联邦学习开山之作代码解读与收获
参考:联邦学习代码解读,超详细_一只揪°的博客-CSDN博客_联邦学习代码
参考文献:[1602.05629] Communication-Efficient Learning of Deep Networks from Decentralized Data (arxiv.org)
参考代码:GitHub - AshwinRJ/Federated-Learning-PyTorch: Implementation of Communication-Efficient Learning of Deep Networks from Decentralized Data
今天尝试阅读开山之作的代码。
目录
一、加载参数——options.py
二、数据IID和非IID采样——sampling.py
1.mnist_iid()
2.mnist_noniid()
3.mnist_noniid()
4.cifar_iid()、cifar_noniid()
三、本地模型参数更新——update.py
1.DatasetSplit(Dataset)
2.LocalUpdate(object)
3.test_inference(self,model)
四、应用集——utils.py
1.get_dataset(args)
2.average_weights(w)
3.exp_details(args)
五、模型设置——models.py
1.MLP多层感知机模型
2.CNN卷积神经网络
3.自创模型
六、主函数——federated_main.py
七、作图
八、个人总结
一、加载参数——options.py
import argparse
def args_parser():
parser = argparse.ArgumentParser()
# federated arguments (Notation for the arguments followed from paper)
parser.add_argument('--epochs', type=int, default=10,
help="number of rounds of training")
parser.add_argument('--num_users', type=int, default=100,
help="number of users: K")
parser.add_argument('--frac', type=float, default=0.1,
help='the fraction of clients: C')
parser.add_argument('--local_ep', type=int, default=10,
help="the number of local epochs: E")
parser.add_argument('--local_bs', type=int, default=10,
help="local batch size: B")
parser.add_argument('--lr', type=float, default=0.01,
help='learning rate')
parser.add_argument('--momentum', type=float, default=0.5,
help='SGD momentum (default: 0.5)')
# model arguments
parser.add_argument('--model', type=str, default='mlp', help='model name')
parser.add_argument('--kernel_num', type=int, default=9,
help='number of each kind of kernel')
parser.add_argument('--kernel_sizes', type=str, default='3,4,5',
help='comma-separated kernel size to \
use for convolution')
parser.add_argument('--num_channels', type=int, default=1, help="number \
of channels of imgs")
parser.add_argument('--norm', type=str, default='batch_norm',
help="batch_norm, layer_norm, or None")
parser.add_argument('--num_filters', type=int, default=32,
help="number of filters for conv nets -- 32 for \
mini-imagenet, 64 for omiglot.")
parser.add_argument('--max_pool', type=str, default='True',
help="Whether use max pooling rather than \
strided convolutions")
# other arguments
parser.add_argument('--dataset', type=str, default='mnist', help="name \
of dataset")
parser.add_argument('--num_classes', type=int, default=10, help="number \
of classes")
parser.add_argument('--gpu', default=None, help="To use cuda, set \
to a specific GPU ID. Default set to use CPU.")
parser.add_argument('--optimizer', type=str, default='sgd', help="type \
of optimizer")
parser.add_argument('--iid', type=int, default=1,
help='Default set to IID. Set to 0 for non-IID.')
parser.add_argument('--unequal', type=int, default=0,
help='whether to use unequal data splits for \
non-i.i.d setting (use 0 for equal splits)')
parser.add_argument('--stopping_rounds', type=int, default=10,
help='rounds of early stopping')
parser.add_argument('--verbose', type=int, default=1, help='verbose')
parser.add_argument('--seed', type=int, default=1, help='random seed')
args = parser.parse_args()
return args这里使用argparse输入了三类参数,分别是联邦参数,模型参数,其他参数。其中联邦参数:
- epochs:训练轮数,10
- num_users:用户数量K,默认100
- frac:用户选取比例C,默认0.1
- local_ep:本地训练数量E,默认10
- local_bs:本地训练批量B,默认10
- lr:学习率,默认0.01
- momentum:SGD动量(为什么SGD有动量?),默认0.5
模型参数:
- model:模型名称,默认mlp,即全连接神经网络
- kernel_num:卷积核数量,默认9个
- kernel_sizes:卷积核大小,默认3,4,5
- num_channels:图像通道数,默认1
- norm:归一化方式,可以是BN和LN
- num_filters:过滤器数量,默认32
- max_pool:最大池化,默认为True
其他设置:
- dataset:选择什么数据集,默认mnist
- num_class:分类数量,默认10
- gpu:默认使用,可以填入具体cuda编号
- optimizer:优化器,默认是SGD算法
- iid:独立同分布,默认是1,即是独立同分布
- unequal:是否平均分配数据集,默认0,即是
- stopping_rounds:停止轮数,默认是10
- verbose:日志显示,0不输出,1输出带进度条的日志,2输出不带进度条的日志
- seed: 随机数种子,默认1
最后args_parser()函数会返回args,里面包含了控制台输入的参数。
二、数据IID和非IID采样——sampling.py
这个文件从mnist和cifar-10采集IID和非IID的数据。
1.mnist_iid()
def mnist_iid(dataset, num_users):
"""
Sample I.I.D. client data from MNIST dataset
:param dataset:
:param num_users:
:return: dict of image index
"""
num_items = int(len(dataset)/num_users)
dict_users, all_idxs = {}, [i for i in range(len(dataset))]
for i in range(num_users):
dict_users[i] = set(np.random.choice(all_idxs, num_items,
replace=False))
all_idxs = list(set(all_idxs) - dict_users[i])
return dict_users随机给100个用户选600个随机的样本。
2.mnist_noniid()
def mnist_noniid(dataset, num_users):
"""
Sample non-I.I.D client data from MNIST dataset
:param dataset:
:param num_users:
:return:
"""
# 60,000 training imgs --> 200 imgs/shard X 300 shards
num_shards, num_imgs = 200, 300
idx_shard = [i for i in range(num_shards)]
dict_users = {i: np.array([]) for i in range(num_users)}
idxs = np.arange(num_shards*num_imgs)
labels = dataset.train_labels.numpy()
# sort labels
idxs_labels = np.vstack((idxs, labels))
idxs_labels = idxs_labels[:, idxs_labels[1, :].argsort()]
idxs = idxs_labels[0, :]
# divide and assign 2 shards/client
for i in range(num_users):
rand_set = set(np.random.choice(idx_shard, 2, replace=False))
idx_shard = list(set(idx_shard) - rand_set)
for rand in rand_set:
dict_users[i] = np.concatenate(
(dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]), axis=0)
return dict_users- num_shards:把60000个训练集图片分为200份
- [i for i in range()]:可以生成一个递增list
- {i: np.array([]) for i in range(num_users)}:以大括号生成100个用户的字典
- np.vstack((idxs, labels)):把编号和标签堆叠起来,形成一个(2,60000)的数组
- idxs_labels = idxs_labels[:, idxs_labels[1, :].argsort()]:argsort函数的作用是,输出数组中的元素从小到大排序后的索引数组值
经过筛选之后,获得了由小到大的标签索引idxs。然后进行用户分片。
- np.random.choice():从切片序号中选出两个序号,replace参数表示不放回取样
- idxs[rand*num_imgs:(rand+1)*num_imgs]:取连续的300个排序后的索引号
- np.concatenate():从哪个维度拼哪个维度就会增加,这里从200个索引号中随机选取了两个随机数,把这两个随机数对应位置的数据给连起来了
最后函数返回了每个用户以及所对应的600个数据的字典。
3.mnist_noniid()
def mnist_noniid_unequal(dataset, num_users):
"""
Sample non-I.I.D client data from MNIST dataset s.t clients
have unequal amount of data
:param dataset:
:param num_users:
:returns a dict of clients with each clients assigned certain
number of training imgs
"""有点长,我分着说。把60000张数据分为1200份:
# 60,000 training imgs --> 50 imgs/shard X 1200 shards
num_shards, num_imgs = 1200, 50
idx_shard = [i for i in range(num_shards)]
dict_users = {i: np.array([]) for i in range(num_users)}
idxs = np.arange(num_shards*num_imgs)
labels = dataset.train_labels.numpy()获得排序后的索引号:
# sort labels
idxs_labels = np.vstack((idxs, labels))
idxs_labels = idxs_labels[:, idxs_labels[1, :].argsort()]
idxs = idxs_labels[0, :]设置每个用户所持有的数据份数范围:
# Minimum and maximum shards assigned per client:
min_shard = 1
max_shard = 30也就是说,每个用户至少拥有1×50=50张图片,至多拥有30*50=1500张图片。
接下来要把这1200份分给这些用户,并且保证每个用户至少被分到一个数据,且每个数据都要被分到。
# Divide the shards into random chunks for every client
# s.t the sum of these chunks = num_shards
random_shard_size = np.random.randint(min_shard, max_shard+1,
size=num_users)
random_shard_size = np.around(random_shard_size /
sum(random_shard_size) * num_shards)
random_shard_size = random_shard_size.astype(int)- np.random.randint:返回为一个前闭后开的区间的列表,长度为用户数量
- np.around:四舍六入,五归偶数
经过这一步,所有的份数都被等比地调整,使其总和接近于为1200。(因为有小数被四舍六入,所以不严格等于1200)所以接下来就要针对这不严格的部分进行调整和分配。
# Assign the shards randomly to each client
if sum(random_shard_size) > num_shards:
for i in range(num_users):
# First assign each client 1 shard to ensure every client has
# atleast one shard of data
rand_set = set(np.random.choice(idx_shard, 1, replace=False))
idx_shard = list(set(idx_shard) - rand_set)
for rand in rand_set:
dict_users[i] = np.concatenate(
(dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]),
axis=0)
random_shard_size = random_shard_size-1
# Next, randomly assign the remaining shards
for i in range(num_users):
if len(idx_shard) == 0:
continue
shard_size = random_shard_size[i]
if shard_size > len(idx_shard):
shard_size = len(idx_shard)
rand_set = set(np.random.choice(idx_shard, shard_size,
replace=False))
idx_shard = list(set(idx_shard) - rand_set)
for rand in rand_set:
dict_users[i] = np.concatenate(
(dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]),
axis=0)
else:
for i in range(num_users):
shard_size = random_shard_size[i]
rand_set = set(np.random.choice(idx_shard, shard_size,
replace=False))
idx_shard = list(set(idx_shard) - rand_set)
for rand in rand_set:
dict_users[i] = np.concatenate(
(dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]),
axis=0)
if len(idx_shard) > 0:
# Add the leftover shards to the client with minimum images:
shard_size = len(idx_shard)
# Add the remaining shard to the client with lowest data
k = min(dict_users, key=lambda x: len(dict_users.get(x)))
rand_set = set(np.random.choice(idx_shard, shard_size,
replace=False))
idx_shard = list(set(idx_shard) - rand_set)
for rand in rand_set:
dict_users[k] = np.concatenate(
(dict_users[k], idxs[rand*num_imgs:(rand+1)*num_imgs]),
axis=0)
return dict_users最后会获得随机分配的用户持有的非IID数据的索引字典.。
4.cifar_iid()、cifar_noniid()
没有区别,不写了
三、本地模型参数更新——update.py
1.DatasetSplit(Dataset)
先来看看Dataset类的官方解释:Dataset可以是任何东西,但它始终包含一个__len__函数(通过Python中的标准函数len调用)和一个用来索引到内容中的__getitem__函数。
class DatasetSplit(Dataset):
"""An abstract Dataset class wrapped around Pytorch Dataset class.
"""
def __init__(self, dataset, idxs):
self.dataset = dataset
self.idxs = [int(i) for i in idxs]
def __len__(self):
return len(self.idxs)
def __getitem__(self, item):
image, label = self.dataset[self.idxs[item]]
return torch.tensor(image), torch.tensor(label)这部分代码重写了Dataset类:
- 重写了__len__(self)方法,返回数据列表长度,即数据集的样本数量
- 重写了__getitem__(self,item)方法,获取image和label的张量
2.LocalUpdate(object)
这是本地更新模型的代码,有点多我分着说:
class LocalUpdate(object):...首先是构造函数,首先定义了参数和日志,然后从train_val_test()函数获取了数据加载器,随后指定了运算设备。
比较重要的是这里的损失函数是NLL损失函数,它跟交叉熵相似,唯一的区别在于NLL的log里面对结果进行了一次Softmax。
def __init__(self, args, dataset, idxs, logger):
self.args = args
self.logger = logger
self.trainloader, self.validloader, self.testloader = self.train_val_test(
dataset, list(idxs))
self.device = 'cuda' if args.gpu else 'cpu'
# Default criterion set to NLL loss function
self.criterion = nn.NLLLoss().to(self.device)接下来是train_val_test()函数,它用来分割数据集。输入数据集和索引,按照8:1:1来划分。注意到在指定batchsize的时候,除了训练集是从args参数里指定的,val和test都是取了总数的十分之一。
def train_val_test(self, dataset, idxs):
"""
Returns train, validation and test dataloaders for a given dataset
and user indexes.
"""
# split indexes for train, validation, and test (80, 10, 10)
idxs_train = idxs[:int(0.8*len(idxs))]
idxs_val = idxs[int(0.8*len(idxs)):int(0.9*len(idxs))]
idxs_test = idxs[int(0.9*len(idxs)):]
trainloader = DataLoader(DatasetSplit(dataset, idxs_train),
batch_size=self.args.local_bs, shuffle=True)
validloader = DataLoader(DatasetSplit(dataset, idxs_val),
batch_size=int(len(idxs_val)/10), shuffle=False)
testloader = DataLoader(DatasetSplit(dataset, idxs_test),
batch_size=int(len(idxs_test)/10), shuffle=False)
return trainloader, validloader, testloader接下来是本地权重更新函数,输入模型和全局更新的回合数,输出更新后的权重和损失平均值。首先选择了优化器,然后开始训练循环。
def update_weights(self, model, global_round):
# Set mode to train model
model.train()
epoch_loss = []
# Set optimizer for the local updates
if self.args.optimizer == 'sgd':
optimizer = torch.optim.SGD(model.parameters(), lr=self.args.lr,
momentum=0.5)
elif self.args.optimizer == 'adam':
optimizer = torch.optim.Adam(model.parameters(), lr=self.args.lr,
weight_decay=1e-4)
for iter in range(self.args.local_ep):
batch_loss = []
for batch_idx, (images, labels) in enumerate(self.trainloader):
images, labels = images.to(self.device), labels.to(self.device)
model.zero_grad()
log_probs = model(images)
loss = self.criterion(log_probs, labels)
loss.backward()
optimizer.step()
if self.args.verbose and (batch_idx % 10 == 0):
print('| Global Round : {} | Local Epoch : {} | [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
global_round, iter, batch_idx * len(images),
len(self.trainloader.dataset),
100. * batch_idx / len(self.trainloader), loss.item()))
self.logger.add_scalar('loss', loss.item())
batch_loss.append(loss.item())
epoch_loss.append(sum(batch_loss)/len(batch_loss))
return model.state_dict(), sum(epoch_loss) / len(epoch_loss)- self.logger.add_scalar('loss', loss.item()):这个函数是用来保存程序中的数据,然后利用tensorboard工具来进行可视化的
- 每经过一次本地轮次,统计当前的loss,用于最后的平均损失统计
- model.state_dict():是Pytorch中用于查看网络参数的方法,可以用torch.save()保存成pth文件
接下来是评估函数:inference(self,model)。输入为模型,计算准确值、loss值,这里的代码很有参考意义:
def inference(self, model):
""" Returns the inference accuracy and loss.
"""
model.eval()
loss, total, correct = 0.0, 0.0, 0.0
for batch_idx, (images, labels) in enumerate(self.testloader):
images, labels = images.to(self.device), labels.to(self.device)
# Inference
outputs = model(images)
batch_loss = self.criterion(outputs, labels)
loss += batch_loss.item()
# Prediction
_, pred_labels = torch.max(outputs, 1)
pred_labels = pred_labels.view(-1)
correct += torch.sum(torch.eq(pred_labels, labels)).item()
total += len(labels)
accuracy = correct/total
return accuracy, loss- model.eval():开启模型的评估模式
- torch.max():第二个参数指维度,即返回第1维度(即行),这里返回了虽大数值的索引
- pred_labels.view(-1):本意是根据另外一个数来自动调整维度,但是这里只有一个维度,因此就会将X里面的所有维度数据转化成一维的,并且按先后顺序排列。
- torch.eq():对两个张量Tensor进行逐元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回False。
这里的函数通取测试集图像和标签,模型出结果后计算loss然后累加,
3.test_inference(self,model)
与LocalUpdate中的inference函数完全一致,只不过这里的输入参数除了args和model,还要指定test_dataset:
def test_inference(args, model, test_dataset):
""" Returns the test accuracy and loss.
"""
model.eval()
loss, total, correct = 0.0, 0.0, 0.0
device = 'cuda' if args.gpu else 'cpu'
criterion = nn.NLLLoss().to(device)
testloader = DataLoader(test_dataset, batch_size=128,
shuffle=False)
for batch_idx, (images, labels) in enumerate(testloader):
images, labels = images.to(device), labels.to(device)
# Inference
outputs = model(images)
batch_loss = criterion(outputs, labels)
loss += batch_loss.item()
# Prediction
_, pred_labels = torch.max(outputs, 1)
pred_labels = pred_labels.view(-1)
correct += torch.sum(torch.eq(pred_labels, labels)).item()
total += len(labels)
accuracy = correct/total
return accuracy, loss四、应用集——utils.py
这里面封装了一些工具函数:get_dataset(),average_weights(),exp_details()
1.get_dataset(args)
get_dataset(args)根据命令台参数获取相应的数据集和用户数据字典。就是个if else,有点简单就不说了。
2.average_weights(w)
返回权重的平均值,即执行联邦平均算法:
def average_weights(w):
"""
Returns the average of the weights.
"""
w_avg = copy.deepcopy(w[0])
for key in w_avg.keys():
for i in range(1, len(w)):
w_avg[key] += w[i][key]
w_avg[key] = torch.div(w_avg[key], len(w))
return w_avg- w:这个w是经过多轮本地训练后统计的权重list,在参数默认的情况下,是一个长度为10的列表,而每个元素都是一个字典,每个字典都包含了模型参数的名称(比如layer_input.weight或者layer_hidden.bias),以及其权重具体的值。
- copy.deepcopy():深度复制,被复制的对象不会随着复制的对象的改变而改变。这里复制了第一个用户的权重字典。
随后,对于每一类参数进行循环,累加每个用户模型里对应参数的值,最后取平均获得平均后的模型。
3.exp_details(args)
可视化命令台参数args:
def exp_details(args):
print('\nExperimental details:')
print(f' Model : {args.model}')
print(f' Optimizer : {args.optimizer}')
print(f' Learning : {args.lr}')
print(f' Global Rounds : {args.epochs}\n')
print(' Federated parameters:')
if args.iid:
print(' IID')
else:
print(' Non-IID')
print(f' Fraction of users : {args.frac}')
print(f' Local Batch size : {args.local_bs}')
print(f' Local Epochs : {args.local_ep}\n')
return五、模型设置——models.py
这个文件设置了一些比较常见的网络模型
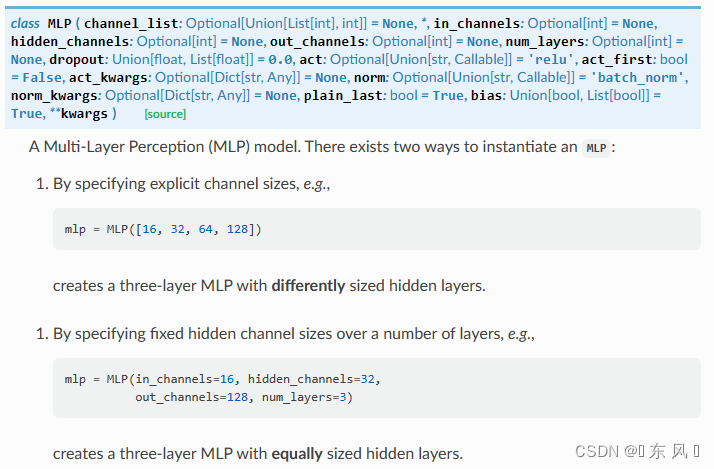
1.MLP多层感知机模型
class MLP(nn.Module):
def __init__(self, dim_in, dim_hidden, dim_out):
super(MLP, self).__init__()
self.layer_input = nn.Linear(dim_in, dim_hidden)
self.relu = nn.ReLU()
self.dropout = nn.Dropout()
self.layer_hidden = nn.Linear(dim_hidden, dim_out)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = x.view(-1, x.shape[1]*x.shape[-2]*x.shape[-1])
x = self.layer_input(x)
x = self.dropout(x)
x = self.relu(x)
x = self.layer_hidden(x)
return self.softmax(x)- nn.Dropout():你懂得,不懂就搜
2.CNN卷积神经网络
太多了不予展示。
3.自创模型
这里原代码是modelC,其构造函数下,super第一个参数是AllConvNet,在编译器中会报错。但是这里并非打错,而是让用户自定义。
六、主函数——federated_main.py
(这里我贴的代码是我更改了注释的)
首先是库的引用:
import os
import copy
import time
import pickle
import numpy as np
from tqdm import tqdm
import torch
from tensorboardX import SummaryWriter
from options import args_parser
from update import LocalUpdate, test_inference
from models import MLP, CNNMnist, CNNFashion_Mnist, CNNCifar
from utils import get_dataset, average_weights, exp_details随后直接开始主函数:
if __name__ == '__main__':
start_time = time.time()
# 定义路径
path_project = os.path.abspath('..') # 上级目录的绝对路径
logger = SummaryWriter('../logs') # python可视化工具
args = args_parser() # 输入命令行参数
exp_details(args) # 显示命令行参数情况由于是调试状态运行,所以没有更改参数,参数情况如下所示:
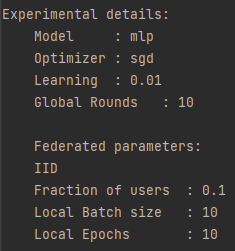
接下来加载数据集和用户数据字典:
# 判断GPU是否可用:
if args.gpu:
torch.cuda.set_device(args.gpu)
device = 'cuda' if args.gpu else 'cpu'
# 加载数据集,用户本地数据字典
train_dataset, test_dataset, user_groups = get_dataset(args)这里会返回60000的训练集,10000的测试集,以及长度为100的用户字典,用户字典是100个用户到各自600个IID训练数据的映射。
然后开始建立模型,这里模型选择的是多层感知机:
# 建立模型
if args.model == 'cnn':
# 卷积神经网络
if args.dataset == 'mnist':
global_model = CNNMnist(args=args)
elif args.dataset == 'fmnist':
global_model = CNNFashion_Mnist(args=args)
elif args.dataset == 'cifar':
global_model = CNNCifar(args=args)
elif args.model == 'mlp':
# 多层感知机
img_size = train_dataset[0][0].shape
len_in = 1
for x in img_size:
len_in *= x
global_model = MLP(dim_in=len_in, dim_hidden=64,
dim_out=args.num_classes)
else:
exit('Error: unrecognized model')接下来就是设置模型进行第一轮训练,并复制权重:
# 设置模型进行训练,并传输给计算设备
global_model.to(device)
global_model.train()
print(global_model)
# 复制权重
global_weights = global_model.state_dict()模型如下所示:
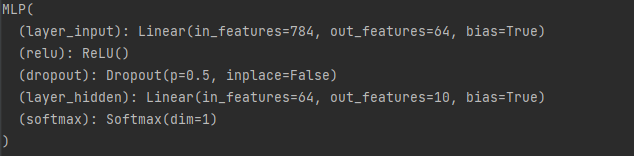
这是一个输入层784个,隐藏层64个,输出层10个的多层感知机,且设置了0.5的Dropout。
然后就开始正式训练:
# 训练
train_loss, train_accuracy = [], []
val_acc_list, net_list = [], []
cv_loss, cv_acc = [], []
print_every = 2
val_loss_pre, counter = 0, 0
for epoch in tqdm(range(args.epochs)):
local_weights, local_losses = [], []
print(f'\n | Global Training Round : {epoch + 1} |\n')
global_model.train()
m = max(int(args.frac * args.num_users), 1) # 随机选比例为frac的用户
idxs_users = np.random.choice(range(args.num_users), m, replace=False)
for idx in idxs_users:
local_model = LocalUpdate(args=args, dataset=train_dataset,
idxs=user_groups[idx], logger=logger)
w, loss = local_model.update_weights(
model=copy.deepcopy(global_model), global_round=epoch)
local_weights.append(copy.deepcopy(w))
local_losses.append(copy.deepcopy(loss))
# 联邦平均,更新全局权重
global_weights = average_weights(local_weights)
# 将更新后的全局权重载入模型
global_model.load_state_dict(global_weights)
loss_avg = sum(local_losses) / len(local_losses)
train_loss.append(loss_avg)
# 每轮训练,都要计算所有用户的平均训练精度
list_acc, list_loss = [], []
global_model.eval()
for c in range(args.num_users):
local_model = LocalUpdate(args=args, dataset=train_dataset,
idxs=user_groups[idx], logger=logger)
acc, loss = local_model.inference(model=global_model)
list_acc.append(acc)
list_loss.append(loss)
train_accuracy.append(sum(list_acc) / len(list_acc))
# 每i轮打印全局Loss
if (epoch + 1) % print_every == 0:
print(f' \nAvg Training Stats after {epoch + 1} global rounds:')
print(f'Training Loss : {np.mean(np.array(train_loss))}')
print('Train Accuracy: {:.2f}% \n'.format(100 * train_accuracy[-1]))- 老实说除了train_loss,train_accuracy和print_every之外我都不知道其他的是干嘛的
- tqdm是一个功能强大的进度条,支持在for循环中展示运行时间和进度
- global_model.train():将模型设置为训练模式
- idxs_users:随机选取用户的索引列表,这里来说,用户选取比例为0.1,用户总数100,那么就会随机抽取100×0.1=10个用户参与训练
- 执行本地更新:对于选取的用户执行本地更新,数据集索引由user_groups[idx]获得,并记录更新后的本地参数和损失值
- 联邦平均:把模型参数字典传入更新函数,返回平均后的模型参数字典,再载入到全局模型中
每轮结束都统计所有100个用户的训练精度,每轮都打印全局损失值。

(注意,你跑模型不停滚动的什么Global Round,Local Epoch,那都是update.py里面的调用LocalUpdate类里的update_weights方法形成的,如果不想他这么频繁的滚动,到这个函数底下注释掉即可)
全局训练后,模型在测试集的表现:
# 训练后,测试模型在测试集的表现
test_acc, test_loss = test_inference(args, global_model, test_dataset)
print(f' \n Results after {args.epochs} global rounds of training:')
print("|---- Avg Train Accuracy: {:.2f}%".format(100 * train_accuracy[-1]))
print("|---- Test Accuracy: {:.2f}%".format(100 * test_acc))结果:
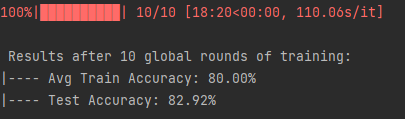
最后就是保存目标训练损失和训练精度了,最后输出时间。
# 保存目标训练损失和训练精度
file_name = '../save/objects/{}_{}_{}_C[{}]_iid[{}]_E[{}]_B[{}].pkl'. \
format(args.dataset, args.model, args.epochs, args.frac, args.iid,
args.local_ep, args.local_bs)
with open(file_name, 'wb') as f:
pickle.dump([train_loss, train_accuracy], f)
print('\n Total Run Time: {0:0.4f}'.format(time.time() - start_time))- pkl文件:pickle.dump(数据,f)为写入,pickle.load(文件名)为读出,这里保存了Loss和Accuracy
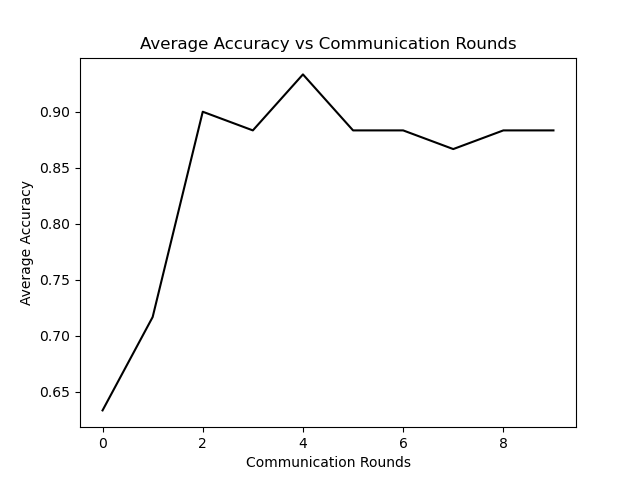
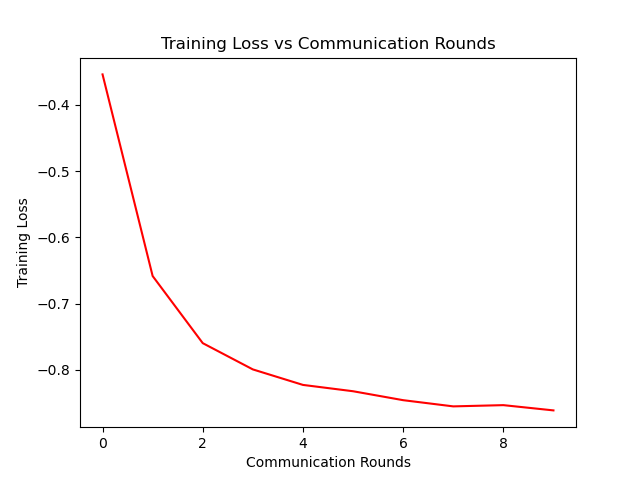
七、作图
在代码的最后,作者用注释写出的作图代码:
# 画图
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use('Agg')
# 绘制损失曲线
plt.figure()
plt.title('训练损失 vs 通信回合数')
plt.plot(range(len(train_loss)), train_loss, color='r')
plt.ylabel('训练损失')
plt.xlabel('通信回合数')
plt.savefig('../save/fed_{}_{}_{}_C[{}]_iid[{}]_E[{}]_B[{}]_loss.png'.
format(args.dataset, args.model, args.epochs, args.frac,
args.iid, args.local_ep, args.local_bs))
# 平均准度曲线
plt.figure()
plt.title('平均准度 vs 通信回合数')
plt.plot(range(len(train_accuracy)), train_accuracy, color='k')
plt.ylabel('平均准度')
plt.xlabel('通信回合数')
plt.savefig('../save/fed_{}_{}_{}_C[{}]_iid[{}]_E[{}]_B[{}]_acc.png'.
format(args.dataset, args.model, args.epochs, args.frac,
args.iid, args.local_ep, args.local_bs))做图如下:
八、个人总结
这次细读代码让我收获良多,包括代码的组织,一些库的应用以及最重要的联邦学习的机理,作者用简单易懂的代码写出了一篇如此有意义的文章,是在敬佩。不但提高了我的码力,也让我正式跨进fl的大门。
相关文章:
Python安装第三方库常用方法 超详细~
Python安装第三方库常用方法前言安装方法1. 通过pychram安装2. pip安装大法3. 下载whl文件到本地离线安装3.1 补充4.其他方法4.1 Python官方的Pypi菜单4.2 国内镜像源解决pip安装过慢的问题小结前言 在pyhton的学习中,相信大家通常都会碰到第三方库的安装问题&…...

Python--找出字符串中出现次数最多的字符及其出现的次数
方法一: 1、循环遍历列表或字符串,如果字符在字典中则值加1,如果不在则创建(key,value) 2、找到字典中,最大的value值 3、根据最大的value值,找对应的key值,打印出出现次数最多的字符 str &qu…...

滤波笔记一:卡尔曼滤波(Kalman Filtering)详解
本笔记是总结了B站DR_CAN的卡尔曼滤波器的课程,他的B站主页为:DR_CAN的个人空间_哔哩哔哩_bilibili PS:虽然我不是学自控的,但是老师真的讲的很好! 目录 Lesson1 递归算法 Lesson2 数学基础_数据融合_协方差矩阵_状态空间方程…...
利用Python求斐波那契数列的第N项以及前N项和(循环、递归、集合)
著名的斐波那契数列,即从第三项开始,每一项都等于前两项之和。 之前写过利用Java语言来编写,由于最近正在学Python,所以将自己的想法记录在此,有需要的朋友可以参考一下。 写在前面:这里的三个方法其实思…...
一文速学(十八)-数据分析之Pandas处理文本数据(str/object)各类操作+代码一文详解(三)
目录 前言 一、子串提取 提取匹配首位子串 提取所有匹配项(extractall)...
Python数据分析-数据预处理
数据预处理 文章目录数据预处理1.前言2.数据探索2.1缺失值分析2.2 异常值分析2.2.1 简单统计量分析2.2.2 3$\sigma$原则2.2.3 箱线图分析2.3 一致性分析2.4 相关性分析3.数据预处理3.1 数据清洗3.1.1 缺失值处理3.1.2 异常值处理3.2 数据集成3.2.1 实体识别3.2.2 冗余属性识别3…...
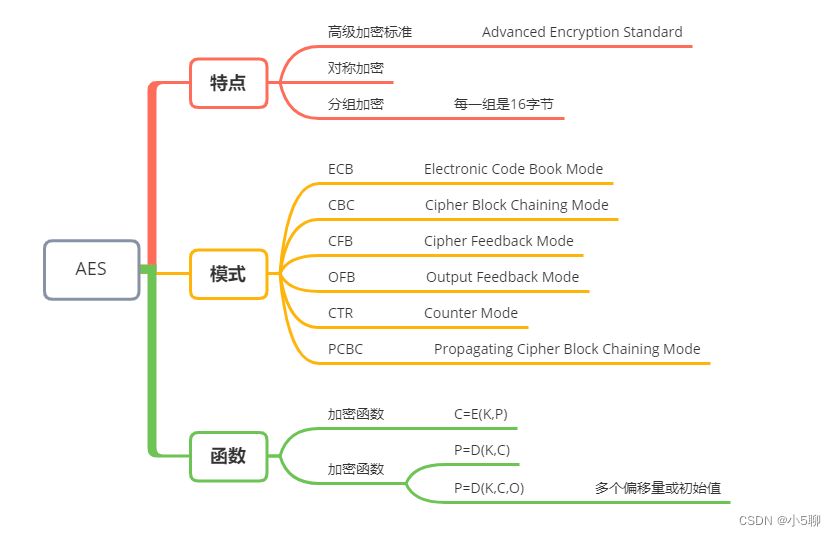
【Python】AES加解密代码,文章还有加密串等你来解密,等你来挑战
🍦🍦写这篇AES文章也是有件趣事,有位小伙伴发了段密文,看看谁解密速度快,学过Python的小伙伴一下子就解开来了,内容也挺有趣的。 🍟🍟原来加解密也可以这么有趣,虽然看起…...
朴素贝叶斯模型及案例(Python)
目录 1 朴素贝叶斯的算法原理 2 一维特征变量下的贝叶斯模型 3 二维特征变量下的贝叶斯模型 4 n维特征变量下的贝叶斯模型 5 朴素贝叶斯模型的sklearn实现 6 案例:肿瘤预测模型 6.1 读取数据与划分 6.1.1 读取数据 6.1.2 划分特征变量和目标变量 6.2 模型…...
python之Tkinter详解
Python之Tkinter详解 文章目录Python之Tkinter详解1、Tkinter是什么2、Tkinter创建窗口①导入 tkinter的库 ,创建并显示窗口②修改窗口属性③创建按钮④窗口内的组件布局3、Tkinter布局用法①基本界面、label(标签)和button(按钮)用法②entry(输入)和text(文本)用法…...

【python】python进行debug操作
文章目录前言一、debug环境介绍二、debug按钮介绍2.1、step into:单步执行(遇到函数也是单步)2.2、step over:单步执行(遇到函数,全部运行)2.3、step into my code:(直接跳到下一个断点)2.4、st…...

Python安装tensorflow过程中出现“No matching distribution found for tensorflow”的解决办法
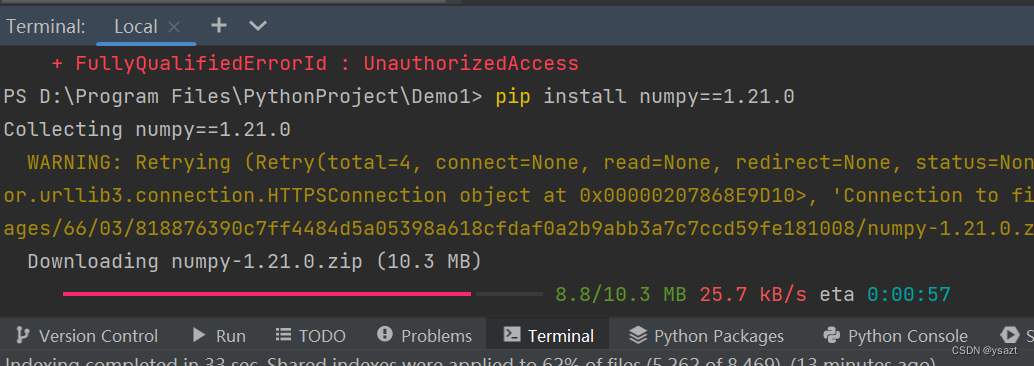
在Pycharm中使用pip install tensorflow安装tensorflow时报错: ERROR: Could not find a version that satisfies the requirement tensorflow(from versions: none) ERROR: No matching distribution found for tensorflow搜了好多帖子有的说可能是网络的问题&…...

pandas中的read_csv参数详解
1.官网语法 pandas.read_csv(filepath_or_buffer, sepNoDefault.no_default**,** delimiterNone**,** headerinfer’, namesNoDefault.no_default**,** index_colNone**,** usecolsNone**,** squeezeFalse**,** prefixNoDefault.no_default**,** mangle_dupe_colsTrue**,** dty…...
Python — — turtle 常用代码
目录 一、设置画布 二、画笔 1、画笔属性 2、绘图命令 (1) 画笔运动命令 (2) 画笔控制命令 (3) 全局控制命令 (4) 其他命令 3. 命令详解 三、文字显示为一个圆圈 四、画朵小花 一、设置画布 turtle为我们展开用于绘图区域,我们可以设置它的…...

【我是土堆 - PyTorch教程】学习随手记(已更新 | 已完结 | 10w字超详细版)
目录 1. Pytorch环境的配置及安装 如何管理项目环境? 如何看自己电脑cuda版本? 安装Pytorch 2. Python编辑器的选择、安装及配置 PyCharm PyCharm神器 Jupyter(可交互) 3. Python学习中的两大法宝函数 说明 实战操…...
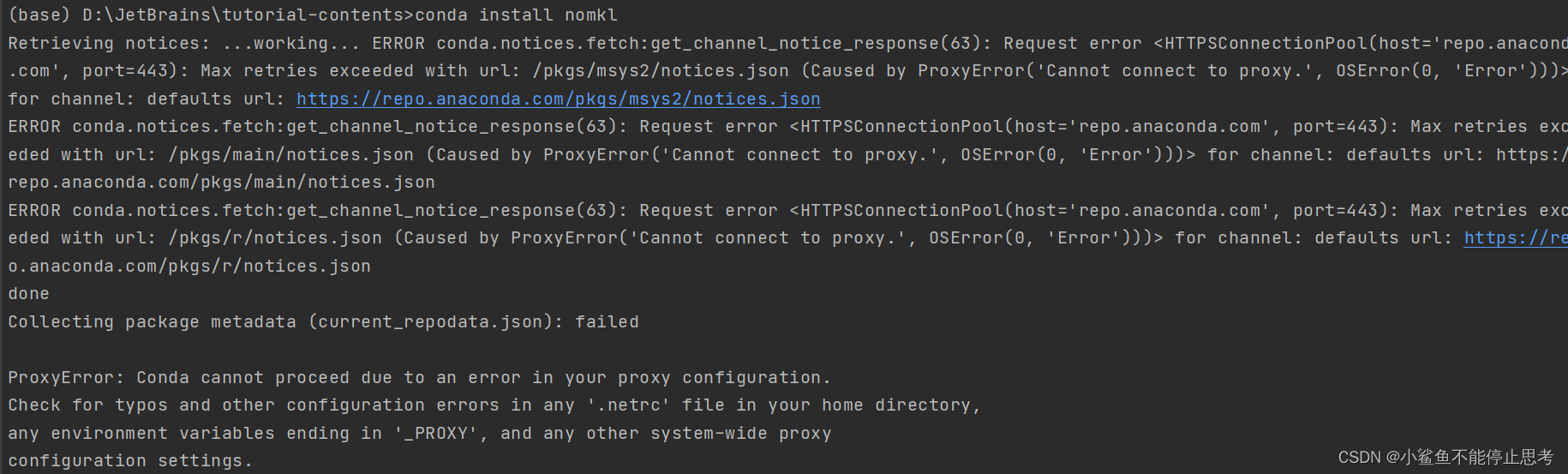
“OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.”解决方法总结
一、问题描述 跑了点神经网络的代码,想画几个激活函数的图像,代码如下: 运行后报了以下错误: 翻译如下: OMP:错误 #15:正在初始化 libiomp5md.dll,但发现 libiomp5md.dll 已经初…...
python3.11.2安装 + pycharm安装
下载 :https://www.python.org/ 2.双击下载的软件: 3.进入安装界面 下一步,点击 是 上一步点击后就看到如下: 安装成功了,接下来检测一下:cmd 安装pycharm PyCharm是一种Python IDE(Integr…...
Python中numpy.polyfit的用法详解
numpy中polyfit的用法 参数 polyfit(x, y, deg, rcondNone, fullFalse, wNone, covFalse):x:M个采样点的横坐标数组; y:M个采样点的纵坐标数组;y可以是一个多维数组,这样即可拟合相同横坐标的多个多项式; deg:多项式…...
彻底解决Python包下载慢问题
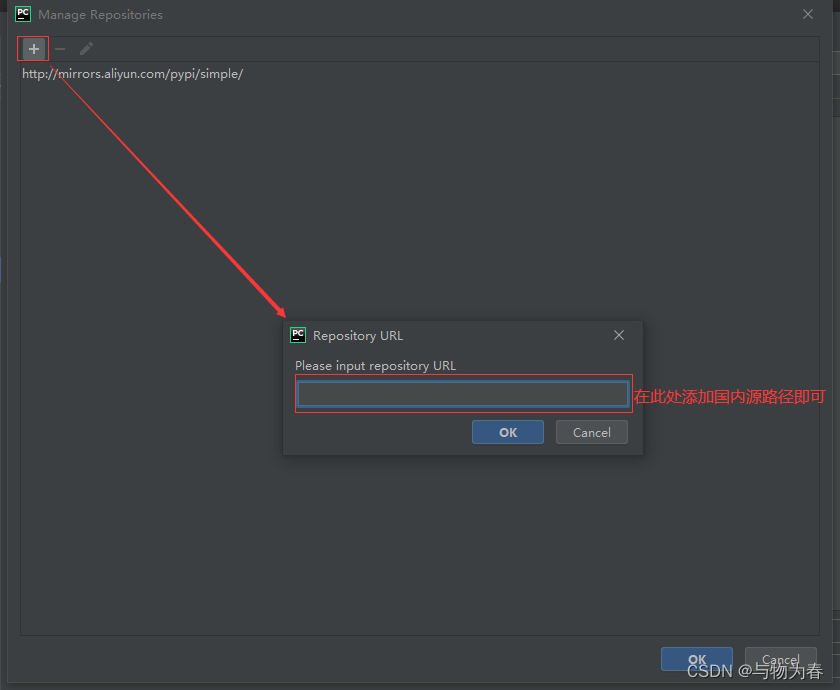
python默认使用的是国外镜像,有时候下载非常慢,最快的办法就是在下载命令中增加国内源: 常用的国内源如下: 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/ 阿里云:http://mirrors.aliyun.com/pypi/…...
Anaconda 使用指南,少走弯路
anaconda包管理器和环境管理器,强烈建议食用 1.下载 官网下载太慢可选用镜像下载 官网下载 :Anaconda | Individual Editionhttps://www.anaconda.com/products/distribution 镜像下载:Index of /anaconda/archive/ | 清华大…...
使用stable diffusion webui时,安装gfpgan失败的解决方案(windows下的操作)
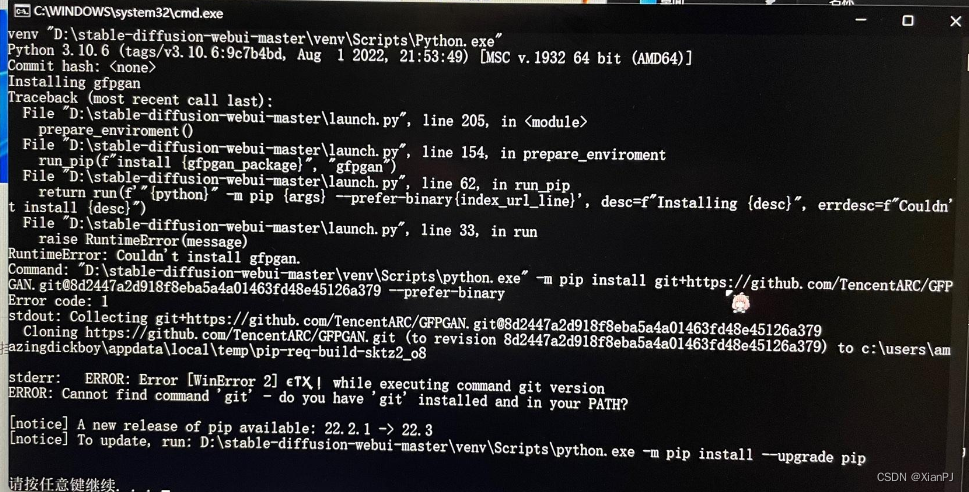
1.问题描述 初次打开stable diffusion webui时,需要安装gfpgan等github项目。但在安装gfpgan时,显示RuntimeError: Couldnt install gfpgan 2.解决方案 无法安装gfpgan的原因是网络问题,就算已经科学上网,并设置为全局&#x…...

Python 中导入csv数据的三种方法
这篇文章主要介绍了Python 中导入csv数据的三种方法,内容比较简单,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下微点阅读小编收集的文章介绍。 Python 中导入csv数据的三种方法,具体内容如下所示: 1、通过…...
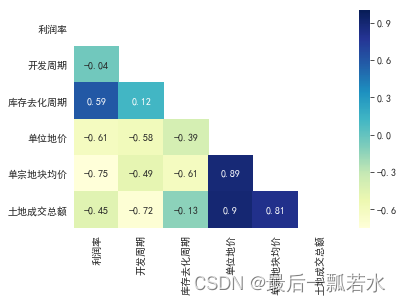
相关性分析、相关系数矩阵热力图
相关性 相关性分析是研究两组变量之间是否具有线性相关关系,所以做相关性分析的前提是假设变量之间存在线性相关性,得到的结果也是描述变量间的线性相关程度。除此之外,相关性分析方法还会有其他的假设条件。而灰色关联度分析首先对数据量要求…...
【python123】题目答案整理 ------更多答案见专栏
目录 二老鼠打洞 来自计算机的问候-任意数量参数 自定义幂函数 来自计算机的问候-多参函数 编写函数输出自除数 最大素数 求数列前n项的平方和 生兔子 计算圆周率——割圆法 数列求前n项和 素数: *如有错误请私聊纠正 二老鼠打洞 nint(input()) # 每日打…...
Python编程题汇总
Python编程复习 1.1找出列表中单词最长的一个 找出列表中单词最长的一个def test():a ["hello", "world", "yoyo", "congratulations"]length len(a[0])# 在列表中循环for i in a:if len(i) > length:length ireturn length p…...
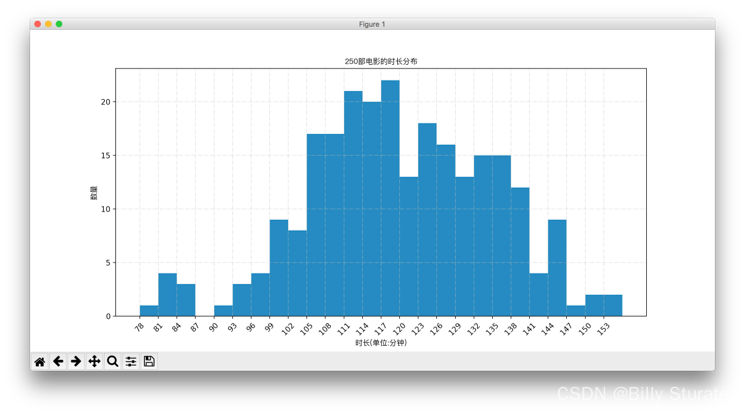
Matplotlib详解
视频教程 1.什么是matplotlib matplotlib: 最流行的Python底层绘图库,主要做数据可视化图表,名字取材于MATLAB,模仿MATLAB构建 2.样例 2.1折线图 eg:假设一天中每隔两个小时(range(2,26,2))的气温(℃)分别是[15,13,14.5,17,20,25,26,26,…...

Jetson AGX Orin安装Anaconda、Cuda、Cudnn、Pytorch、Tensorrt最全教程
文章目录一:Anaconda安装二:Cuda、Cudnn安装三:Pytorch安装四:Tensorrt安装一:Anaconda安装 Jetson系列边缘开发板,其架构都是arm64,而不是传统PC的amd64,深度学习的环境配置方法大…...
pytorch入门篇2 玩转tensor(查看、提取、变换)
上一篇博客讲述了如何根据自己的实际需要在pytorch中创建tensor:pytorch入门篇1——创建tensor,这一篇主要来探讨关于tensor的基本数据变换,是pytorch处理数据的基本方法。 文章目录1 tensor数据查看与提取2 tensor数据变换2.1 重置tensor形状…...

随机森林算法
随机森林1.1定义1.2随机森林的随机性体现的方面1.3 随机森林的重要作用1.4 随机森林的构建过程1.5 随机森林的优缺点2. 随机森林参数描述3. 分类随机森林的代码实现1.1定义 随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法。随机森林非常简单&am…...
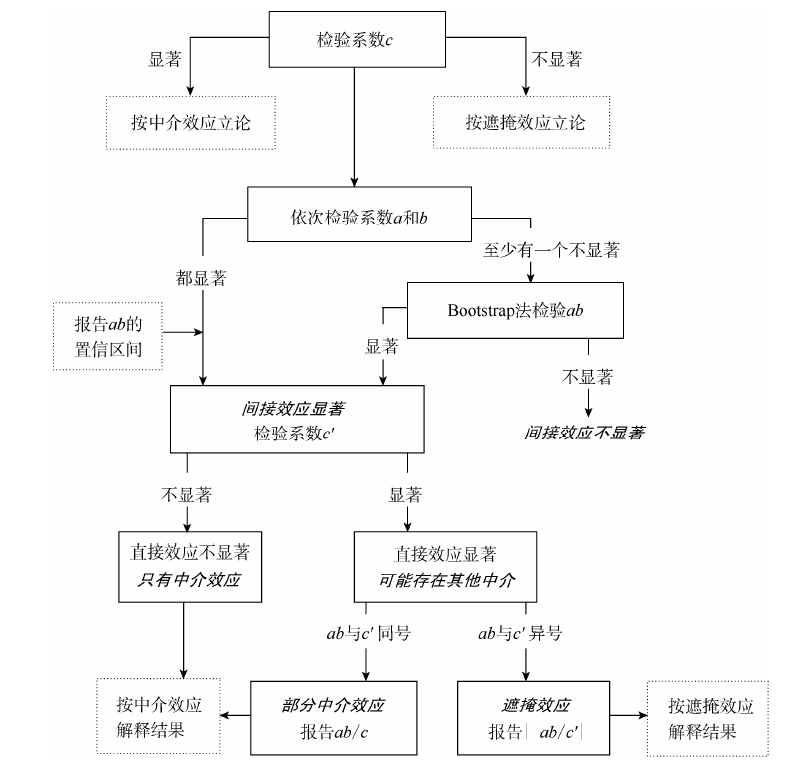
实证分析 | 中介效应检验原理与Stata代码实现
前言 本文是温忠鳞和叶宝娟2014年刊载于《心理科学进展》的论文《中介效应分析:方法和模型发展》的简要笔记与拓展。 温忠麟、叶宝娟:《中介效应分析:方法和模型发展》,《心理科学进展》,2014年第5期 中介效应检验 要…...

几个代码画出漂亮的词云图,python最简单的词云图教程(建议收藏)
在开始编写程序之前,我们先了解一下词云图的作用,我们拿到一篇文章,想得到一些关键词,但文章篇幅很大,无法短时间得到关键词,这时我们可以通过程序将文章中的每个词组识别出来,统计每个词组出现…...

mac m1,m2 安装 提供GPU支持的pytorch和tensorflow
mac m1,m2 安装 提供GPU支持的pytorch和tensorflowAnaconda安装测试Pytorch参考链接安装步骤安装 Xcode创建conda环境测试加速效果注意Tensorflow参考链接安装步骤安装 Xcode指定安装环境加速效果测试The Endmac m1 刚出的时候,各种支持都不完善。那时候要使用conda…...
如何用Python优雅的合并两个Dict
假设有两个dict x和y,合并成一个新的dict,不改变 x和y的值,例如 x {a: 1, b: 2}y {b: 3, c: 4} 期望得到一个新的结果Z,如果key相同,则y覆盖x。期望的结果是 >>> z {a: 1, b: 3, c: 4} 在PEP448中ÿ…...
python读取文件的几种方式
下面是不同场景较为合适的数据读取方法: 1.python内置方法(read、readline、readlines) 纯文本格式或非格式化、非结构化的数据,常用语自然语言处理、非结构文本解析、应用正则表达式等后续应用场景下,Python默认的三…...

python常用模块大全
目录 时间模块time() 与 datetime()random()模块os模块sys模块tarfile用于将文件夹归档成 .tar的文件shutil 创建压缩包,复制,移动文件zipfile将文件或文件夹进行压缩 shelve 模块 json和pickle序列化hashlib 模块subprocess 模块re模块 时间模块time() 与 datetime() time()模…...

成本降低90%,OpenAI正式开放ChαtGΡΤ
今天凌晨,OpenAI官方发布ChαtGΡΤ和Whisper的接囗,开发人员现在可以通过API使用最新的文本生成和语音转文本功能。OpenAI称:通过一系列系统级优化,自去年12月以来,ChαtGΡΤ的成本降低了90%;现在OpenAI用…...

Python:ModuleNotFoundError错误解决
前言: 大家都知道python项目中需要导入各种包(这里的包引鉴于java中的),官话来讲就是Module。 而什么又是Module呢,通俗来讲就是一个模块,当然模块这个意思百度搜索一下都能出来,Python 模块(…...
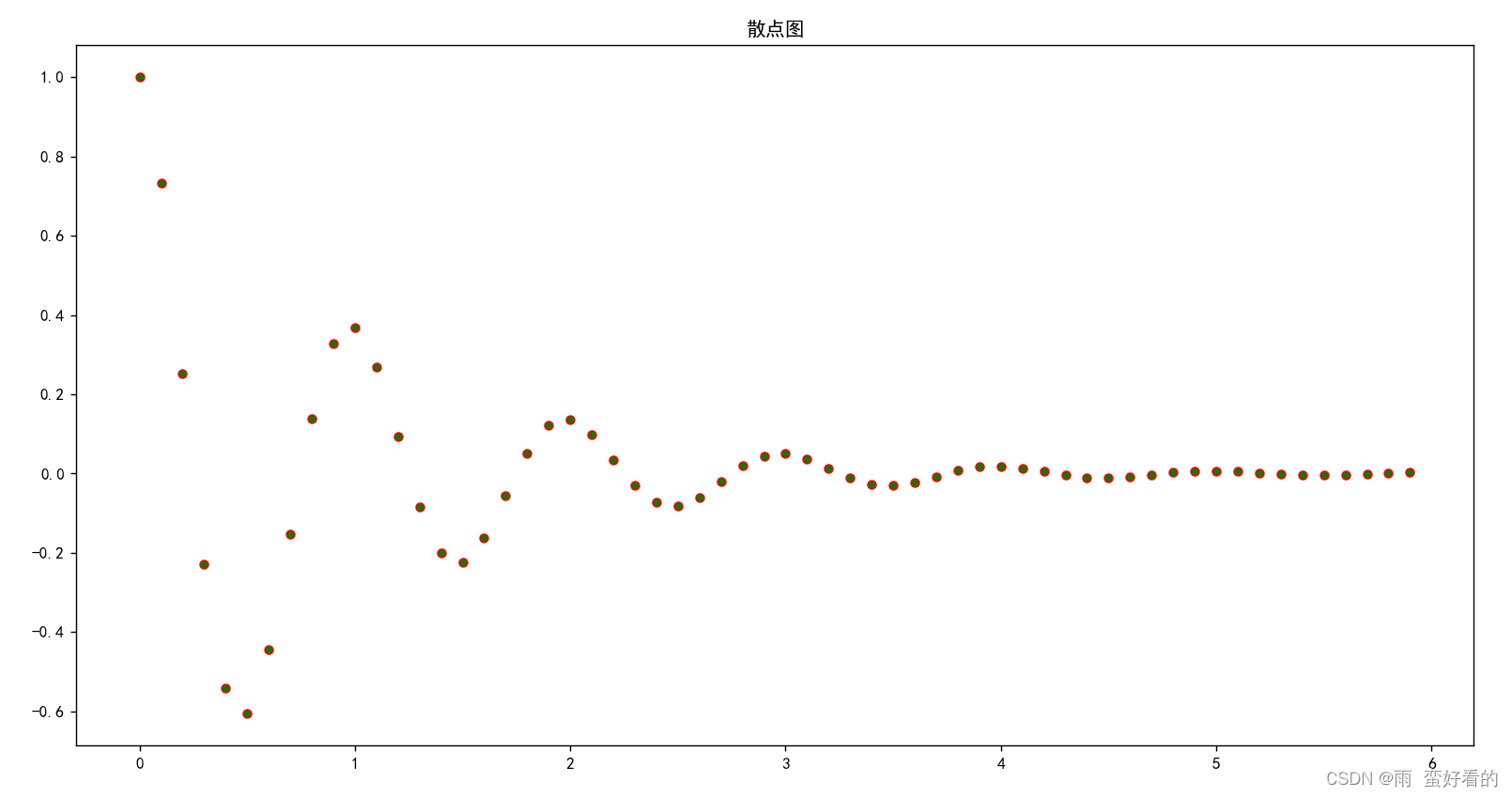
python案例——利用python画图
1、画直线 问题描述: 利用python中的 turtle (海龟绘图)模块提供的函数绘制直线 算法设计: turtle.penup(): 画笔抬起turtle.color(): 设置颜色turtle.goto(): 画笔移动到下一目标turtle.pendown(): …...

pandas.DataFrame设置某一行为表头(列索引),设置某一列为行索引,按索引取多行多列
pandas读取文件 pandas.DataFrame 设置索引 pandas.DataFrame 读取单行/列,多行多列 pandas.DataFrame 添加行/列 利用pandas处理表格类型数据,快捷方便,不常用但是有的时候又是必要技能,在这里记录一下一些常用函数和自己的踩坑…...

主成分分析(PCA)算法模型实现及分析(MATLAB实现)PCA降维
主成分分析(PCA)算法模型实现及分析(源码在文章后附录)1 引言2 关于PCA原理和算法实现2.1 PCA基本原理2.2 协方差计算2.3 PCA实现步骤 (1)PCA算法实现步骤 (2)基于特征值分解协…...

python 识别图片验证码/滑块验证码准确率极高的 ddddocr 库
前言 验证码的种类有很多,它是常用的一种反爬手段,包括:图片验证码,滑块验证码,等一些常见的验证码场景。 识别验证码的python 库有很多,用起来也并不简单,这里推荐一个简单实用的识别验证码的…...
华为OD机试 - 称砝码(Java JS Python)
题目描述 现有n种砝码,重量互不相等,分别为 m1,m2,m3…mn ; 每种砝码对应的数量为 x1,x2,x3...xn 。现在要用这些砝码去称物体的重量(放在同一侧),问能称出多少种不同的重量。 输入描述 对于每组测试数据: 第一行:n --- 砝码的种数(范围[1,10]) 第二行:m1 m2 m3 ... m…...

DataFrame转化为json的方法教程
网络上有好多的教程,讲得不太清楚和明白,我用实际的例子说明了一下内容,附档代码,方便理解和使用 DataFrame.to_json(path_or_bufNone, orientNone, date_formatNone, double_precision10, force_asciiTrue, date_unitms, defau…...
requests库的使用(一篇就够了)
urllib库使用繁琐,比如处理网页验证和Cookies时,需要编写Opener和Handler来处理。为了更加方便的实现这些操作,就有了更为强大的requests库。 request库的安装 requests属于第三方库,Python不内置,因此需要我们手动…...
Pytorch+PyG实现MLP
文章目录前言一、导入相关库二、加载Cora数据集三、定义MLP网络四、定义模型五、模型训练六、模型验证七、结果完整代码前言 大家好,我是阿光。 本专栏整理了《图神经网络代码实战》,内包含了不同图神经网络的相关代码实现(PyG以及自实现&a…...
PYcharm怎么用,一篇教会你
文章目录一、界面介绍二、设置中文(无需汉化包)三、常用快捷键四、Python 标识符和关键字1、标识符2、 关键字五、行和缩进六、Python 引号七、Python注释1、单行注释2、多行注释八、Python空行九、输入和输出1、print 输出2、input 输入十、多行语句一、…...
如何在pycharm中使用anaconda的虚拟环境
最近项目中有许多同学咨询如何在pycharm中使用anaconda的虚拟环境(envs),这里就给大家简单介绍一下。 首先我们需要安装anaconda,这里就不在追述了,网上安装教程非常多。anaconda的安装路径大家需要记着因为后面会使用…...
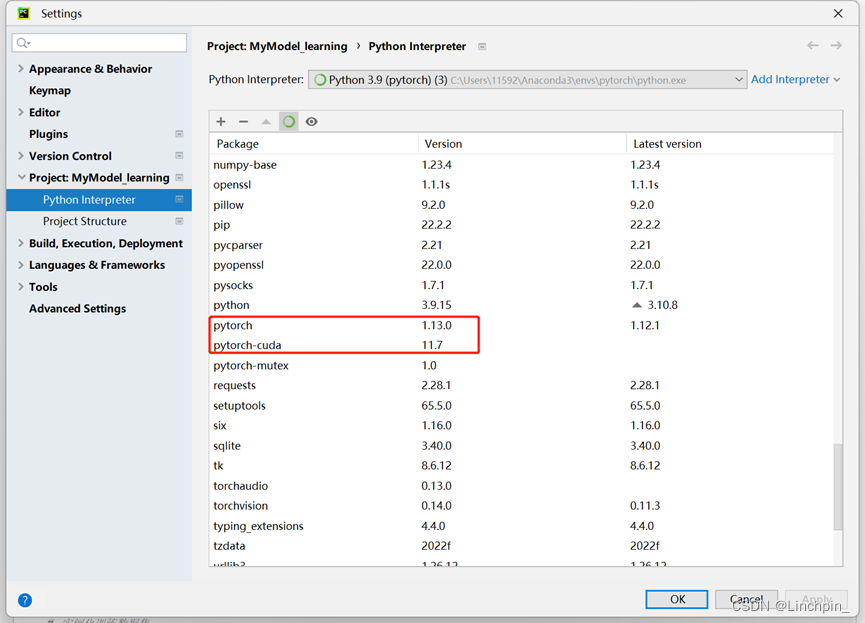
Pytorch环境安装+Pycharm环境安装
我的配置: CUDA版本:11.7 Pytorch版本:1.13.0 Anaconda版本:anaconda3.2022.10(64-bit) Pycharm版本:2022社区版 具体配置过程如下: 1.Anaconda安装 本次安装的anaconda为win6…...
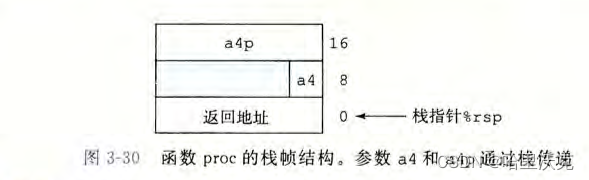
csapp第三章(2) --- 程序的机器级表示
csapp第三章(1) --- 程序的机器级表示https://blog.csdn.net/m0_63488627/article/details/129470787?spm1001.2014.3001.5501本章大纲 目录 3.4.过程 3.4.1运行中的栈 3.4.2转移控制 3.4.3数据传送 3.4.4栈上的局部存储 3.4.5栈的递归实现 3.5.数组分配和访问 3.6结…...
使用Ananconda进行Pytorch配置
为什么选择pytorch: 活跃度:逐渐形成了完整的开发生态,资源多。动态图:动态图架构,且运行速度较快。代码简洁:易于理解,设计优雅,易于调试。 可能有的疑惑: 深度学习框架太多不知道…...

python实现定时任务的8种方式详解
在日常工作中,常常会用到需要周期性执行的任务,一种方式是采用 Linux 系统自带的 crond 结合命令行实现。另外一种方式是直接使用Python。 当每隔一段时间就要执行一段程序,或者往复循环执行某一个任务,这就需要使用定时任…...