于读Excel文件,后者用于写Excel文件。如果使用较新版本的Excel&#…...

Anaconda内安装OpenCV最有效的方法
问题背景: 如果你试过在Anaconda内安装opencv的诸多方法都不奏效,那么本文的这个方法可以从根本上解决这个问题。 安装准备: 在Anaconda3内的python建议为3.6版本,安装的opencv最好为对应的3.4.1.15版本,安装的open…...
Python你绝对不知道的15个小技巧,知道的算我输
名字:阿玥的小东东 学习:Python语言、正在学习c++语言 主页:阿玥的小东东 目录 前言 1.all or any 2.bashplotlib 3.collections 4.dir 5.from __future__ import...