深度学习—卷积神经网络(CNN)全笔记,附代码
本文内容为哔站学习笔记【卷积神经网络-CNN】深度学习(唐宇迪带你学AI):卷积神经网络理论详解与项目实战,计算机视觉,图像识别模块实战_哔哩哔哩_bilibili
目录
深度学习基础
什么是深度学习?
机器学习流程
特征工程的作用
特征如何提取
为什么需要深度学习
深度学习的应用
深度学习缺点
传统算法与深度学习编辑
计算机视觉
计算机视觉面临的挑战
机器学习常规套路
K近邻
K近邻计算流程
K近邻分析
数据库样例:CIFAR-10
为什么K近邻不能用来图像分类
神经网络基础
线性函数
W中权重值是怎么来的呢?
损失函数
Softmax分类器
前向传播
卷积神经网络
卷积神经网络能做哪些事情?
卷积网络与传统网络的区别
整体架构
卷积层
卷积做了什么事?
只做一次卷积就可以了吗?
卷积层涉及参数
池化层
最大池化
整体架构具体做法
特征图的变化
经典网络—Alexnet
经典网络—Vgg
经典网络—Resnet
感受野
项目实战—基于CNN构建识别模型一
首先读取数据
卷积网络模块构建
准确率作为评估标准
训练网络模型
项目实战—基于CNN构建识别模型二
图像识别实战常用模块解读
数据预处理部分
网络模块设置
网络模型保存与测试
数据读取与预处理操作
制作好数据源
>> 数据增强
读取标签对应的实际名字
展示下数据
>>迁移学习
加载models中提供的模型,并且直接用训练的好权重当做初始化参数
设置哪些层需要训练
优化器设置
训练模块
深度学习基础
什么是深度学习?
深度学习是机器学习的一部分,效果比较好。
神经网络(CNN)不应该称之为一种算法,应该当做一种特征提取的方法。
机器学习流程
数据获取——特征工程——建立模型——评估与应用
特征工程最为重要最核心的一部分。
深度学习一定程度上解决了机器学习上人工的部分问题。可以自行判断提取特征,选择最适合的方法来处理。而机器学习需要人为的提取特征
特征工程的作用
- 数据特征决定了模型的上限。
- 预处理和热证提取是最核心的。
- 算法与参数选择决定了如何逼近这个上限。
特征如何提取

为什么需要深度学习
深度学习是真正能够学什么样的特征是最合适的。
解决的核心是怎么样去提取特征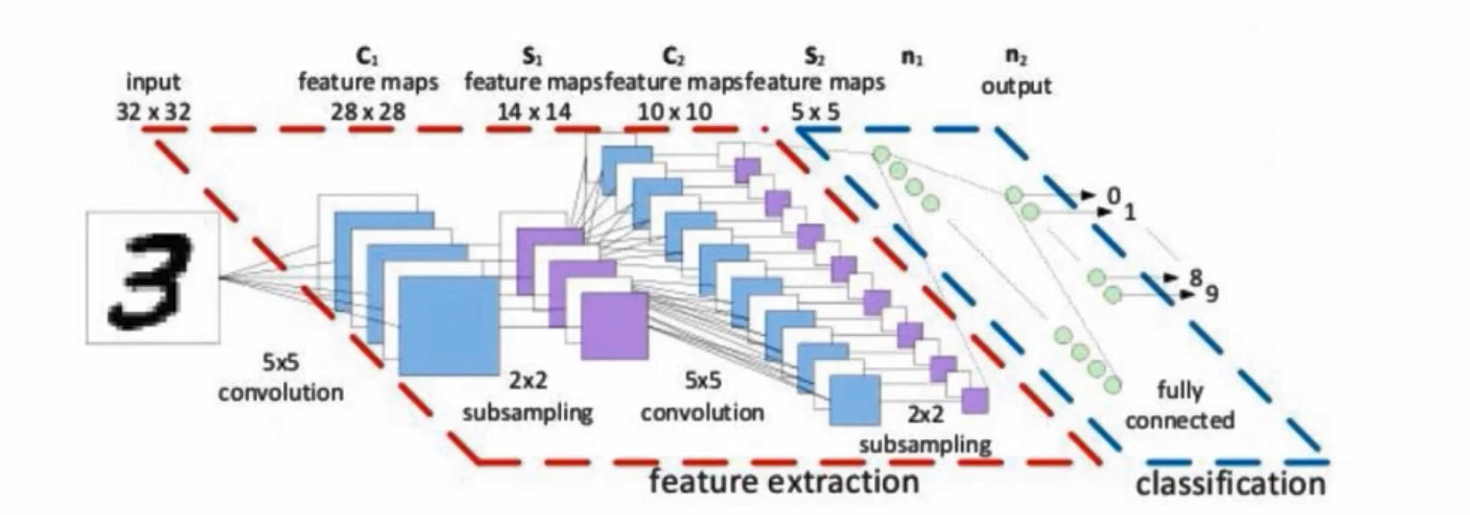
深度学习的应用
可以在计算机视觉及自然语言处理中做一些东西
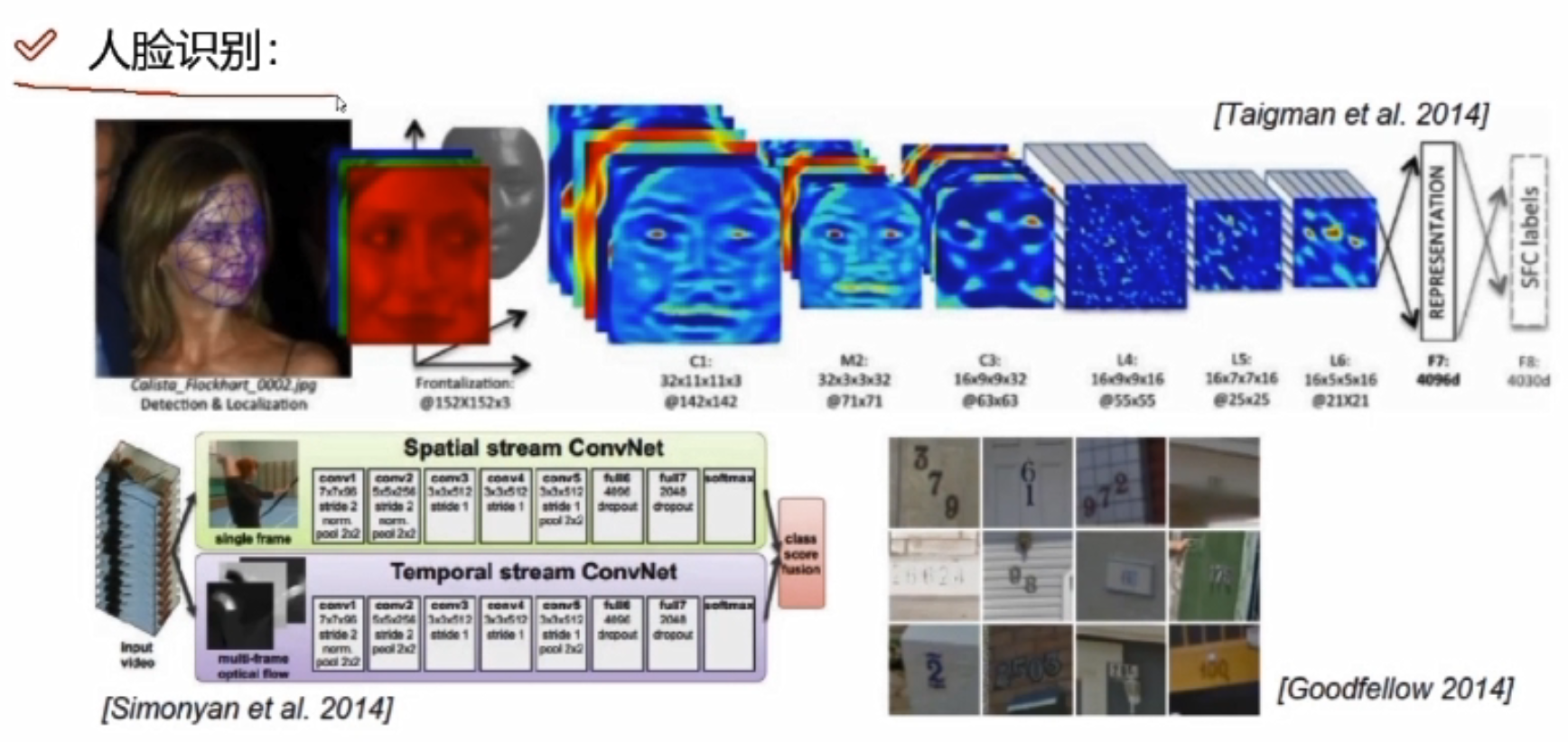
人脸识别
医学方面的应用
换脸操作
影片复原
应用非常广泛
深度学习缺点
深度学习计算的量非常大,速度可能太慢了。
传统算法与深度学习
计算机视觉

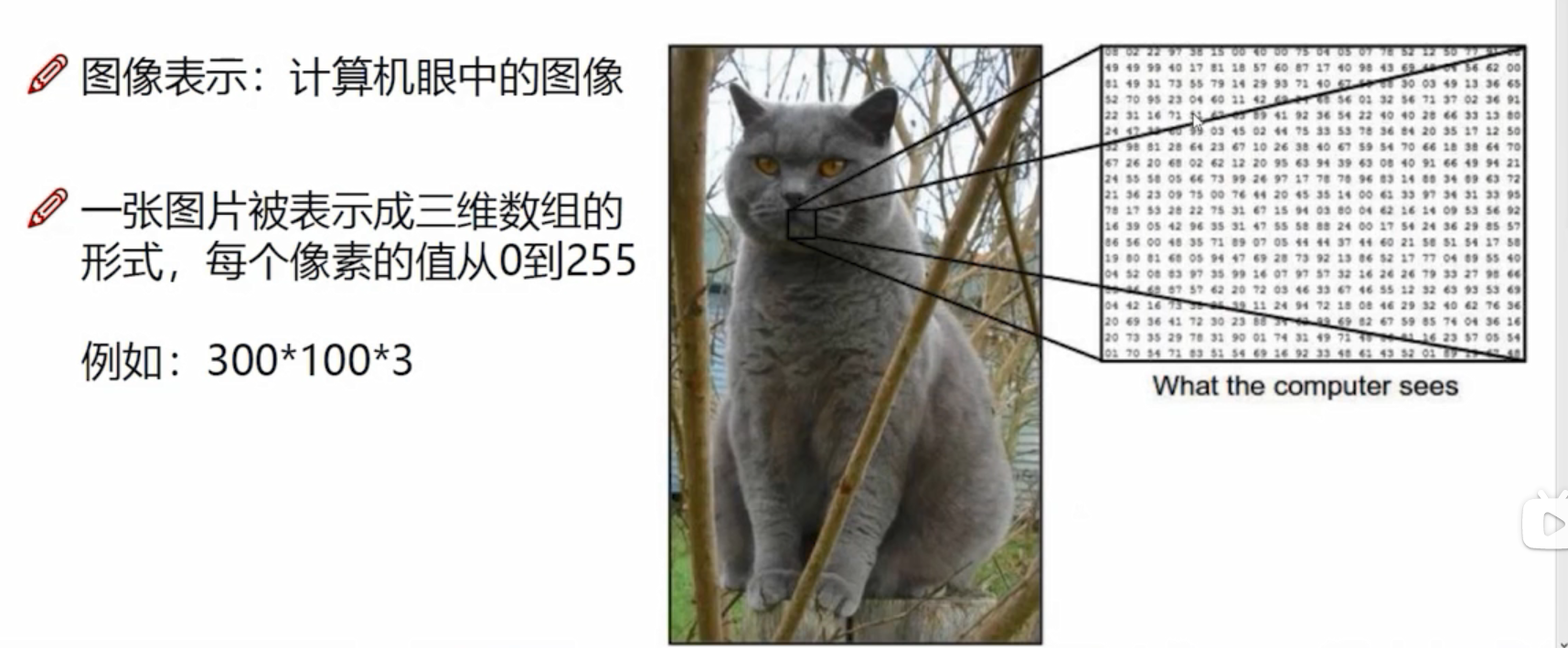
计算机视觉面临的挑战


机器学习常规套路
- 收集数据并给定标签
- 训练一个分类器
- 测试,评估
K近邻
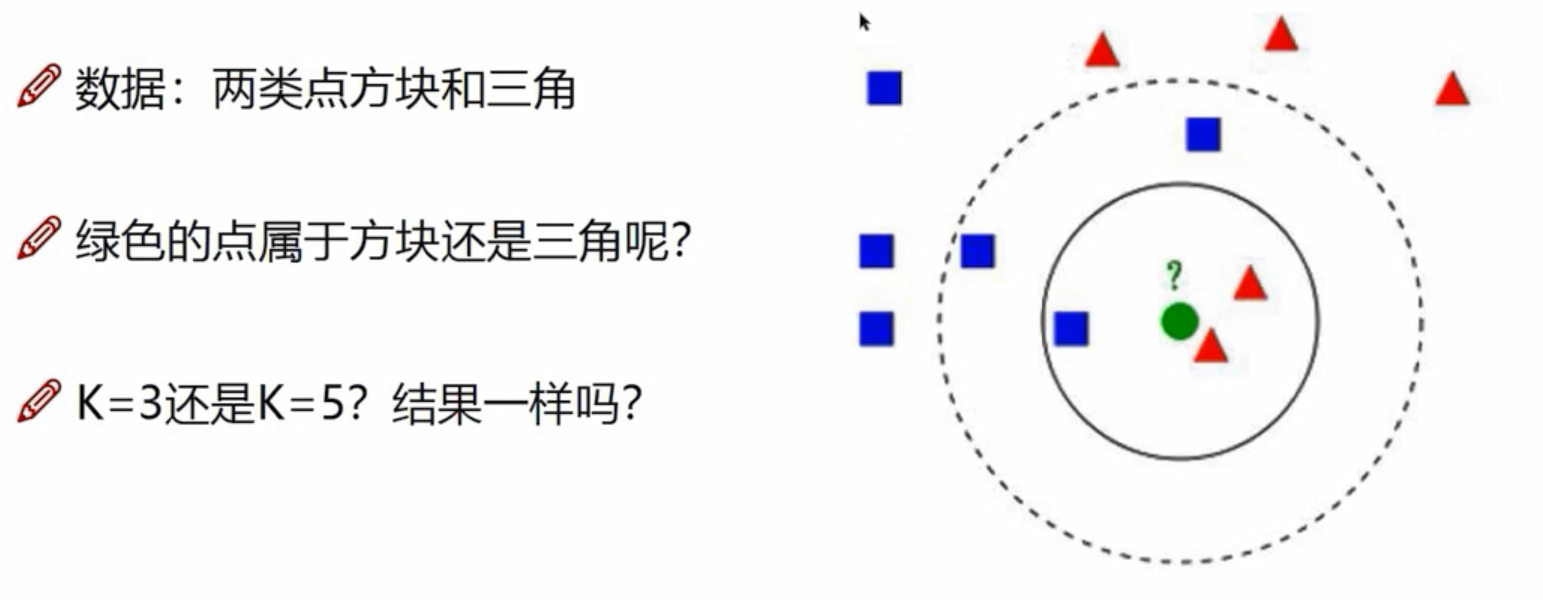 K=3,三角;K=5,方块。
K=3,三角;K=5,方块。
K近邻计算流程
- 计算已知类别数据集中的点与当前点的距离
- 按照距离依次排序
- 选取与当前点距离最小的K个点
- 确定前K个点所在类别的出现概率
- 返回前K个点出现频率最高的类别作为当前点预测分类
K近邻分析
- KNN算法本身简单有效,它是一种lazy-learning算法。
- 分类器不需要使用训练集进行训练,训练时间复杂度为0。
- KNN分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为n,那么KNN的分类时间复杂度为O(n)。
- K值的选择,距离度量和分类决策规则是该算法的三个基本要素
数据库样例:CIFAR-10
K近邻做图像分类



问题在于图像中有些东西没有注意到,没有告诉主体与背景
为什么K近邻不能用来图像分类
- 背景主导是一个最大的问题,我们关注的却是主体(主要成分)
如何才能让机器学习到哪些是重要的成分呢?
神经网络基础
线性函数
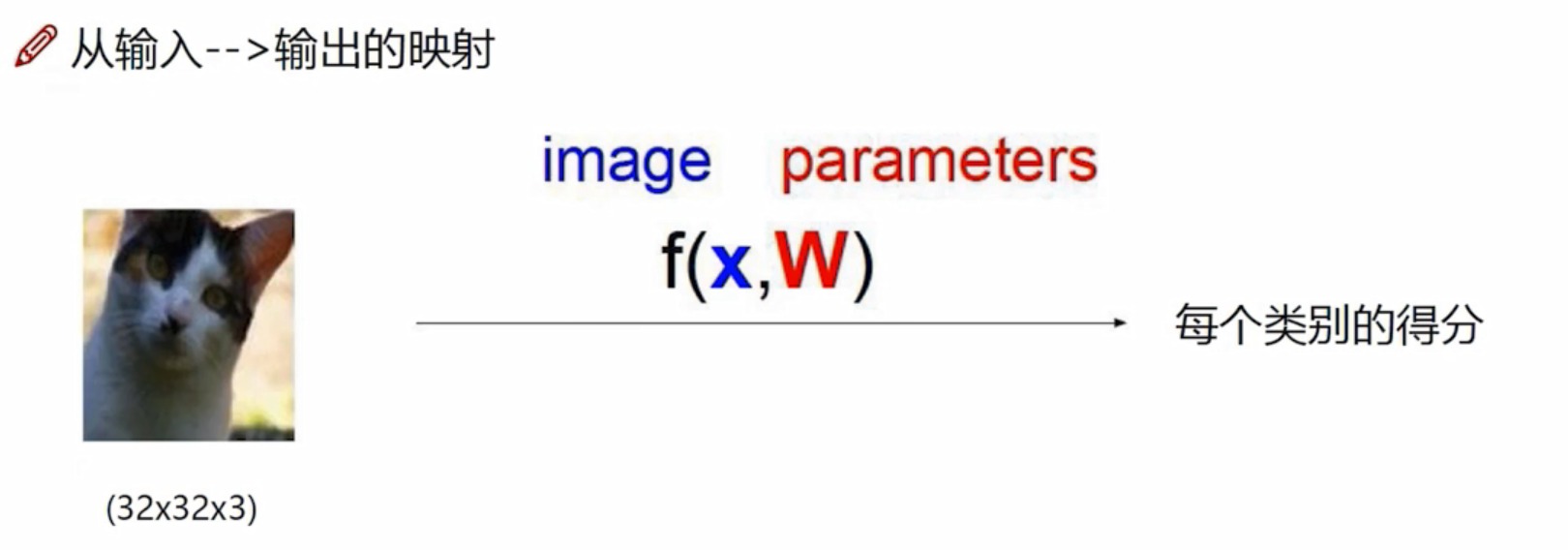
眼睛、耳朵、背景等的像素点对结果的影响是不一样的,有些像素点对于它是猫起到促进作用 ,有些则是抑制作用。所以每个像素点对应的重要程度是不一样的,W称之为权重参数。
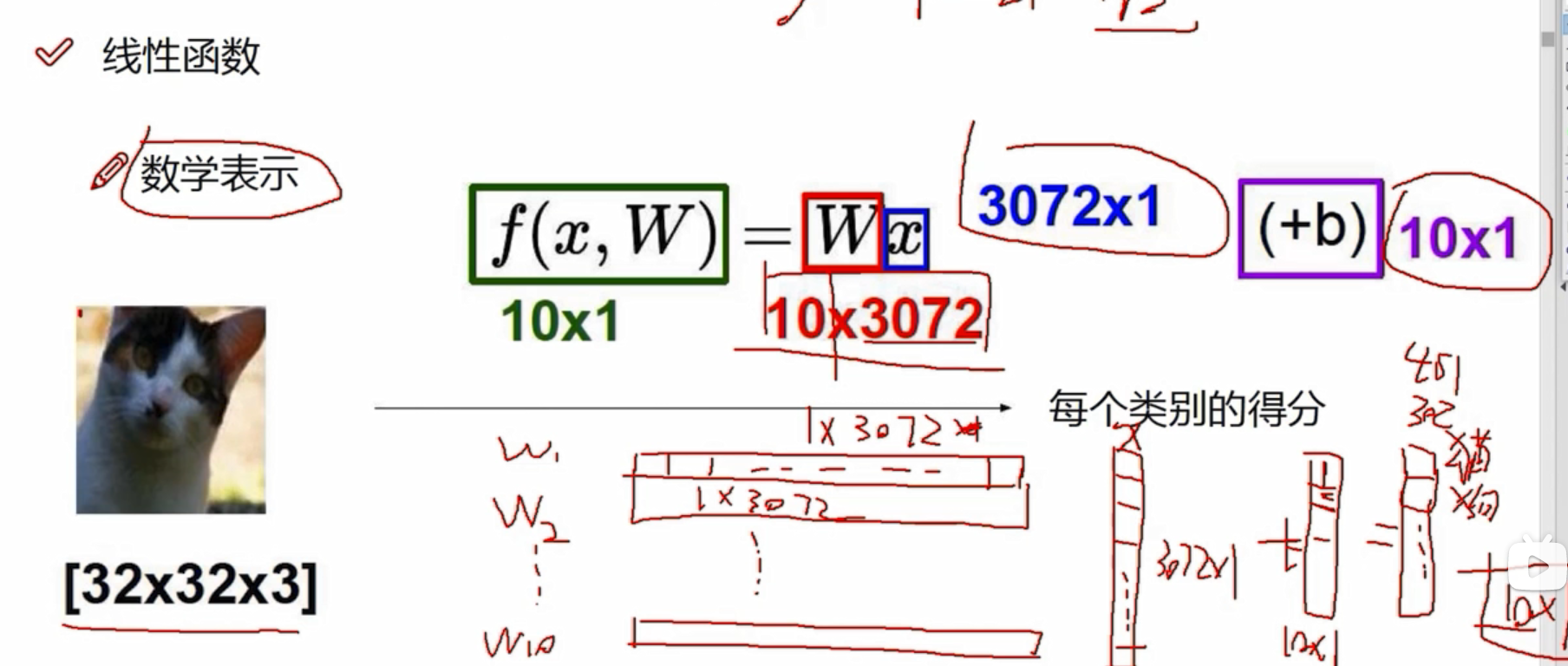
3072个像素点,每个像素点在当前类别都有自己的权重,3072个像素点有3072个权重,比如该像素点在猫类有猫类的权重、在狗类有狗类的权重,只是权重大小值不一样。若分为10个类别,则有10*3072个权重参数,即W是10*3072的矩阵;x代表3072个像素点,是3072*1的矩阵。
W*X是10*1的矩阵,即每个类别的得分的结果。
b是偏置参数,是10*1的矩阵,起微调作用,每个类别有自己的微调值。
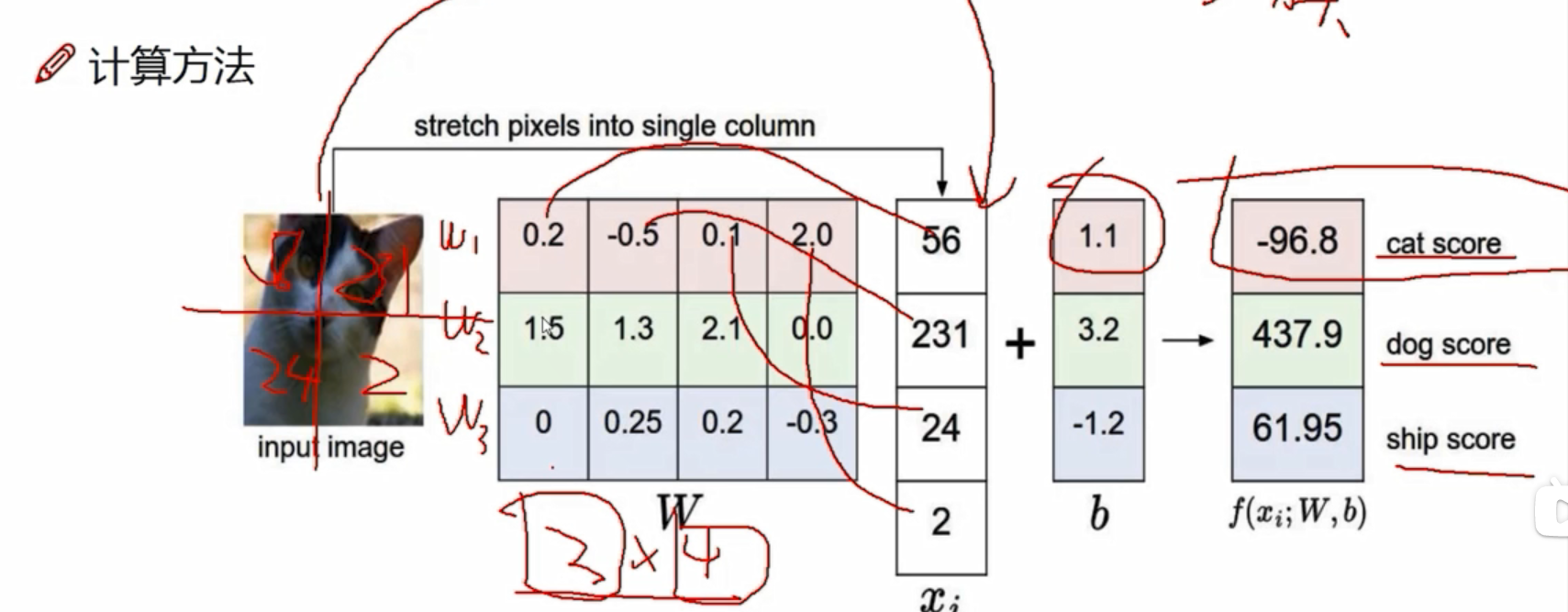
- 假设这个猫由四个像素点构成,x是4*1的矩阵,有三个类别: 猫、狗、船;W是3*4的矩阵,3代表三个类别,4代表4个像素在各类别的权重参数;b是3*1的偏置参数。
- W中较大的值代表:在这种类别中,该像素的影响是比较大的,比如2.1代表在狗这一类中,像素值为24的影响是2.1,0代表不太重要。
- W中±代表:正值代表促进作用,负值代表抑制作用
W中权重值是怎么来的呢?
权重值是优化而来的 ,一开始的权重值可以设为随机数,比如上图,明明是个猫,最后结果分类却是狗。原因何在?
数据是不变的,当图像输入后,x的值是不变的,但是W的值是可以改变的。
神经网络做的事就是优化W,使W能更适合于数据去做当前这个任务。
W一开始可以设随机值。接下来在迭代过程中,想一种优化方法,不断改进W参数。
 权重参数控制着决策边界的走势,偏置参数只是做一个微调。
权重参数控制着决策边界的走势,偏置参数只是做一个微调。
损失函数


:其他错误类别
:正确类别
1:相当于一个容忍程度,0代表无损失,当正确与错误得分相近的时候,有可能区别不出来,这时候+1可以更好地区分错误与正确的结果。

A与B模型不一样,A会产生过拟合,是不希望出现的,所以在构建损失函数当中,还需要加上正则化惩罚项

R(W):只考虑权重参数,10个分类则R(W)=W1平方+W2平方+...+...+W10平方
:惩罚系数,值越大代表不希望过拟合,正则化惩罚大一些;
Softmax分类器
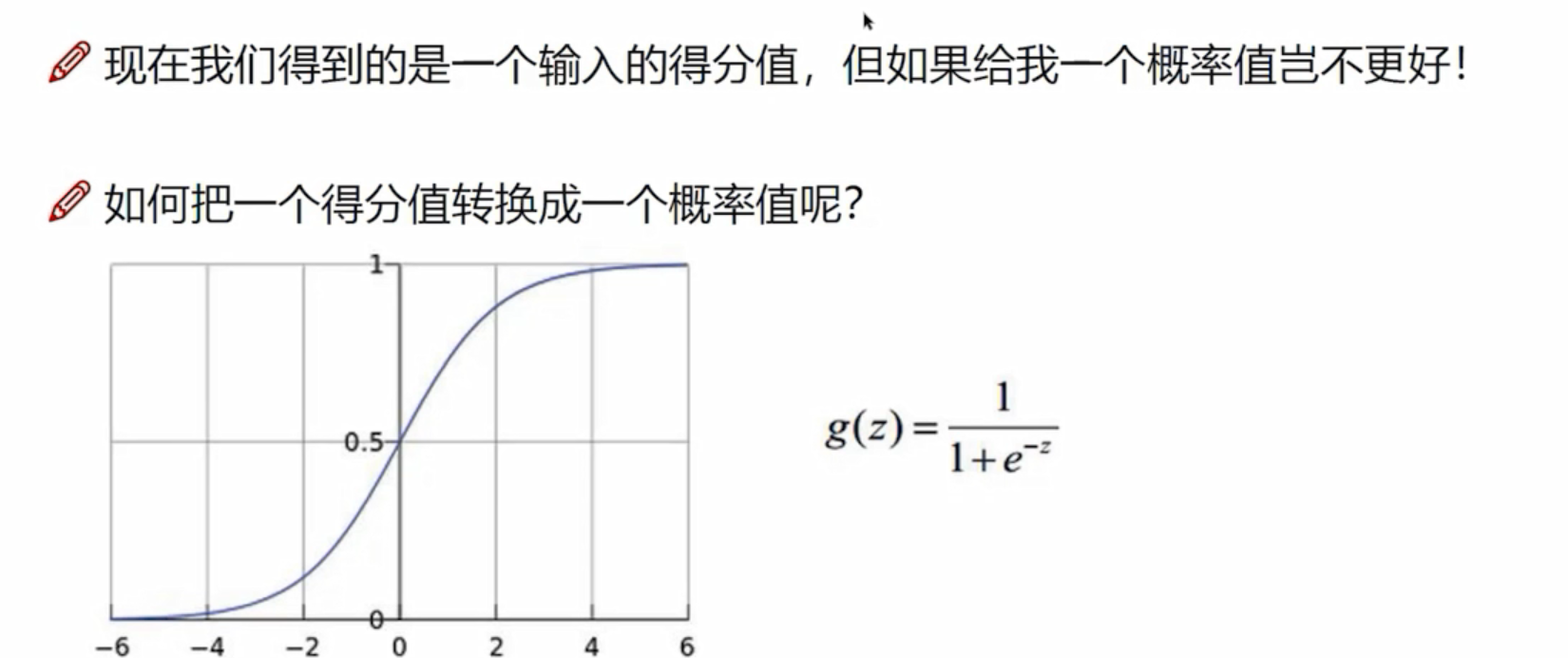

exp: 做一个映射,
=24.5,5.1映射后成为164,-1.7映射成为0.18
归一化:该项得分/全部加起来
计算损失值:输入的是正确类别的概率值;正确图像本来是一个猫,但是毛的概率值为0.13,所以损失值L=-log(0.13)=0.89
前向传播
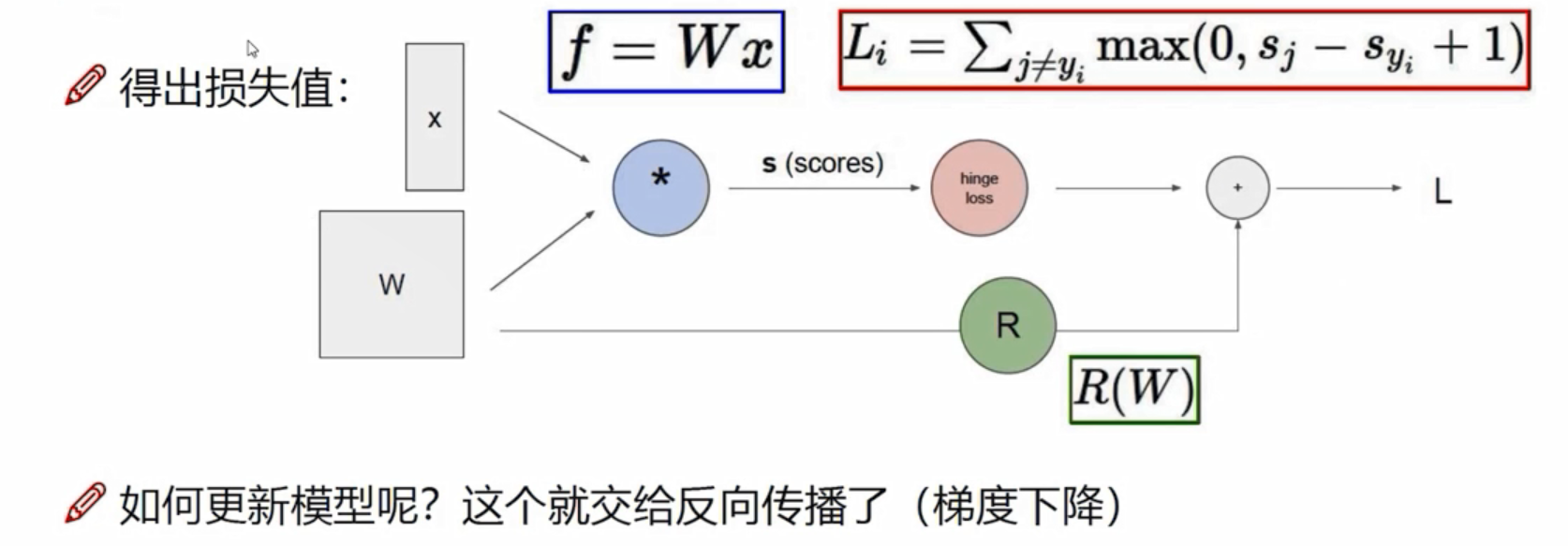 从W,x到最后得到损失值L这一步,叫做前向传播。更新模型,优化W,则需要梯度下降
从W,x到最后得到损失值L这一步,叫做前向传播。更新模型,优化W,则需要梯度下降
卷积神经网络
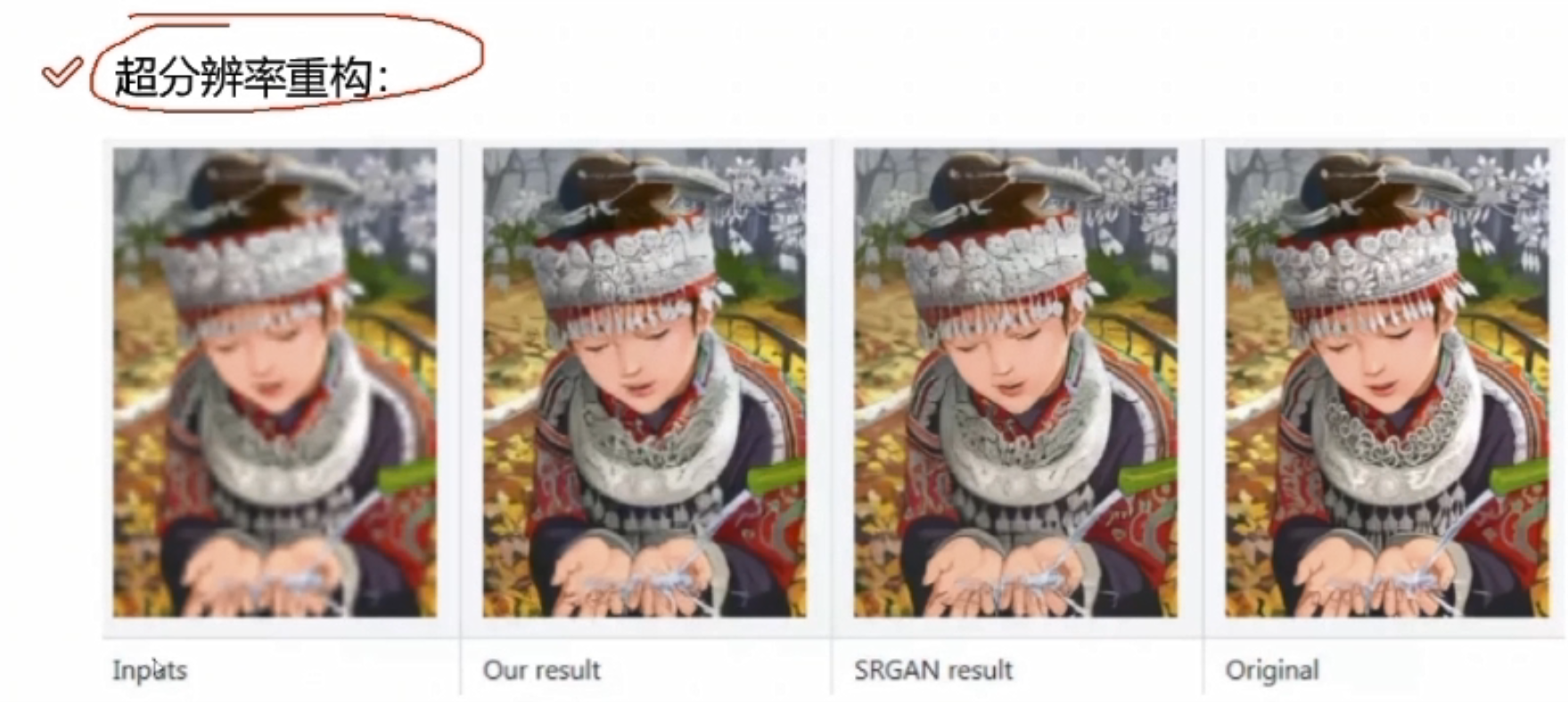
卷积神经网络能做哪些事情?
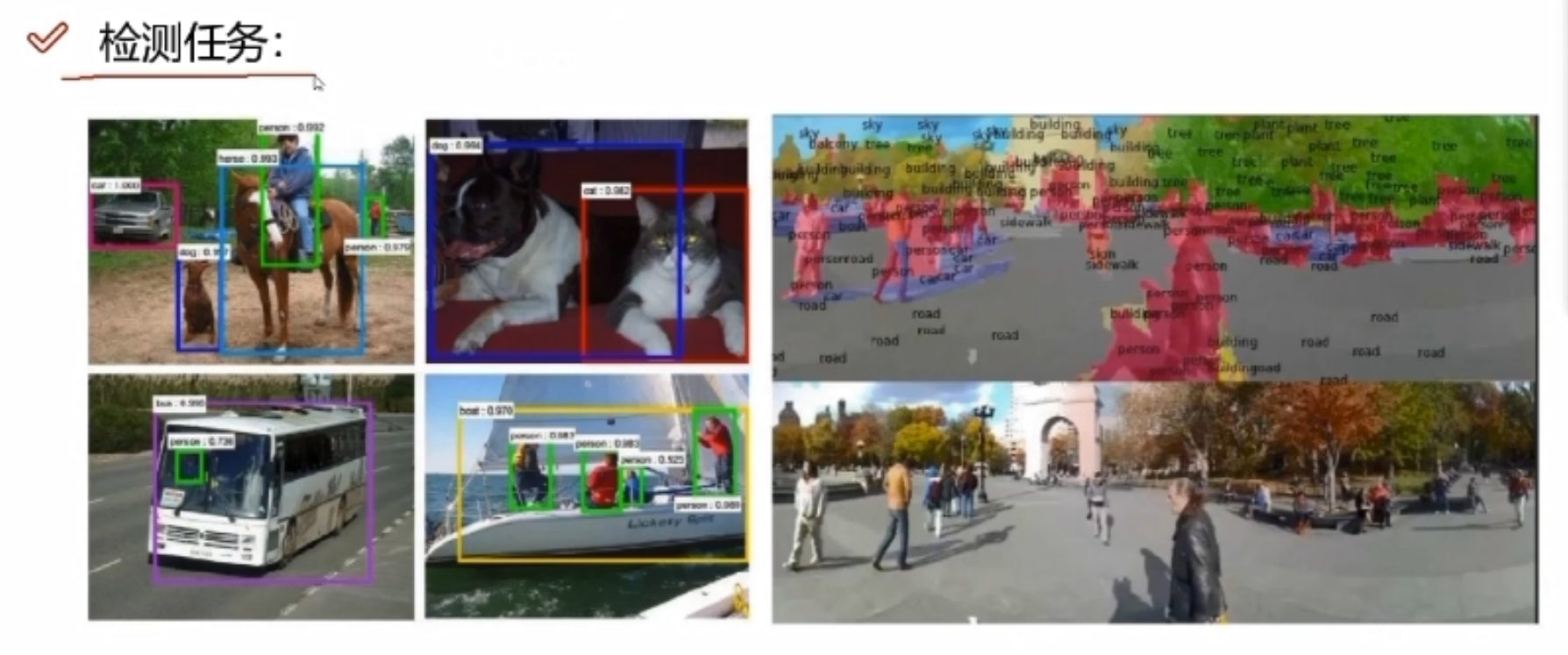

检索:输入一张图像,返回类似结果。


卷积网络与传统网络的区别

左边是传统网络(NN),右边是卷积网络(CNN),左边输入的是像素点,右边输入是图像
比如左边输入784,是784个像素点,而右边是28*28*1的图像,是三维的
卷积网络不会先把数据拉成一个向量,而是直接对图像数据进行特征提取。是h*w*c的
整体架构
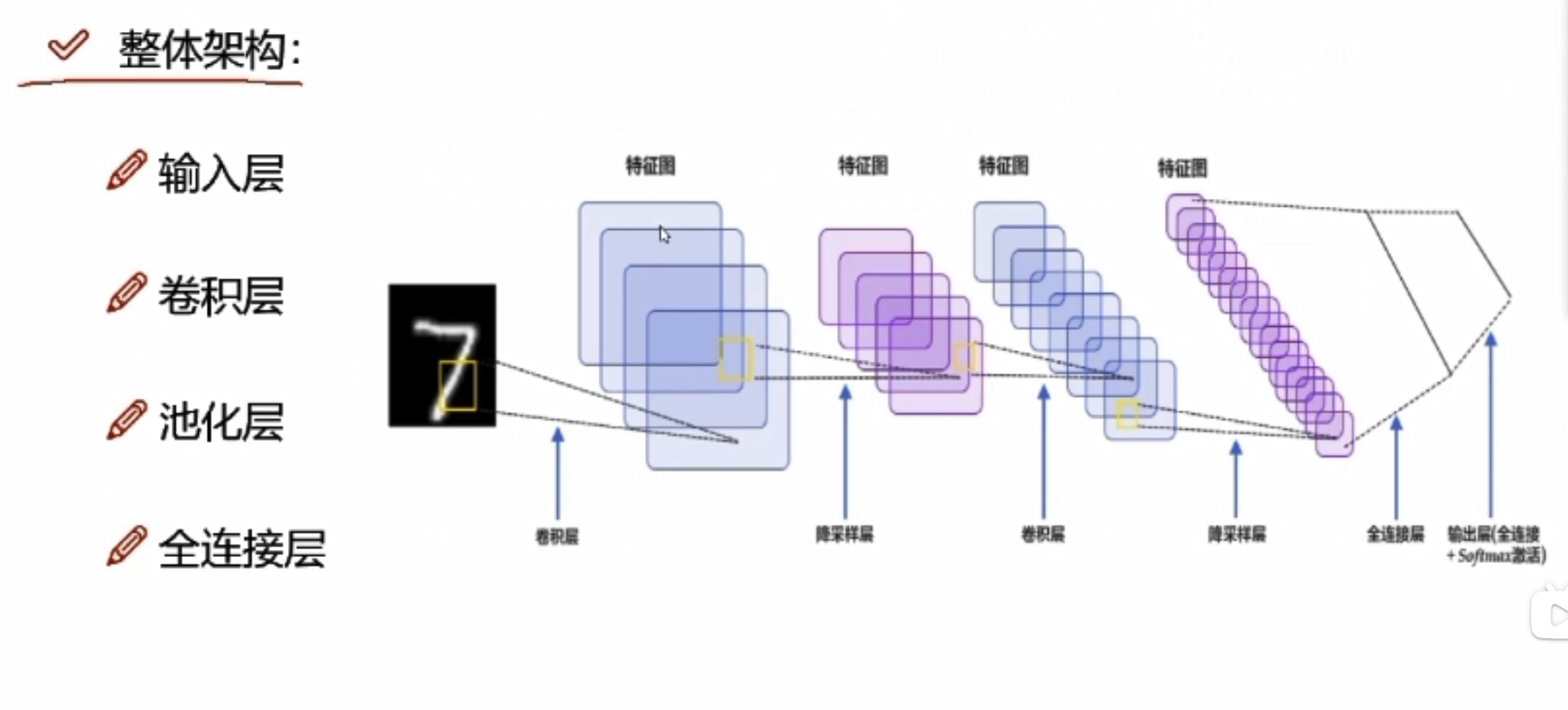
输入层是输入图像,三维的,卷积是提取特征,池化是压缩特征
卷积层
卷积做了什么事?
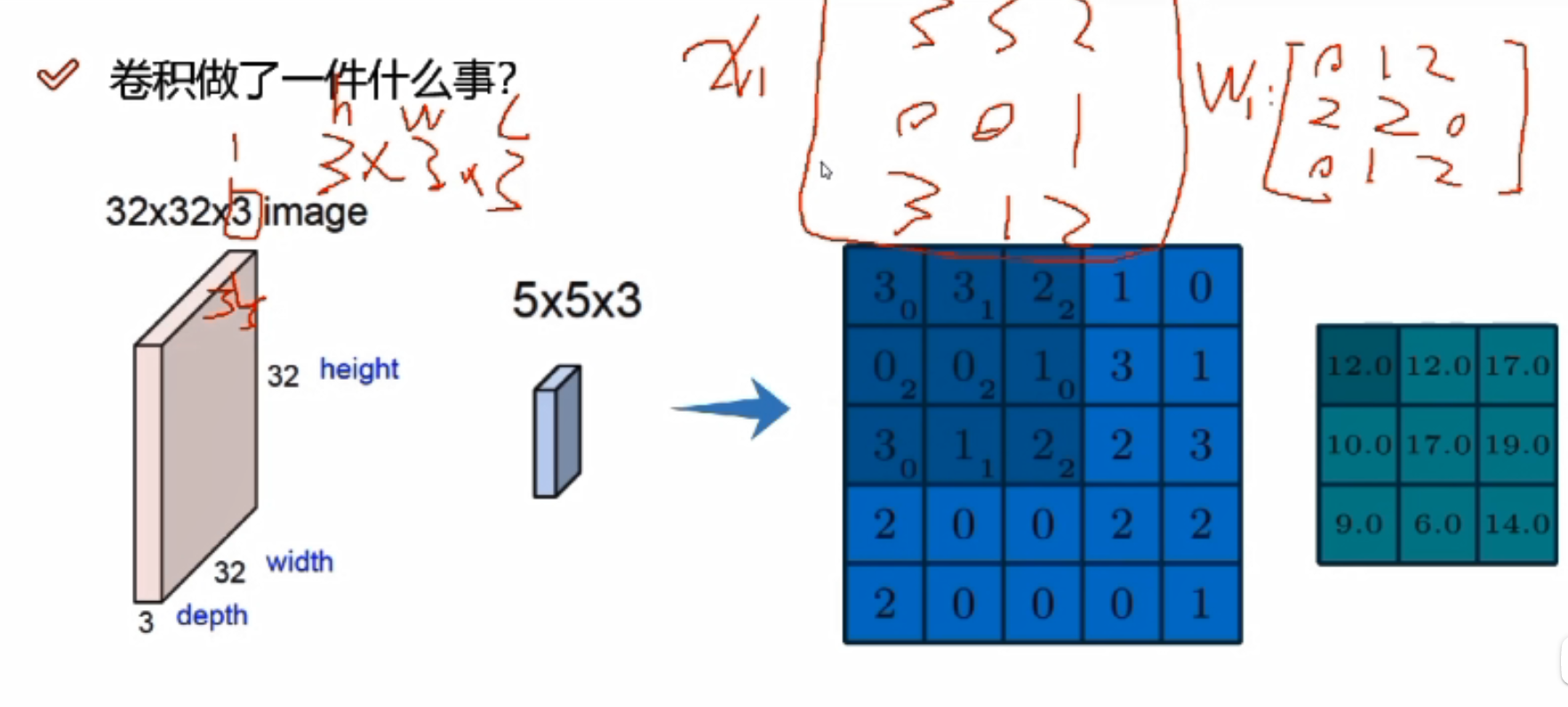
图像数据不同区域的特征是不一样的,重要程度也是不一样的
先把图像分割成不同的区域,每个区域再提取不同的特征,和神经网络一样,也是用一组权重参数来得到特征值
蓝色图像中的3*3可以当做图像数据中的一个分割后的小区域(每3*3分割),而下标数字则是这个区域对应的权重参数矩阵。最后还是得到一个值12,12是当前这个分割区域的代表值。
绿色图表示执行一次卷积后得到的特征图
 RGB
RGB
32*32*3,3代表三个颜色通道
实际做计算的时候,需要每个颜色通道都算一遍,最终将每个颜色通道卷积完成的结果加起来
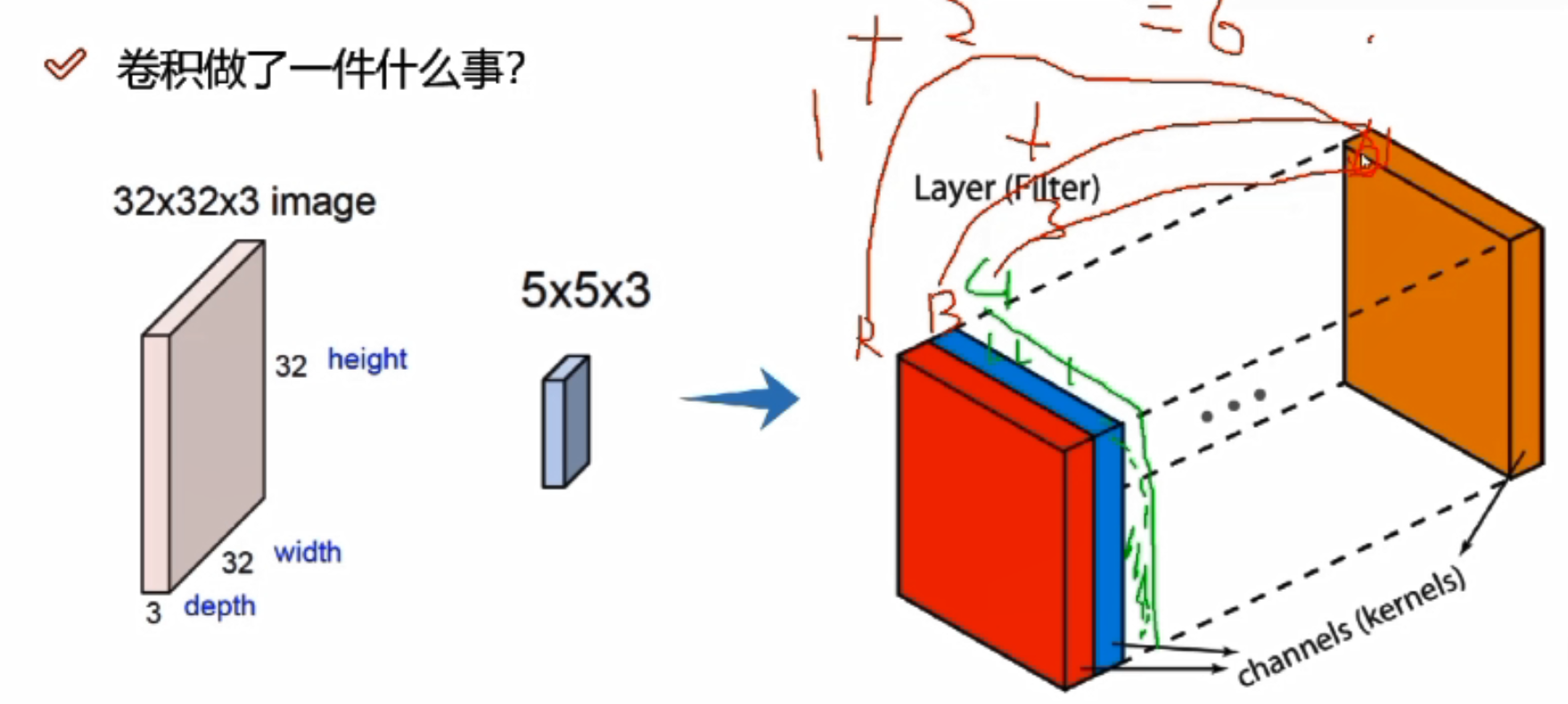
比如三个颜色通道,在对应分割区域上,R/G/B各计算一次,假设R通道对应结果为1,B通道对应结果为2,G通道对应结果为3,则最终结果为1+2+3=6
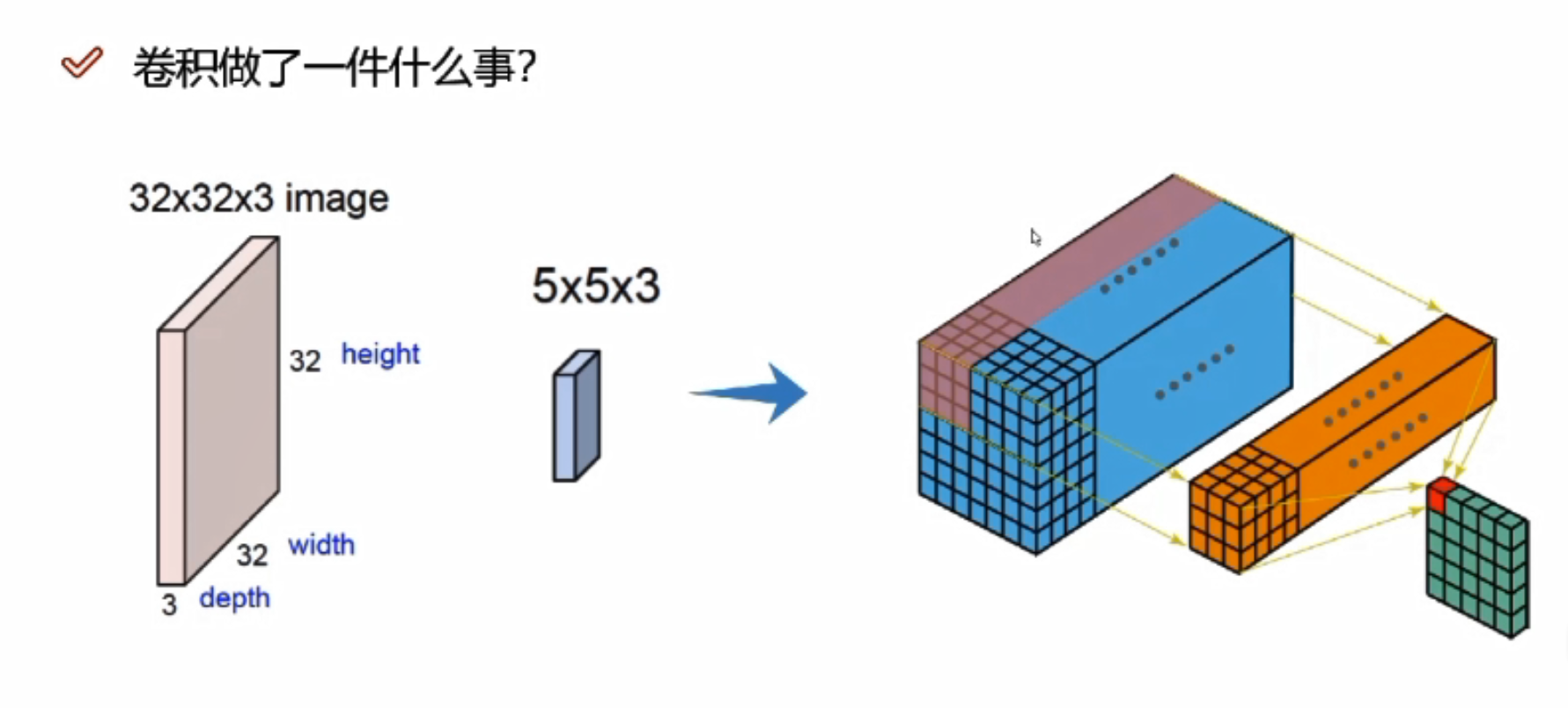
不同的权重参数会得到不同的特征图,可以有很多个

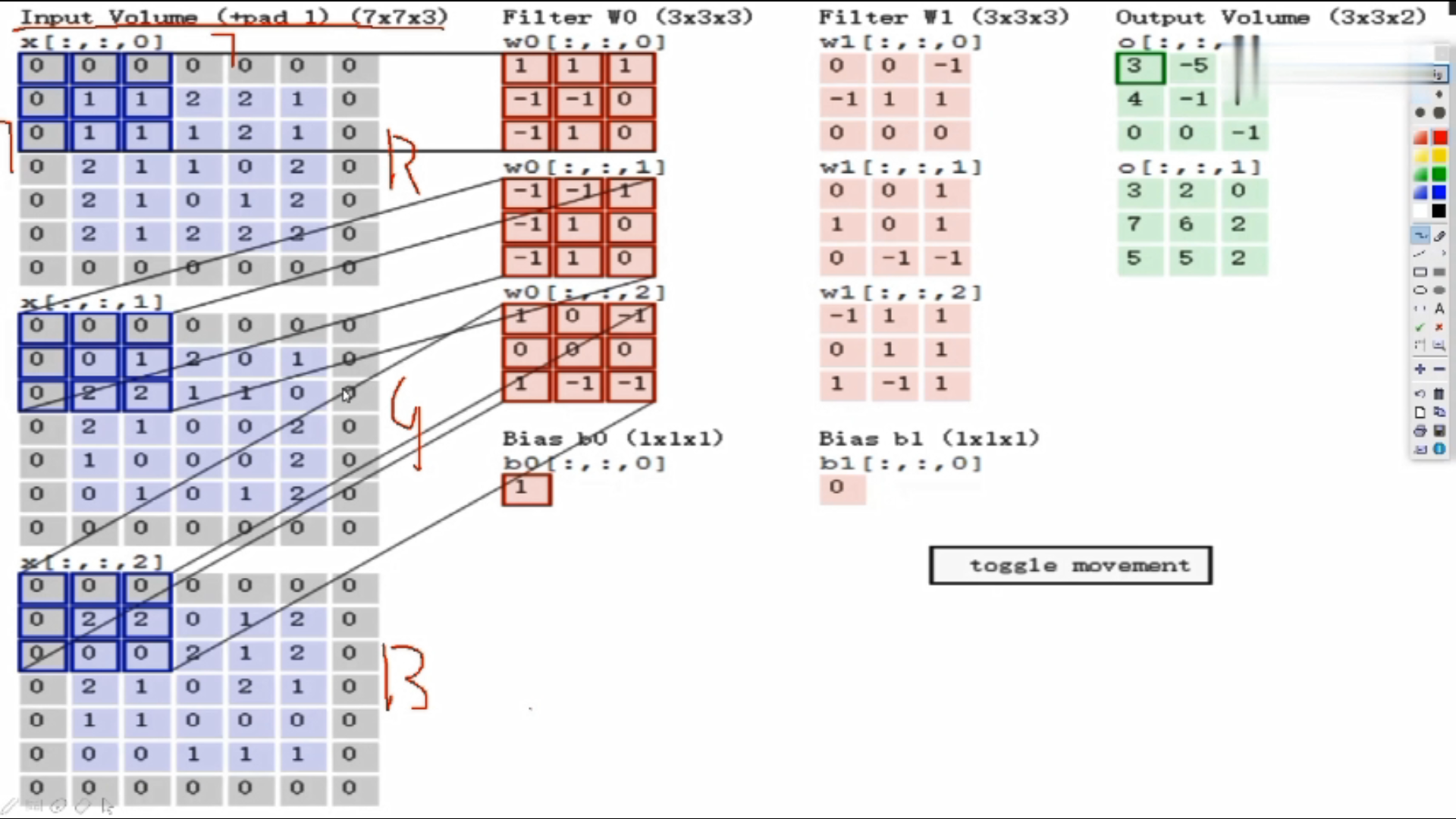
假设输入数据7*7*3
Filter W0:表示随机化一组权重参数,前两个3*3是卷积核,表示选择的区域是3*3的大小,即每3*3的区域选出来一个特征;三个通道的值是不一样的,因为通道不同像素值不同。
计算: 使用内积做计算,即对应位置相乘,所有结果加在一起。 如:上图三个颜色通道的计算内积结果分别为0、2、0,最终结果为三个颜色通道加在一起为0+2+0+b,b为偏置项,此图b=1,所以最终结果为3,即第一个3*3的区域对应的结果为3
Fliter W1:W1与W0规格相同,不同值
绿色图是3*3*2的,2代表深度,即特征图的个数
在第一个区域做完之后,该下一个区域了,往后平移了两格(可以自己设置大小),以此类推
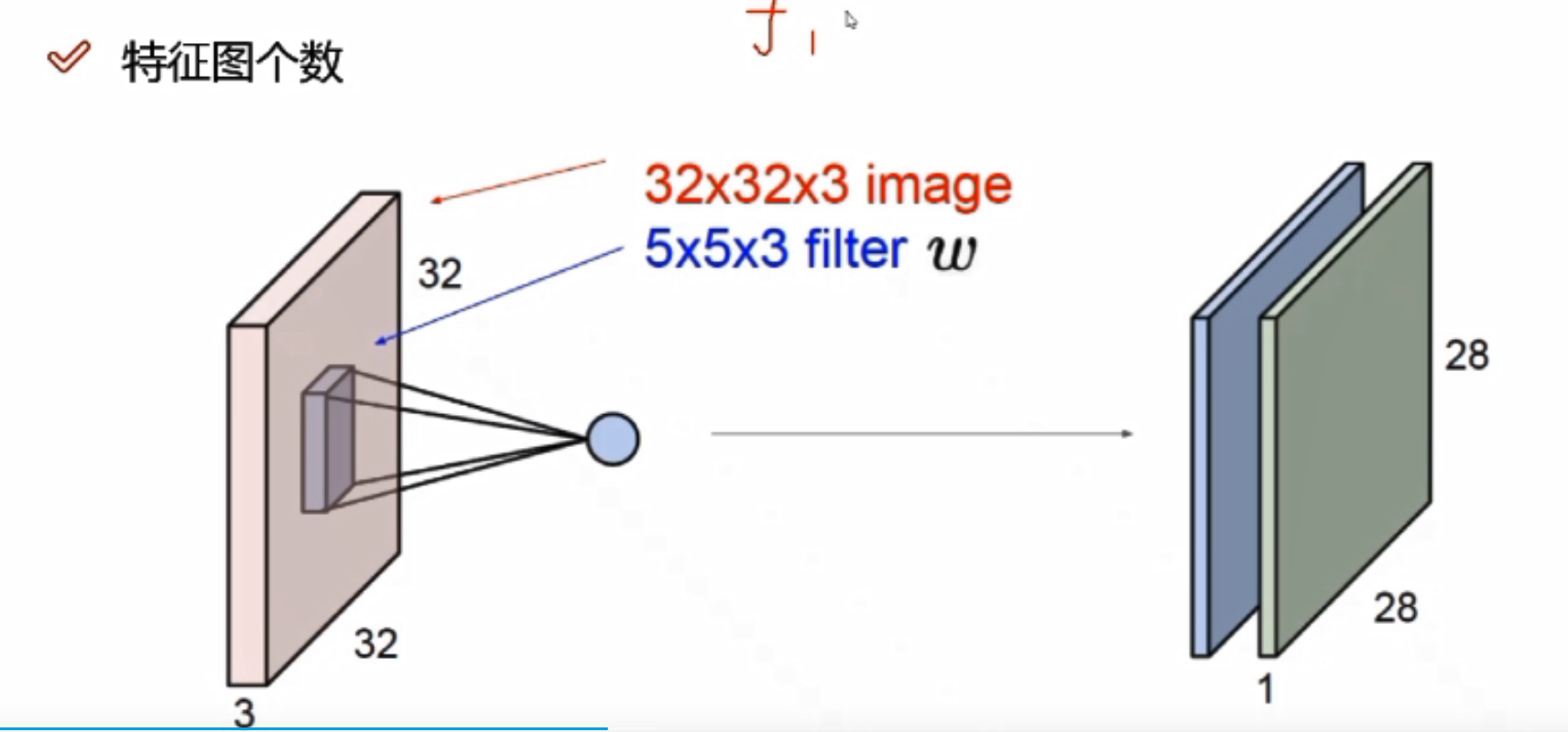
只做一次卷积就可以了吗?
 做一次是不够了,需要好多次
做一次是不够了,需要好多次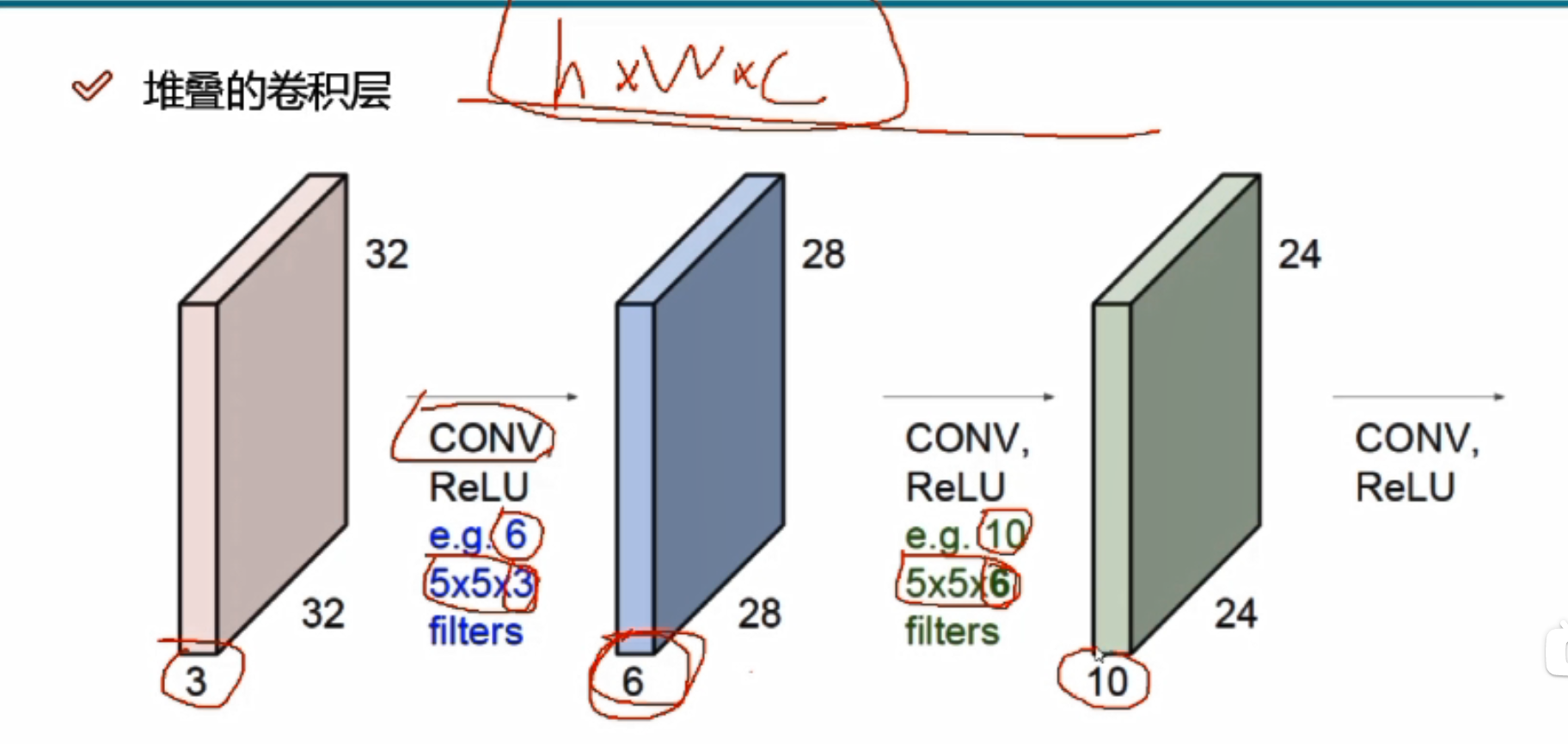
输入:32*32*3
e.g.6代表6个不同的filters,生成的特征图有6层
卷积核深度必须与前一个的输入数据的深度一致
卷积层涉及参数

卷积核步长
步长越小,提取图像特征越细腻,效率也就越慢。一般为1
步长每+1,特征图h与w多减2
卷积核尺寸
3*3的与4*4的区域大小不同,卷积核尺寸越小,提取图像特征越细腻。一般3*3
边缘填充

图像数据越靠近边缘,对特征提取的影响越小,越靠近中间,计算的次数越多,对于特征提取的结果影响越大。边界填充,可以将原来图像的边界置内,可以增大特征提取的程度,一定程度上避免了信息缺失。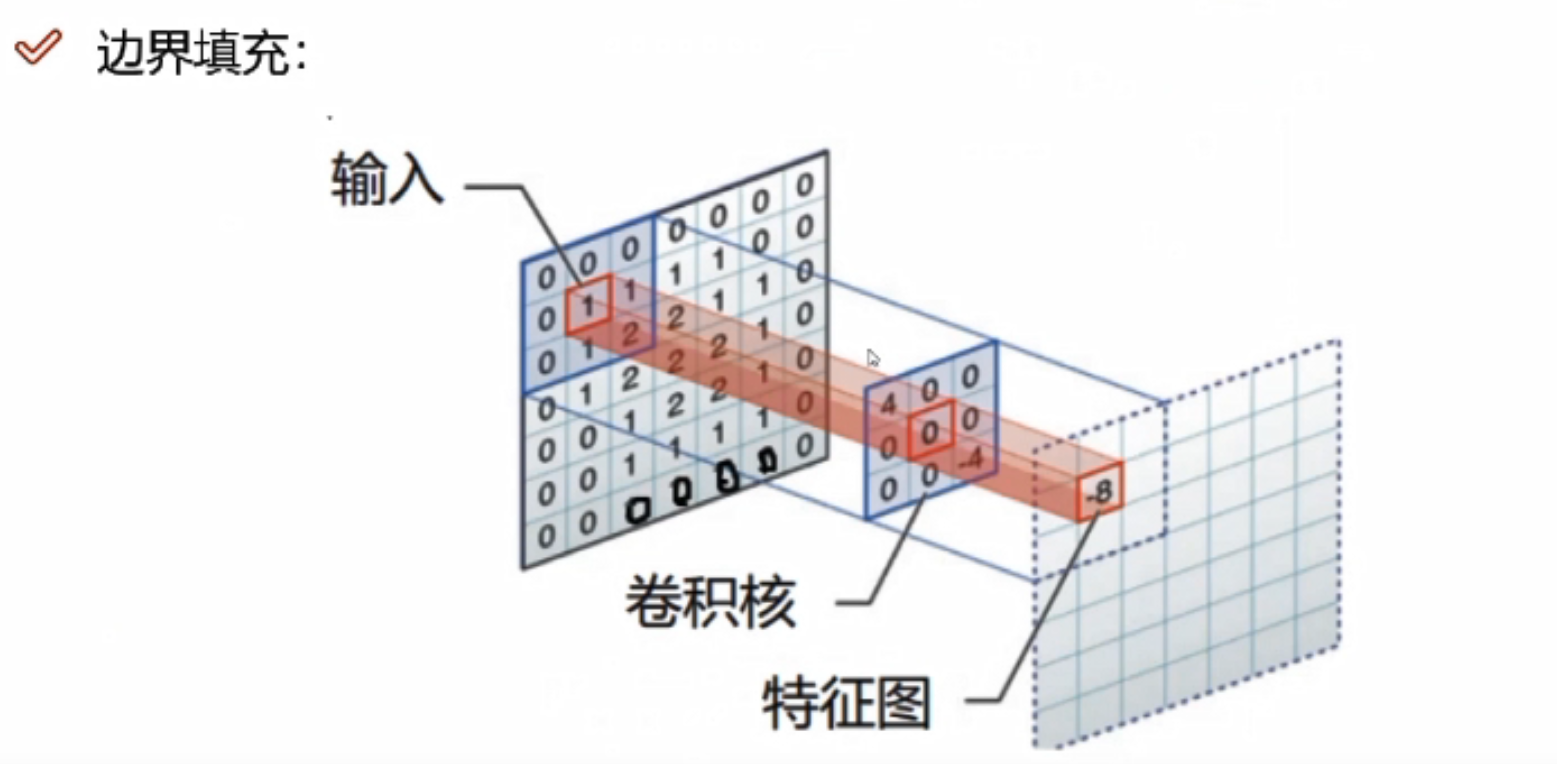
为什么选择加0,而不加其他值?
当添加其他值时,与filter进行计算的时候,会产生一些值,对结果会造成影响
卷积核个数
最终需要得到多少个特征图,卷积核个数就是多少
卷积核结果计算公式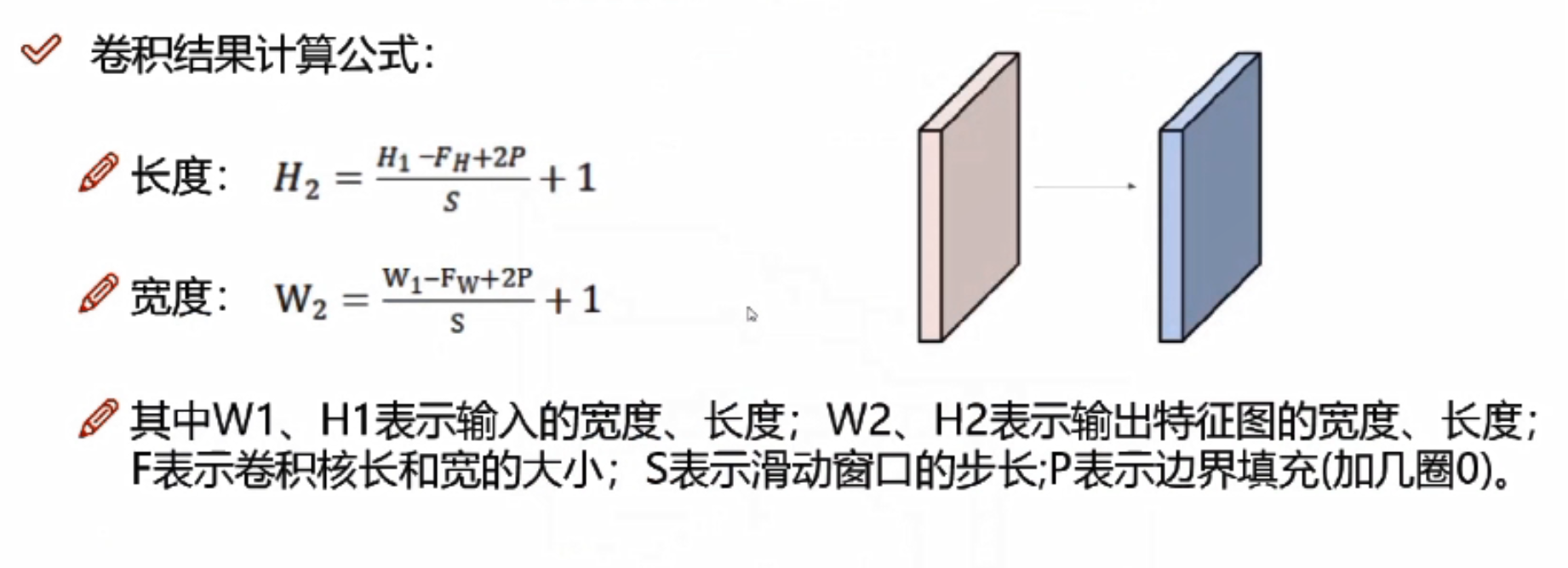
如果输入数据是32*32*3的图像,用10个5*5*3的filter来进行卷积操作,指定步长为1,边界填充为2,最终输出规模为?
(32-5+2*2)/1+1=32,最终输出规模为32*32*10
经过卷积操作后也可以保持特征图长度、宽度不变。
卷积参数共享

池化层
池化层是做压缩的,不涉及任何矩阵计算,只是一个筛选过滤的操作
 h,w变了,但是c不变
h,w变了,但是c不变
最大池化
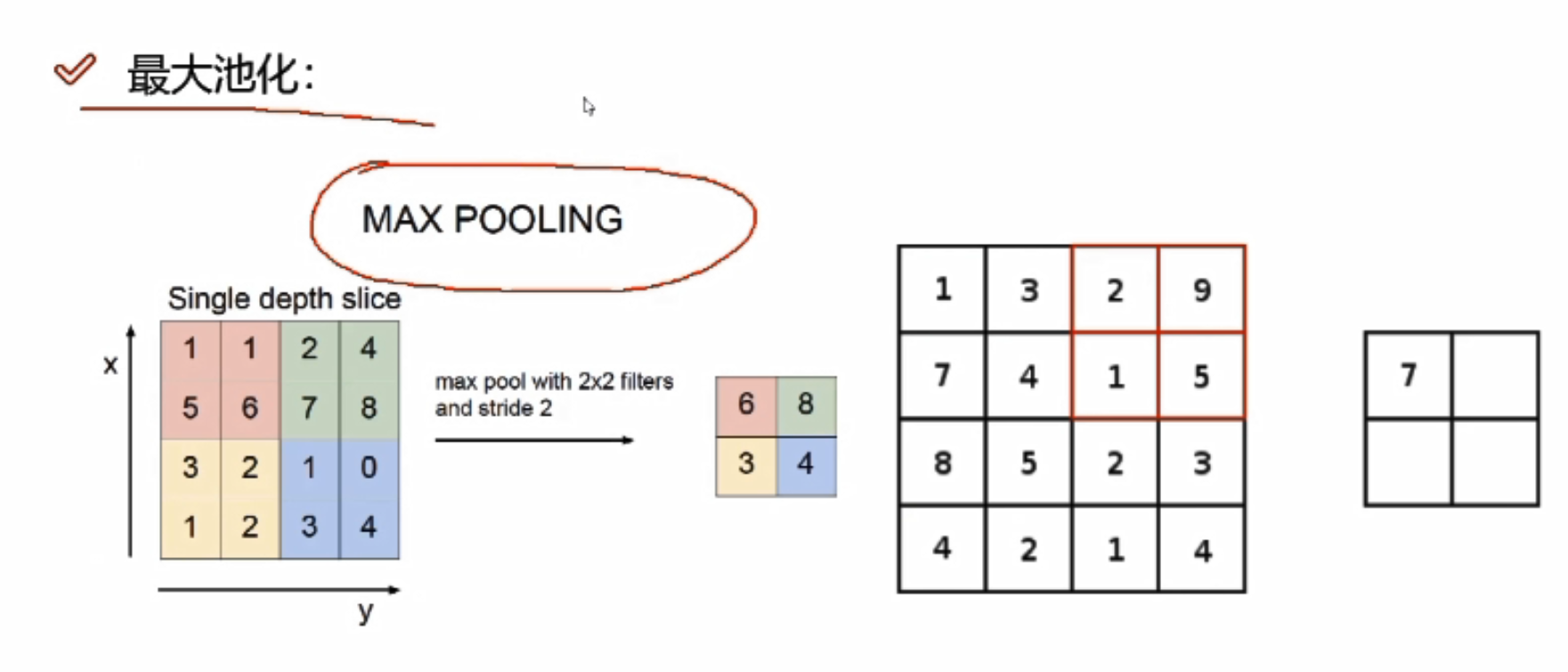
对某一个特征图(4*4)做MAX POOLING,它会先选择不同的区域,每一个区域中选择最大的值
为什么会选择最大的值?
卷积神经网络中,得到的比较大的值往往比较重要
整体架构具体做法

首先卷积进行特征提取,卷积后的RELU,即经过一次卷积之后都需要加上一个非线性变换,两次卷积后做一次池化。
假设最后得到的是32*32*10的特征图,如何进行分类,转换成分类的概率值?
需要全连接层FC,FC将前面经过多次卷积后高度抽象化的特征进行整合,然后可以进行归一化,对各种分类情况都输出一个概率,之后的分类器可以根据全连接得到的概率进行分类。
FC的矩阵大小:[10240,5];五分类所以第二个值是5,FC不能连接三维,所以需要将前面的三维特征图拉成一个特征向量,向量大小为32*32*10=10240。
什么才能称之为一层?该图有几层神经网络?
带参数计算的才能叫做一层,卷积层带,RELU层不带,池化层不带,全连接层也带;所以该图有七层神经网络。
特征图的变化
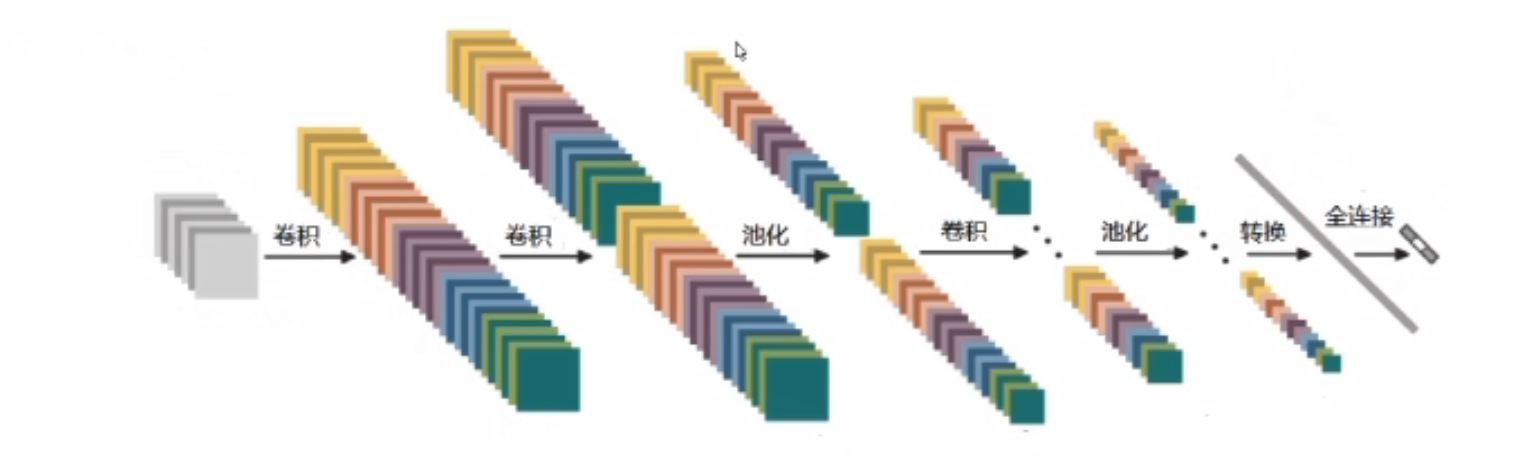
转换:将三维的特征图拉成一个一维的向量
经典网络—Alexnet

- 11*11的filters大刀阔斧,不好,现阶段卷积核越小越好
- stride为4,步长太长;pad为0,不加填充
- 8层网络,5层卷积,3层全连接
经典网络—Vgg

- 所有的卷积大小都是3*3的,细腻
- 有16/19层网络
- 在maxpool后,会损失信息,Vgg在maxpool后会使得特征图翻倍来弥补损失的信息
- Vgg的分类准确度相比Alexnet提升了15%左右,但是训练网络的时间需要比Alexnet长不少
Vgg为什么用到16层? 层越高越好吗?
经过验证,发现16层的效果要比其它层好,因为随着卷积层增加的时候,不一定所有的卷积层做的效果都好,因为是在之前提取的特征基础上再提取特征,不一定比之前提取的特征更好
经典网络—Resnet

问题:56层的错误率是要高于20层的
分析:20层到56层的中间肯定有某些层数做的不好
解决方案: x:卷积当中的某一层,做两次卷积发现效果可能不好,此时额外用一条线把x拿过来,与卷积的结果进行堆叠相加,注意F(x)和x形状要相同,所谓相加是特征矩阵相同位置上的数字进行相加;如果卷积层始终使lose值发生上升,那么网络会使这一层所有的参数学为0,此时还剩下x层。相当于这一层白弄,但至少不会比原来的结果差。
解决效果:
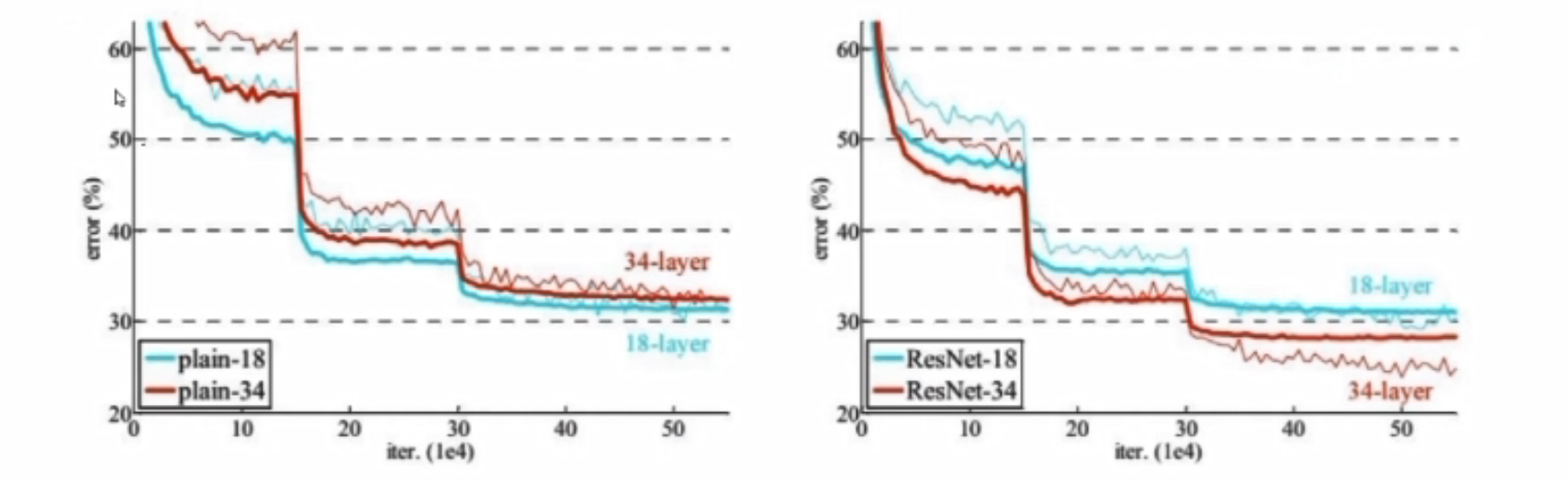
左边是传统网络,右边是Resnet网络;左边层数越高,error值越大,右边层数越高error值越小
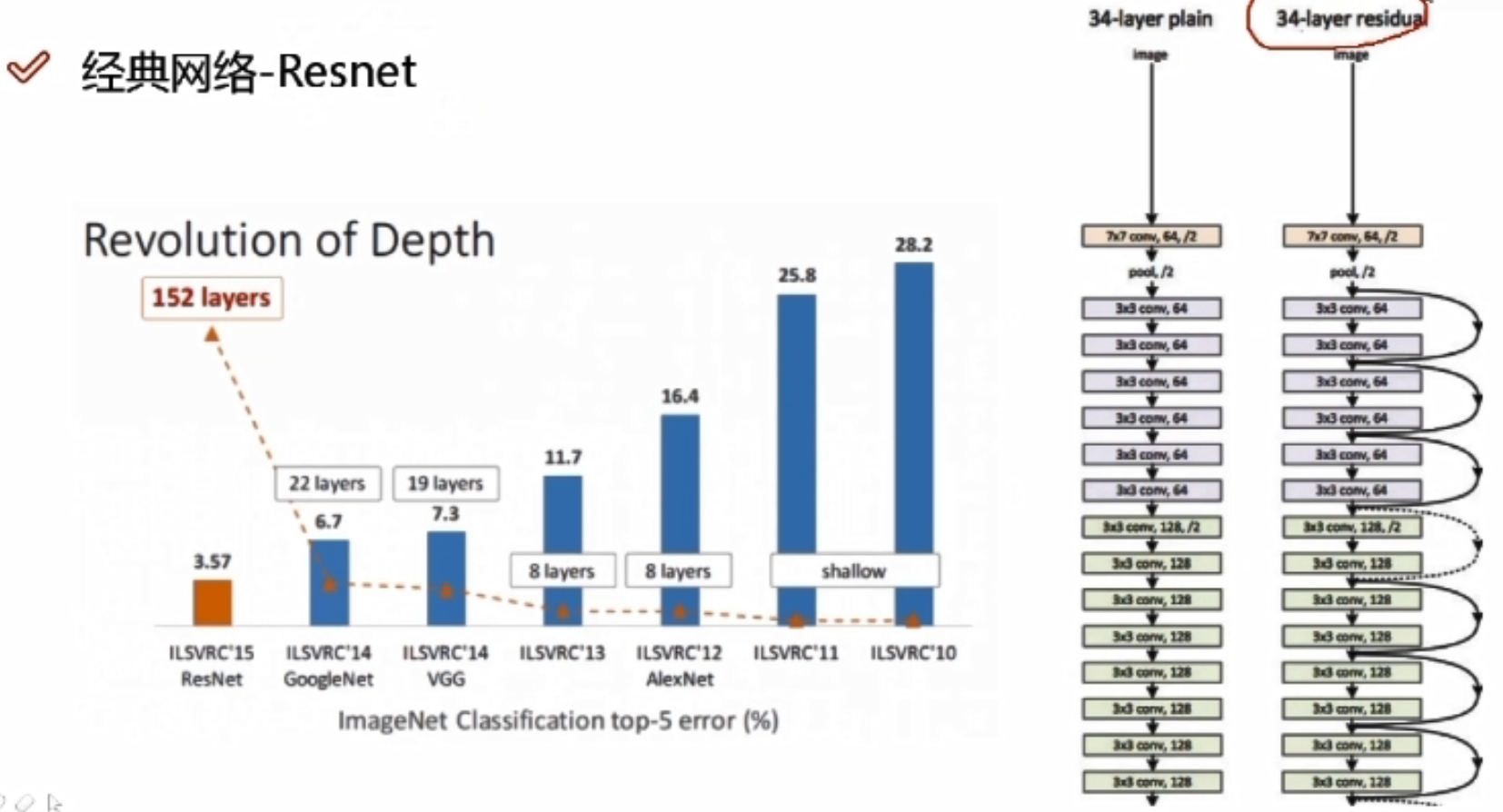 Resnet是一个特征提取,因为一个网络是分类还是回归,取决于损失函数还有最后的层是怎么连的
Resnet是一个特征提取,因为一个网络是分类还是回归,取决于损失函数还有最后的层是怎么连的
感受野
卷积神经网络每一层输出的特征图上的像素点在输入图片上映射的区域大小。
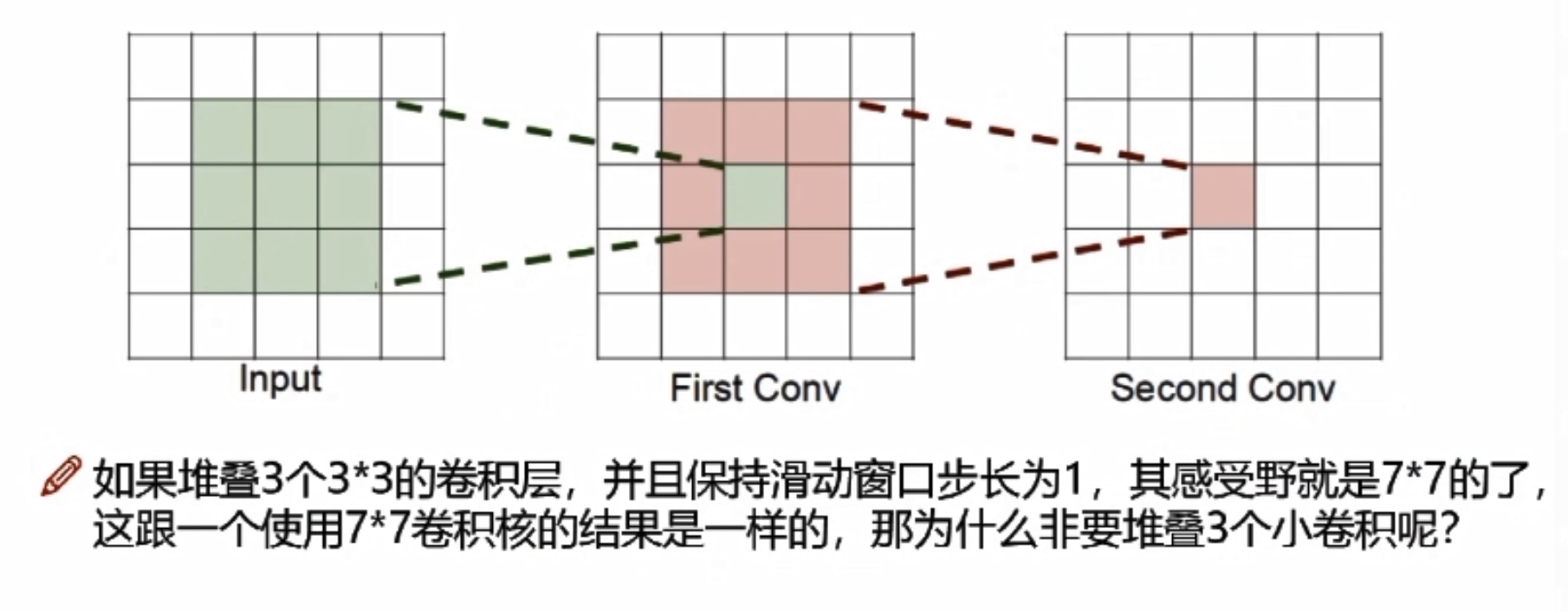

项目实战—基于CNN构建识别模型一
构建卷积神经网络
卷积网络中的输入和层与传统神经网络有些区别,需重新设计,训练模块基本一致
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets,transforms
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
首先读取数据
- 分别构建训练集和测试集(验证集)
- DataLoader来迭代取数据
# 定义超参数
input_size = 28 #图像的总尺寸28*28*1,三维的
num_classes = 10 #标签的种类数
num_epochs = 3 #训练的总循环周期
batch_size = 64 #一个撮(批次)的大小,64张图片
# 训练集
train_dataset = datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
# 测试集
test_dataset = datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor())
# 构建batch数据
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True)
卷积网络模块构建
- 一般卷积层,relu层,池化层可以写成一个套餐
- 注意卷积最后结果还是一个特征图,需要把图转换成向量才能做分类或者回归任务
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28) conv1不是第一个卷积层,而是第一个卷积模块,包括卷积relu池化
nn.Conv2d(
in_channels=1, # 灰度图,当前输入的特征图个数
out_channels=16, # 要得到几多少个特征图
kernel_size=5, # 卷积核大小
stride=1, # 步长
padding=2, # 如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1
), # 输出的特征图为 (16, 28, 28)
nn.ReLU(), # relu层
nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 14, 14)
)
self.conv2 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), #参数的简单写法,与conv1对应。# 输出 (32, 14, 14)
nn.ReLU(), # relu层
nn.MaxPool2d(2), # 输出 (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # 全连接层得到的结果
def forward(self, x): #前向传播
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 32 * 7 * 7)
output = self.out(x)
return output准确率作为评估标准
def accuracy(predictions, labels):
pred = torch.max(predictions.data, 1)[1]
rights = pred.eq(labels.data.view_as(pred)).sum()
return rights, len(labels) 训练网络模型
# 实例化
net = CNN()
#损失函数
criterion = nn.CrossEntropyLoss()
#优化器
optimizer = optim.Adam(net.parameters(), lr=0.001) #定义优化器,普通的随机梯度下降算法
#开始训练循环
for epoch in range(num_epochs):
#当前epoch的结果保存下来
train_rights = []
for batch_idx, (data, target) in enumerate(train_loader): #针对容器中的每一个批进行循环
net.train()
output = net(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
right = accuracy(output, target)
train_rights.append(right)
if batch_idx % 100 == 0:
net.eval()
val_rights = []
for (data, target) in test_loader:
output = net(data)
right = accuracy(output, target)
val_rights.append(right)
#准确率计算
train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))
print('当前epoch: {} [{}/{} ({:.0f}%)]\t损失: {:.6f}\t训练集准确率: {:.2f}%\t测试集正确率: {:.2f}%'.format(
epoch, batch_idx * batch_size, len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.data,
100. * train_r[0].numpy() / train_r[1],
100. * val_r[0].numpy() / val_r[1]))项目实战—基于CNN构建识别模型二
图像识别实战常用模块解读
数据预处理部分
- 数据增强:torchvision中transforms模块自带功能,比较实用
- 数据预处理:torchvision中transforms也帮我们实现好了,直接调用即可
- DataLoader模块直接读取batch数据
网络模块设置
- 加载预训练模型,torchvision中有很多经典网络架构,调用起来十分方便,并且可以用人家训练好的权重参数来继续训练,也就是所谓的迁移学习
- 需要注意的是别人训练好的任务跟咱们的可不是完全一样,需要把最后的head层改一改,一般也就是最后的全连接层,改成咱们自己的任务
- 训练时可以全部重头训练,也可以只训练最后咱们任务的层,因为前几层都是做特征提取的,本质任务目标是一致的
网络模型保存与测试
- 模型保存的时候可以带有选择性,例如在验证集中如果当前效果好则保存
- 读取模型进行实际测试

import os
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import torch
from torch import nn
import torch.optim as optim
import torchvision
#需要先安装pip install torchvision,安装后就可以用里面的三大模块了
from torchvision import transforms, models, datasets
#https://pytorch.org/docs/stable/torchvision/index.html
import imageio
import time
import warnings
import random
import sys
import copy
import json
from PIL import Image数据读取与预处理操作
data_dir = './flower_data/'
train_dir = data_dir + '/train'
valid_dir = data_dir + '/valid'制作好数据源
- data_transforms中指定了所有图像预处理操作
- ImageFolder假设所有的文件按文件夹保存好,每个文件夹下面存贮同一类别的图片,文件夹的名字为分类的名字
>> 数据增强
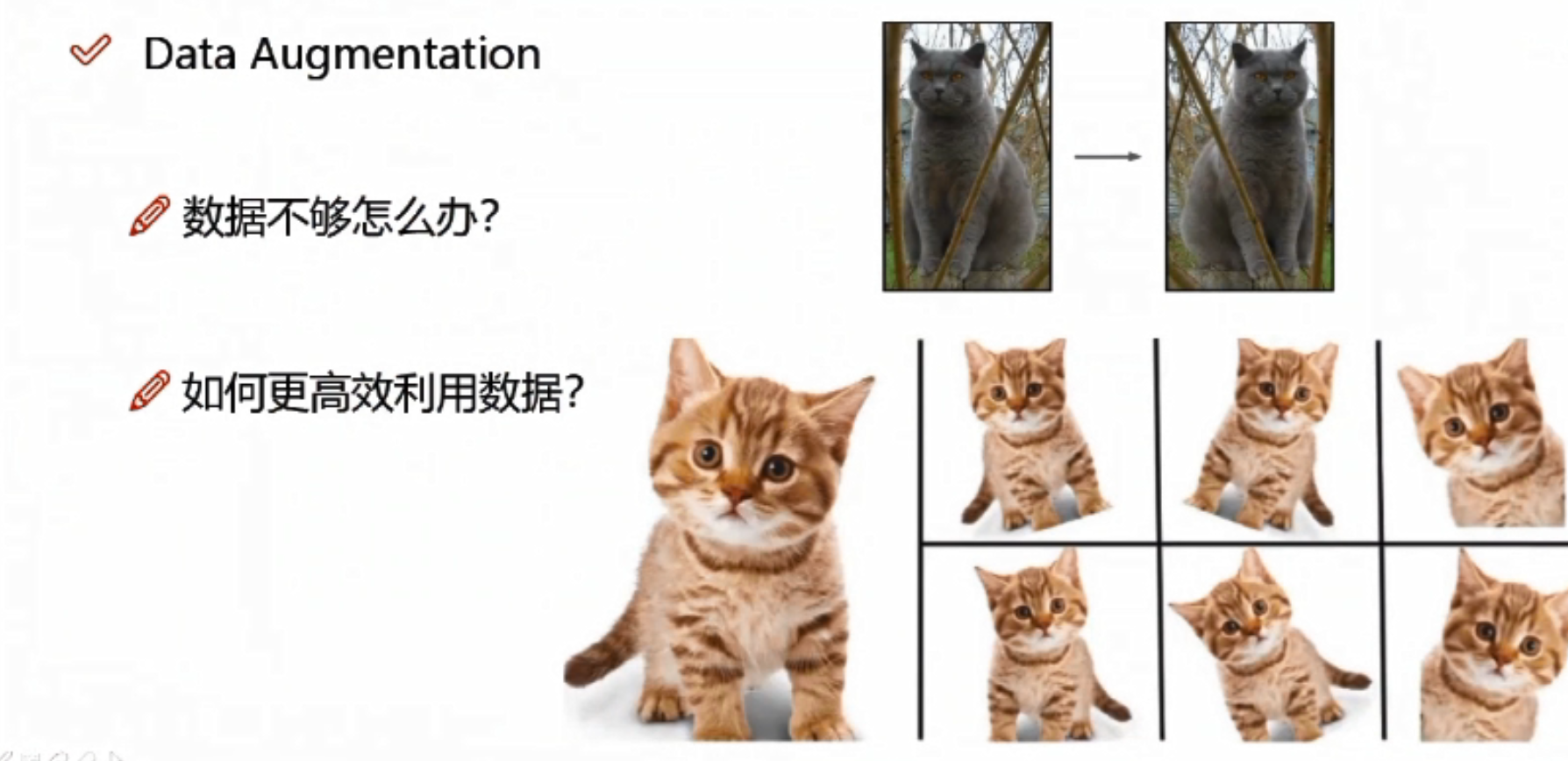
数据不够,可以将原图像进行翻转、旋转、放大、缩小,得到更多的数据
data_transforms = {#训练集做数据增强
'train': transforms.Compose([transforms.RandomRotation(45),#随机旋转,45是-45到45度之间随机选
transforms.CenterCrop(224),#从中心开始裁剪(非随机),留下224*244的大小区域
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 p=0.5,有50%的概率进行翻转,50%概率不动,一般情况下都是0.5
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#标准化: 均值,标准差 (减均值/标准差)
]),
#验证集不需要数据增强了
'valid': transforms.Compose([transforms.Resize(256), #做验证的时候需要resize
transforms.CenterCrop(224),#中心裁剪
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#标准化
]), #训练集是怎么做预处理的验证集也需要怎么做预处理
}
batch_size = 8#显存不够可调小
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']} #datasets.ImageFolder(实际路径,刚才的预处理方法)
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True) for x in ['train', 'valid']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'valid']}
class_names = image_datasets['train'].classes读取标签对应的实际名字
with open('cat_to_name.json', 'r') as f:
cat_to_name = json.load(f)展示下数据
- 注意tensor的数据需要转换成numpy的格式,而且还需要还原回标准化的结果
def im_convert(tensor):
""" 展示数据"""
image = tensor.to("cpu").clone().detach()
image = image.numpy().squeeze()
image = image.transpose(1,2,0) #将H W C还原回去
image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406))#还原标准化,先乘再加
image = image.clip(0, 1)
return image
fig=plt.figure(figsize=(20, 12))
columns = 4
rows = 2
dataiter = iter(dataloaders['valid']) #一组batch数据
inputs, classes = dataiter.next()
for idx in range (columns*rows):
ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])
ax.set_title(cat_to_name[str(int(class_names[classes[idx]]))])
plt.imshow(im_convert(inputs[idx]))
plt.show()

>>迁移学习
训练网络的过程中,可能会遇到各种各样的问题
- 可能手里数据不多,会导致模型过拟合,结果可能不好——做数据增强
- 训练网络模型,需要调节各种各样的参数,花费时间多
- 训练一个模型,需要花费的时间太多了
这里就需要用到迁移学习
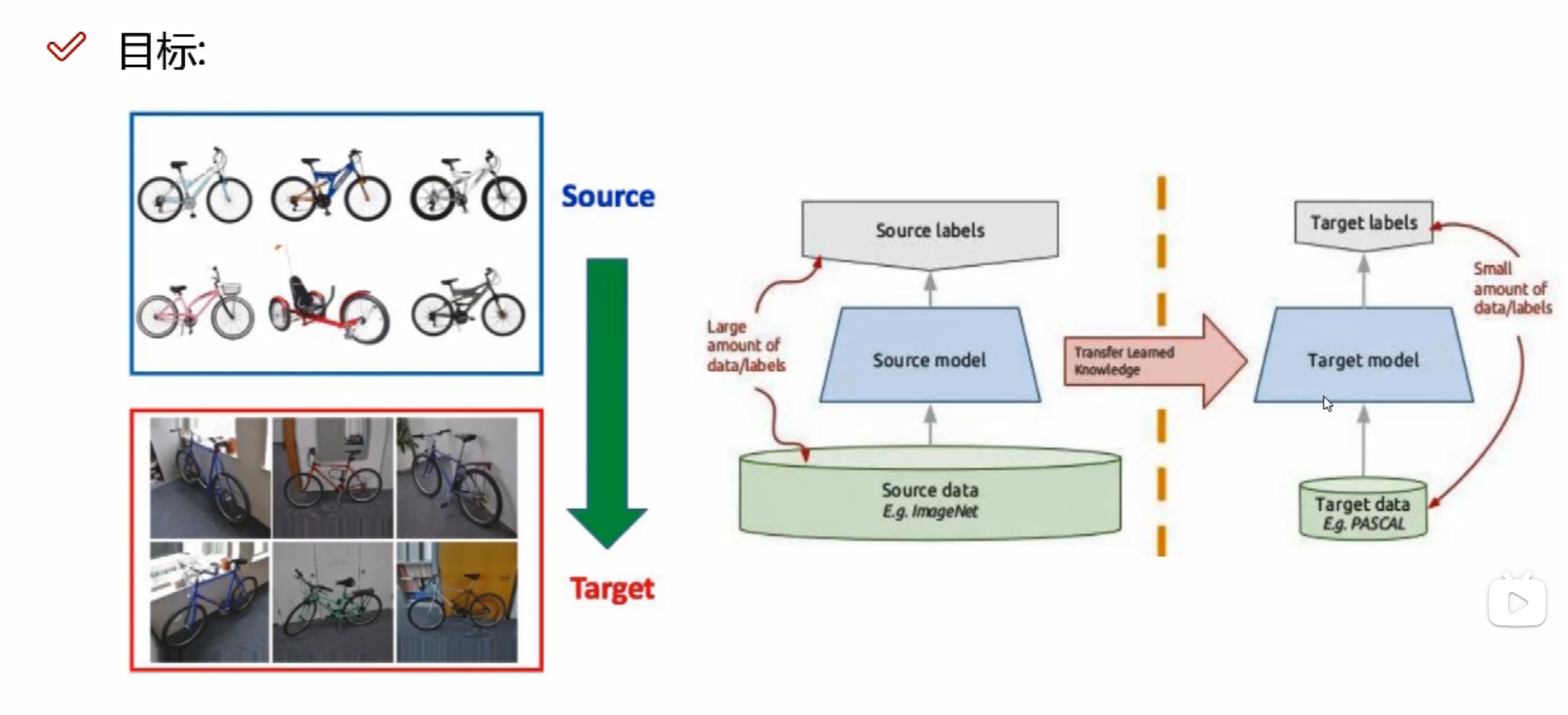 自己的数据不够多,可以借助别人的模型,用别人训练好的权重参数和偏置参数
自己的数据不够多,可以借助别人的模型,用别人训练好的权重参数和偏置参数
但是 需要保证自己的所有结构、输入和输出的格式与别人的一致
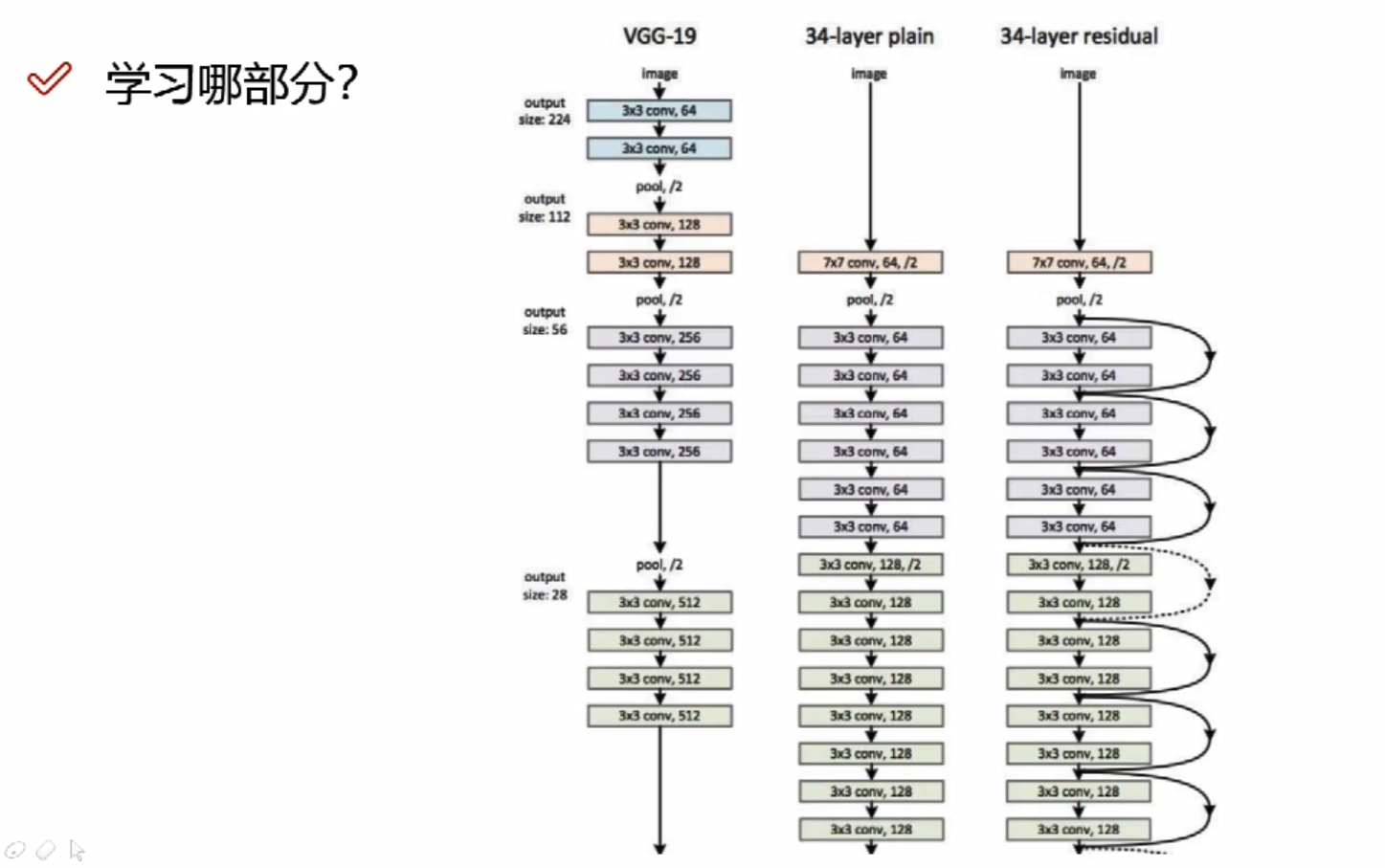
对于前面的层 通常有两种方案:
- A:将别人的卷积层拿过来当做自己的权重参数初始化,然后继续进行训练
- B:将别人的卷积层拿过来冻住,保持不变,把权重参数当做自己的结果
数据量小,需要冻住的层数多;数据量中等,可以冻前面的层数;数据量大,可以选择不冻 ;
全连接层通常用自己的方式进行新的定义,重新训练
加载models中提供的模型,并且直接用训练的好权重当做初始化参数
model_name = 'resnet' #可选的比较多 ['resnet', 'alexnet', 'vgg', 'squeezenet', 'densenet', 'inception']
#是否用人家训练好的特征来做
feature_extract = True
# 是否用GPU训练
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:
print('CUDA is not available. Training on CPU ...')
else:
print('CUDA is available! Training on GPU ...')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#迁移学习
def set_parameter_requires_grad(model, feature_extracting): #要不要把某些层冻住,参数不用训练了
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
model_ft = models.resnet152()
model_ft
参考pytorch官网例子
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
# 选择合适的模型,不同模型的初始化方法稍微有点区别
model_ft = None
input_size = 0
if model_name == "resnet":
""" Resnet152
"""
model_ft = models.resnet152(pretrained=use_pretrained) #pretrained 是否下载用人家的模型
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features #返回原来模型的全连接层2048
model_ft.fc = nn.Sequential(nn.Linear(num_ftrs, 102),
nn.LogSoftmax(dim=1)) #加一个全连接层2048*102
input_size = 224
elif model_name == "alexnet":
""" Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg16(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
# Handle the auxilary net
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# Handle the primary net
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model name, exiting...")
exit()
return model_ft, input_size设置哪些层需要训练
model_ft, input_size = initialize_model(model_name, 102, feature_extract, use_pretrained=True) #要不要冻住一些层,要不要用人家的model
#GPU计算
model_ft = model_ft.to(device)
# 模型保存
filename='checkpoint.pth'
# 是否训练所有层
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:
params_to_update = []
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t",name)
else:
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t",name)model_ft#改完后,打印网络架构,看最后优化器设置
# 优化器设置
optimizer_ft = optim.Adam(params_to_update, lr=1e-2)
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)#学习率每7个epoch衰减成原来的1/10
#最后一层已经LogSoftmax()了,所以不能nn.CrossEntropyLoss()来计算了,nn.CrossEntropyLoss()相当于logSoftmax()和nn.NLLLoss()整合
criterion = nn.NLLLoss()训练模块
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False,filename=filename): #模型、一个一个batch取数据、损失函数、优化器、训练多少epoch、要不要用其他的网络、
since = time.time()
best_acc = 0 #保存一个最好的准确率
"""
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
model.class_to_idx = checkpoint['mapping']
"""
model.to(device)
val_acc_history = []
train_acc_history = []
train_losses = []
valid_losses = []
LRs = [optimizer.param_groups[0]['lr']] #学习率
best_model_wts = copy.deepcopy(model.state_dict()) #最好的一次存下来
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 训练和验证
for phase in ['train', 'valid']:
if phase == 'train':
model.train() # 训练
else:
model.eval() # 验证
running_loss = 0.0
running_corrects = 0
# 把数据都取个遍
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device) #传到GPU当中
labels = labels.to(device)
# 清零
optimizer.zero_grad()
# 只有训练的时候计算和更新梯度
with torch.set_grad_enabled(phase == 'train'):
if is_inception and phase == 'train':
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4*loss2
else:#resnet执行的是这里
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# 训练阶段更新权重
if phase == 'train':
loss.backward()
optimizer.step()
# 计算损失
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
time_elapsed = time.time() - since
print('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# 得到最好那次的模型
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
state = {
'state_dict': model.state_dict(),
'best_acc': best_acc,
'optimizer' : optimizer.state_dict(),
}
torch.save(state, filename)
if phase == 'valid':
val_acc_history.append(epoch_acc)
valid_losses.append(epoch_loss)
scheduler.step(epoch_loss)
if phase == 'train':
train_acc_history.append(epoch_acc)
train_losses.append(epoch_loss)
print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))
LRs.append(optimizer.param_groups[0]['lr'])
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# 训练完后用最好的一次当做模型最终的结果
model.load_state_dict(best_model_wts)
return model, val_acc_history, train_acc_history, valid_losses, train_losses, LRs 代码参考:PyTorch 图像识别实战_我是小白呀的博客-CSDN博客_pytorch 识别
相关文章:

Building wheel for mmcv-full (setup.py) ... error解决办法!
mmdetection 安装后,根据官方给的程序安装mmcv时,出现:Building wheel for mmcv-full (setup.py) … error 环境:CUDA11.3, Pytorch1.11 安装根据官网给的安装程序:pip install mmcv-full -f https://download.openmm…...
联邦学习开山之作代码解读与收获
参考:联邦学习代码解读,超详细_一只揪的博客-CSDN博客_联邦学习代码 参考文献:[1602.05629] Communication-Efficient Learning of Deep Networks from Decentralized Data (arxiv.org) 参考代码:GitHub - AshwinRJ/Federated-L…...
Python安装第三方库常用方法 超详细~
Python安装第三方库常用方法前言安装方法1. 通过pychram安装2. pip安装大法3. 下载whl文件到本地离线安装3.1 补充4.其他方法4.1 Python官方的Pypi菜单4.2 国内镜像源解决pip安装过慢的问题小结前言 在pyhton的学习中,相信大家通常都会碰到第三方库的安装问题&…...
Python--找出字符串中出现次数最多的字符及其出现的次数
方法一: 1、循环遍历列表或字符串,如果字符在字典中则值加1,如果不在则创建(key,value) 2、找到字典中,最大的value值 3、根据最大的value值,找对应的key值,打印出出现次数最多的字符 str &qu…...

滤波笔记一:卡尔曼滤波(Kalman Filtering)详解
本笔记是总结了B站DR_CAN的卡尔曼滤波器的课程,他的B站主页为:DR_CAN的个人空间_哔哩哔哩_bilibili PS:虽然我不是学自控的,但是老师真的讲的很好! 目录 Lesson1 递归算法 Lesson2 数学基础_数据融合_协方差矩阵_状态空间方程…...
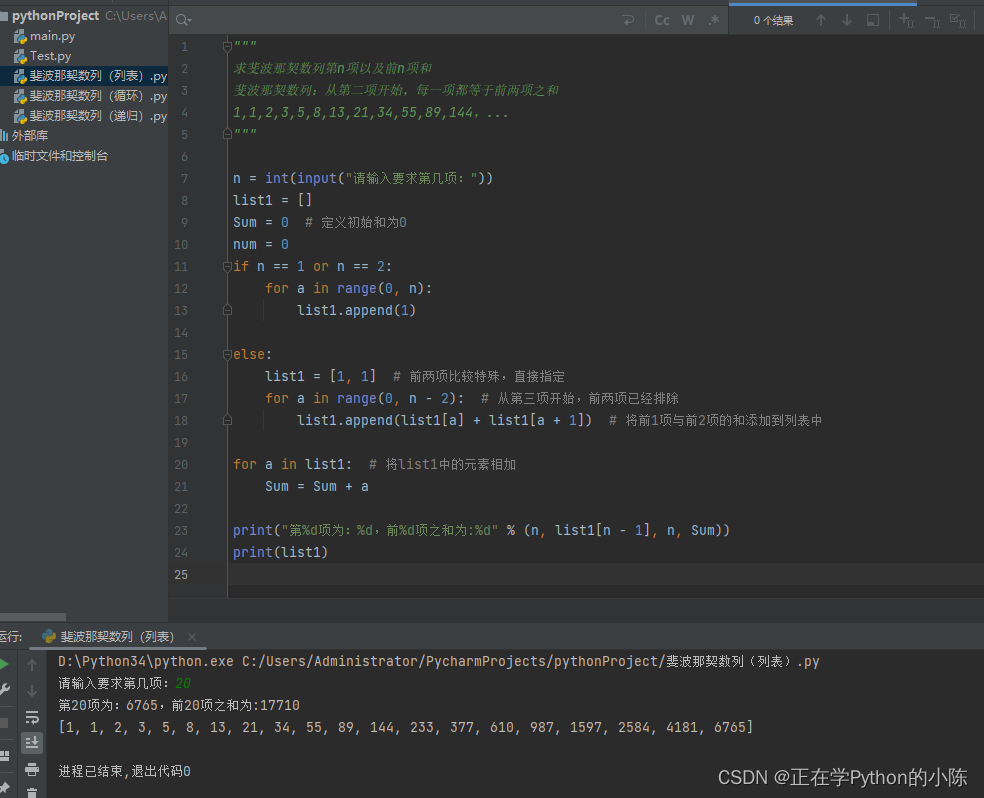
利用Python求斐波那契数列的第N项以及前N项和(循环、递归、集合)
著名的斐波那契数列,即从第三项开始,每一项都等于前两项之和。 之前写过利用Java语言来编写,由于最近正在学Python,所以将自己的想法记录在此,有需要的朋友可以参考一下。 写在前面:这里的三个方法其实思…...
一文速学(十八)-数据分析之Pandas处理文本数据(str/object)各类操作+代码一文详解(三)
目录 前言 一、子串提取 提取匹配首位子串 提取所有匹配项(extractall)...
Python数据分析-数据预处理
数据预处理 文章目录数据预处理1.前言2.数据探索2.1缺失值分析2.2 异常值分析2.2.1 简单统计量分析2.2.2 3$\sigma$原则2.2.3 箱线图分析2.3 一致性分析2.4 相关性分析3.数据预处理3.1 数据清洗3.1.1 缺失值处理3.1.2 异常值处理3.2 数据集成3.2.1 实体识别3.2.2 冗余属性识别3…...
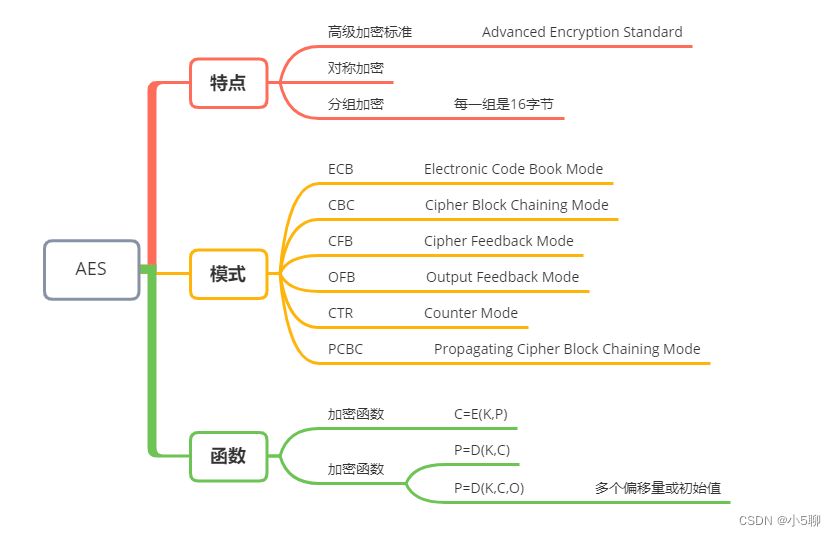
【Python】AES加解密代码,文章还有加密串等你来解密,等你来挑战
🍦🍦写这篇AES文章也是有件趣事,有位小伙伴发了段密文,看看谁解密速度快,学过Python的小伙伴一下子就解开来了,内容也挺有趣的。 🍟🍟原来加解密也可以这么有趣,虽然看起…...
朴素贝叶斯模型及案例(Python)
目录 1 朴素贝叶斯的算法原理 2 一维特征变量下的贝叶斯模型 3 二维特征变量下的贝叶斯模型 4 n维特征变量下的贝叶斯模型 5 朴素贝叶斯模型的sklearn实现 6 案例:肿瘤预测模型 6.1 读取数据与划分 6.1.1 读取数据 6.1.2 划分特征变量和目标变量 6.2 模型…...
python之Tkinter详解
Python之Tkinter详解 文章目录Python之Tkinter详解1、Tkinter是什么2、Tkinter创建窗口①导入 tkinter的库 ,创建并显示窗口②修改窗口属性③创建按钮④窗口内的组件布局3、Tkinter布局用法①基本界面、label(标签)和button(按钮)用法②entry(输入)和text(文本)用法…...

【python】python进行debug操作
文章目录前言一、debug环境介绍二、debug按钮介绍2.1、step into:单步执行(遇到函数也是单步)2.2、step over:单步执行(遇到函数,全部运行)2.3、step into my code:(直接跳到下一个断点)2.4、st…...

Python安装tensorflow过程中出现“No matching distribution found for tensorflow”的解决办法
在Pycharm中使用pip install tensorflow安装tensorflow时报错: ERROR: Could not find a version that satisfies the requirement tensorflow(from versions: none) ERROR: No matching distribution found for tensorflow搜了好多帖子有的说可能是网络的问题&…...

pandas中的read_csv参数详解
1.官网语法 pandas.read_csv(filepath_or_buffer, sepNoDefault.no_default**,** delimiterNone**,** headerinfer’, namesNoDefault.no_default**,** index_colNone**,** usecolsNone**,** squeezeFalse**,** prefixNoDefault.no_default**,** mangle_dupe_colsTrue**,** dty…...
Python — — turtle 常用代码
目录 一、设置画布 二、画笔 1、画笔属性 2、绘图命令 (1) 画笔运动命令 (2) 画笔控制命令 (3) 全局控制命令 (4) 其他命令 3. 命令详解 三、文字显示为一个圆圈 四、画朵小花 一、设置画布 turtle为我们展开用于绘图区域,我们可以设置它的…...

【我是土堆 - PyTorch教程】学习随手记(已更新 | 已完结 | 10w字超详细版)
目录 1. Pytorch环境的配置及安装 如何管理项目环境? 如何看自己电脑cuda版本? 安装Pytorch 2. Python编辑器的选择、安装及配置 PyCharm PyCharm神器 Jupyter(可交互) 3. Python学习中的两大法宝函数 说明 实战操…...
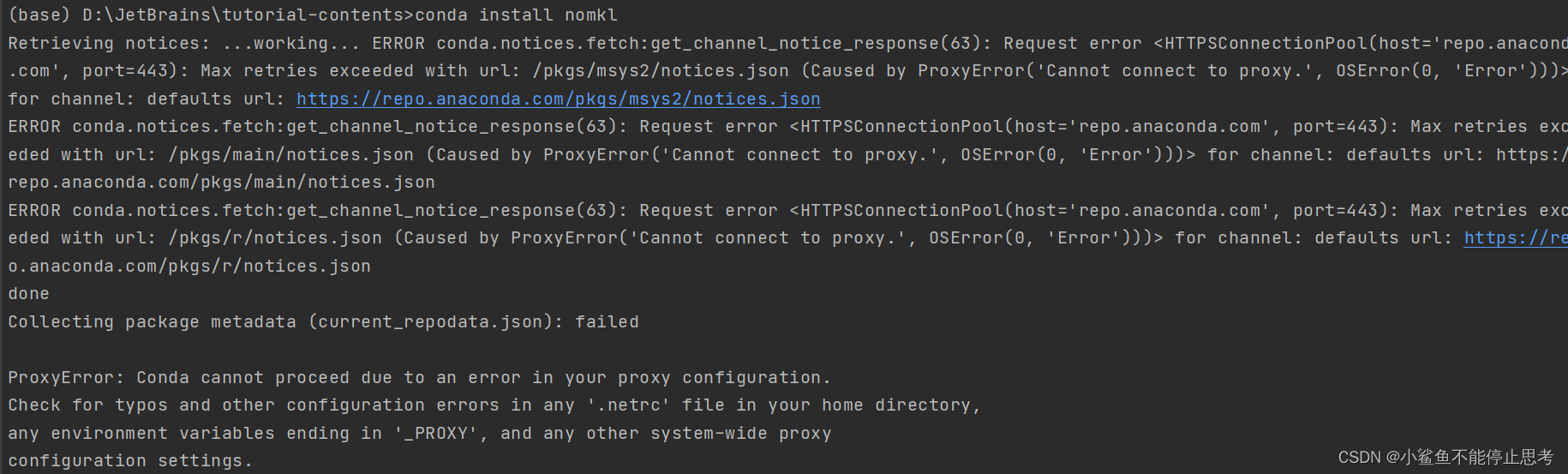
“OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.”解决方法总结
一、问题描述 跑了点神经网络的代码,想画几个激活函数的图像,代码如下: 运行后报了以下错误: 翻译如下: OMP:错误 #15:正在初始化 libiomp5md.dll,但发现 libiomp5md.dll 已经初…...
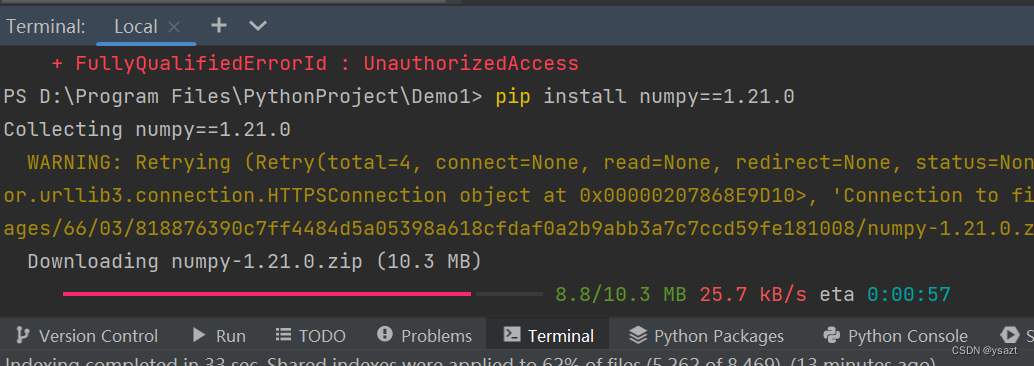
python3.11.2安装 + pycharm安装
下载 :https://www.python.org/ 2.双击下载的软件: 3.进入安装界面 下一步,点击 是 上一步点击后就看到如下: 安装成功了,接下来检测一下:cmd 安装pycharm PyCharm是一种Python IDE(Integr…...
Python中numpy.polyfit的用法详解
numpy中polyfit的用法 参数 polyfit(x, y, deg, rcondNone, fullFalse, wNone, covFalse):x:M个采样点的横坐标数组; y:M个采样点的纵坐标数组;y可以是一个多维数组,这样即可拟合相同横坐标的多个多项式; deg:多项式…...
彻底解决Python包下载慢问题
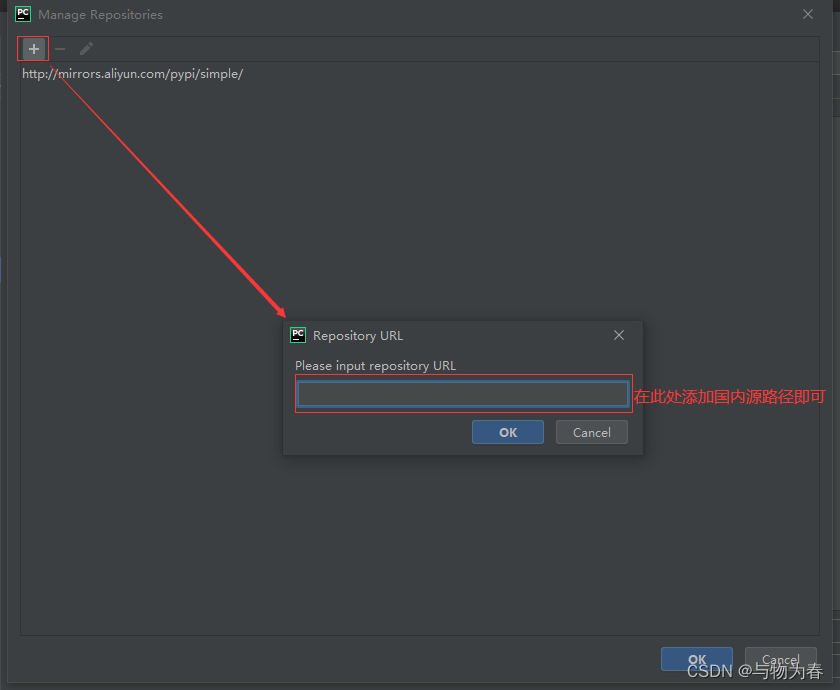
python默认使用的是国外镜像,有时候下载非常慢,最快的办法就是在下载命令中增加国内源: 常用的国内源如下: 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/ 阿里云:http://mirrors.aliyun.com/pypi/…...
Anaconda 使用指南,少走弯路
anaconda包管理器和环境管理器,强烈建议食用 1.下载 官网下载太慢可选用镜像下载 官网下载 :Anaconda | Individual Editionhttps://www.anaconda.com/products/distribution 镜像下载:Index of /anaconda/archive/ | 清华大…...
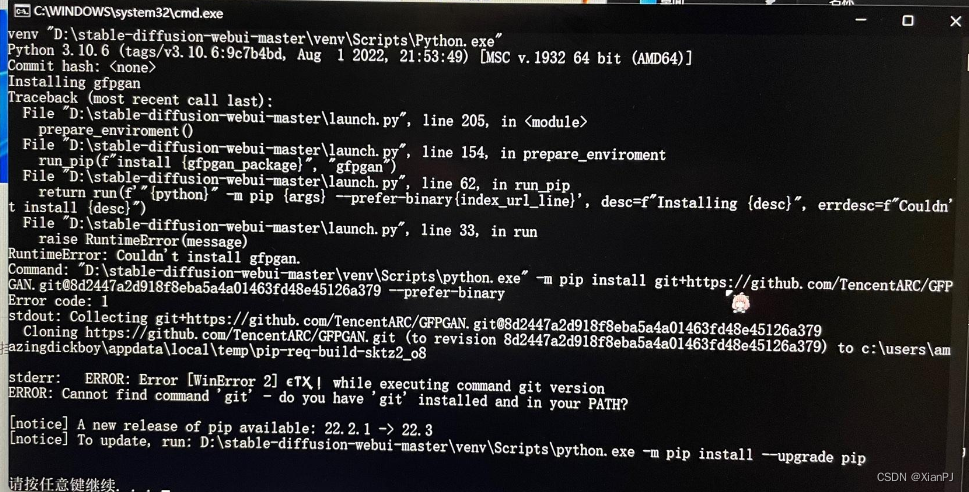
使用stable diffusion webui时,安装gfpgan失败的解决方案(windows下的操作)
1.问题描述 初次打开stable diffusion webui时,需要安装gfpgan等github项目。但在安装gfpgan时,显示RuntimeError: Couldnt install gfpgan 2.解决方案 无法安装gfpgan的原因是网络问题,就算已经科学上网,并设置为全局&#x…...

Python 中导入csv数据的三种方法
这篇文章主要介绍了Python 中导入csv数据的三种方法,内容比较简单,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下微点阅读小编收集的文章介绍。 Python 中导入csv数据的三种方法,具体内容如下所示: 1、通过…...
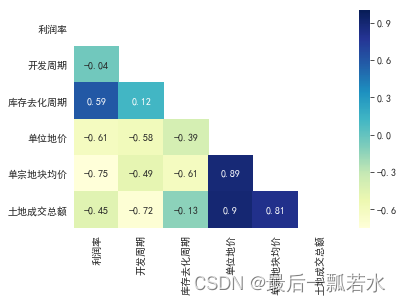
相关性分析、相关系数矩阵热力图
相关性 相关性分析是研究两组变量之间是否具有线性相关关系,所以做相关性分析的前提是假设变量之间存在线性相关性,得到的结果也是描述变量间的线性相关程度。除此之外,相关性分析方法还会有其他的假设条件。而灰色关联度分析首先对数据量要求…...
【python123】题目答案整理 ------更多答案见专栏
目录 二老鼠打洞 来自计算机的问候-任意数量参数 自定义幂函数 来自计算机的问候-多参函数 编写函数输出自除数 最大素数 求数列前n项的平方和 生兔子 计算圆周率——割圆法 数列求前n项和 素数: *如有错误请私聊纠正 二老鼠打洞 nint(input()) # 每日打…...
Python编程题汇总
Python编程复习 1.1找出列表中单词最长的一个 找出列表中单词最长的一个def test():a ["hello", "world", "yoyo", "congratulations"]length len(a[0])# 在列表中循环for i in a:if len(i) > length:length ireturn length p…...
Matplotlib详解
视频教程 1.什么是matplotlib matplotlib: 最流行的Python底层绘图库,主要做数据可视化图表,名字取材于MATLAB,模仿MATLAB构建 2.样例 2.1折线图 eg:假设一天中每隔两个小时(range(2,26,2))的气温(℃)分别是[15,13,14.5,17,20,25,26,26,…...

Jetson AGX Orin安装Anaconda、Cuda、Cudnn、Pytorch、Tensorrt最全教程
文章目录一:Anaconda安装二:Cuda、Cudnn安装三:Pytorch安装四:Tensorrt安装一:Anaconda安装 Jetson系列边缘开发板,其架构都是arm64,而不是传统PC的amd64,深度学习的环境配置方法大…...
pytorch入门篇2 玩转tensor(查看、提取、变换)
上一篇博客讲述了如何根据自己的实际需要在pytorch中创建tensor:pytorch入门篇1——创建tensor,这一篇主要来探讨关于tensor的基本数据变换,是pytorch处理数据的基本方法。 文章目录1 tensor数据查看与提取2 tensor数据变换2.1 重置tensor形状…...

随机森林算法
随机森林1.1定义1.2随机森林的随机性体现的方面1.3 随机森林的重要作用1.4 随机森林的构建过程1.5 随机森林的优缺点2. 随机森林参数描述3. 分类随机森林的代码实现1.1定义 随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法。随机森林非常简单&am…...
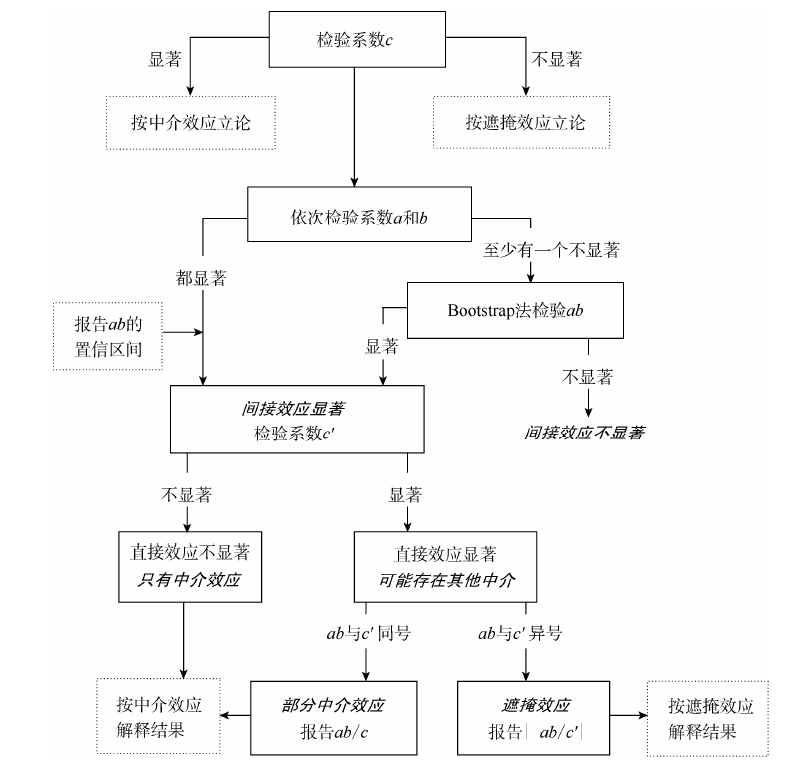
实证分析 | 中介效应检验原理与Stata代码实现
前言 本文是温忠鳞和叶宝娟2014年刊载于《心理科学进展》的论文《中介效应分析:方法和模型发展》的简要笔记与拓展。 温忠麟、叶宝娟:《中介效应分析:方法和模型发展》,《心理科学进展》,2014年第5期 中介效应检验 要…...

几个代码画出漂亮的词云图,python最简单的词云图教程(建议收藏)
在开始编写程序之前,我们先了解一下词云图的作用,我们拿到一篇文章,想得到一些关键词,但文章篇幅很大,无法短时间得到关键词,这时我们可以通过程序将文章中的每个词组识别出来,统计每个词组出现…...

mac m1,m2 安装 提供GPU支持的pytorch和tensorflow
mac m1,m2 安装 提供GPU支持的pytorch和tensorflowAnaconda安装测试Pytorch参考链接安装步骤安装 Xcode创建conda环境测试加速效果注意Tensorflow参考链接安装步骤安装 Xcode指定安装环境加速效果测试The Endmac m1 刚出的时候,各种支持都不完善。那时候要使用conda…...
如何用Python优雅的合并两个Dict
假设有两个dict x和y,合并成一个新的dict,不改变 x和y的值,例如 x {a: 1, b: 2}y {b: 3, c: 4} 期望得到一个新的结果Z,如果key相同,则y覆盖x。期望的结果是 >>> z {a: 1, b: 3, c: 4} 在PEP448中ÿ…...
python读取文件的几种方式
下面是不同场景较为合适的数据读取方法: 1.python内置方法(read、readline、readlines) 纯文本格式或非格式化、非结构化的数据,常用语自然语言处理、非结构文本解析、应用正则表达式等后续应用场景下,Python默认的三…...

python常用模块大全
目录 时间模块time() 与 datetime()random()模块os模块sys模块tarfile用于将文件夹归档成 .tar的文件shutil 创建压缩包,复制,移动文件zipfile将文件或文件夹进行压缩 shelve 模块 json和pickle序列化hashlib 模块subprocess 模块re模块 时间模块time() 与 datetime() time()模…...

成本降低90%,OpenAI正式开放ChαtGΡΤ
今天凌晨,OpenAI官方发布ChαtGΡΤ和Whisper的接囗,开发人员现在可以通过API使用最新的文本生成和语音转文本功能。OpenAI称:通过一系列系统级优化,自去年12月以来,ChαtGΡΤ的成本降低了90%;现在OpenAI用…...

Python:ModuleNotFoundError错误解决
前言: 大家都知道python项目中需要导入各种包(这里的包引鉴于java中的),官话来讲就是Module。 而什么又是Module呢,通俗来讲就是一个模块,当然模块这个意思百度搜索一下都能出来,Python 模块(…...
python案例——利用python画图
1、画直线 问题描述: 利用python中的 turtle (海龟绘图)模块提供的函数绘制直线 算法设计: turtle.penup(): 画笔抬起turtle.color(): 设置颜色turtle.goto(): 画笔移动到下一目标turtle.pendown(): …...

pandas.DataFrame设置某一行为表头(列索引),设置某一列为行索引,按索引取多行多列
pandas读取文件 pandas.DataFrame 设置索引 pandas.DataFrame 读取单行/列,多行多列 pandas.DataFrame 添加行/列 利用pandas处理表格类型数据,快捷方便,不常用但是有的时候又是必要技能,在这里记录一下一些常用函数和自己的踩坑…...

主成分分析(PCA)算法模型实现及分析(MATLAB实现)PCA降维
主成分分析(PCA)算法模型实现及分析(源码在文章后附录)1 引言2 关于PCA原理和算法实现2.1 PCA基本原理2.2 协方差计算2.3 PCA实现步骤 (1)PCA算法实现步骤 (2)基于特征值分解协…...

python 识别图片验证码/滑块验证码准确率极高的 ddddocr 库
前言 验证码的种类有很多,它是常用的一种反爬手段,包括:图片验证码,滑块验证码,等一些常见的验证码场景。 识别验证码的python 库有很多,用起来也并不简单,这里推荐一个简单实用的识别验证码的…...
华为OD机试 - 称砝码(Java JS Python)
题目描述 现有n种砝码,重量互不相等,分别为 m1,m2,m3…mn ; 每种砝码对应的数量为 x1,x2,x3...xn 。现在要用这些砝码去称物体的重量(放在同一侧),问能称出多少种不同的重量。 输入描述 对于每组测试数据: 第一行:n --- 砝码的种数(范围[1,10]) 第二行:m1 m2 m3 ... m…...

DataFrame转化为json的方法教程
网络上有好多的教程,讲得不太清楚和明白,我用实际的例子说明了一下内容,附档代码,方便理解和使用 DataFrame.to_json(path_or_bufNone, orientNone, date_formatNone, double_precision10, force_asciiTrue, date_unitms, defau…...
requests库的使用(一篇就够了)
urllib库使用繁琐,比如处理网页验证和Cookies时,需要编写Opener和Handler来处理。为了更加方便的实现这些操作,就有了更为强大的requests库。 request库的安装 requests属于第三方库,Python不内置,因此需要我们手动…...
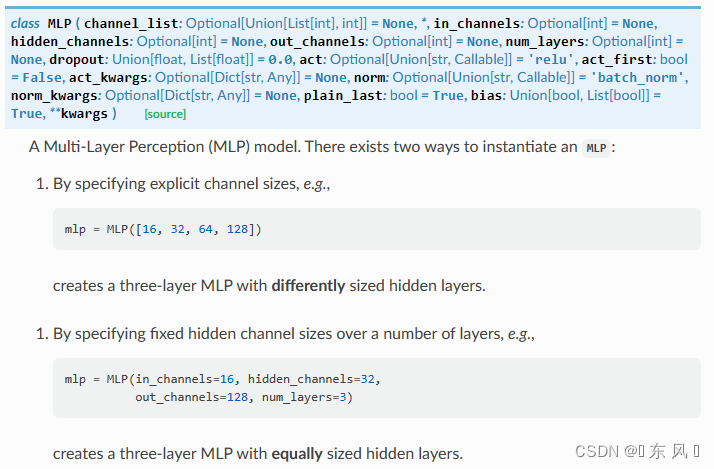
Pytorch+PyG实现MLP
文章目录前言一、导入相关库二、加载Cora数据集三、定义MLP网络四、定义模型五、模型训练六、模型验证七、结果完整代码前言 大家好,我是阿光。 本专栏整理了《图神经网络代码实战》,内包含了不同图神经网络的相关代码实现(PyG以及自实现&a…...
PYcharm怎么用,一篇教会你
文章目录一、界面介绍二、设置中文(无需汉化包)三、常用快捷键四、Python 标识符和关键字1、标识符2、 关键字五、行和缩进六、Python 引号七、Python注释1、单行注释2、多行注释八、Python空行九、输入和输出1、print 输出2、input 输入十、多行语句一、…...
如何在pycharm中使用anaconda的虚拟环境
最近项目中有许多同学咨询如何在pycharm中使用anaconda的虚拟环境(envs),这里就给大家简单介绍一下。 首先我们需要安装anaconda,这里就不在追述了,网上安装教程非常多。anaconda的安装路径大家需要记着因为后面会使用…...
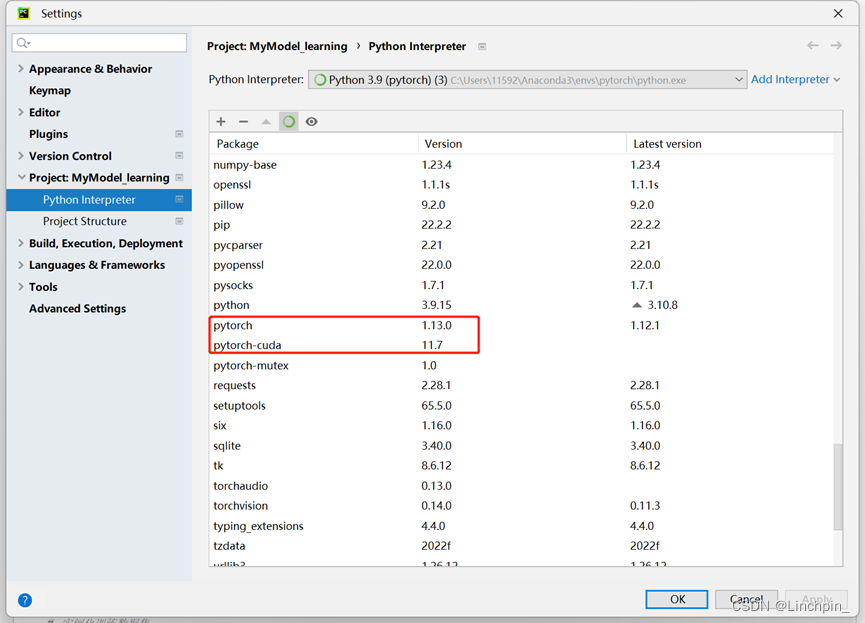
Pytorch环境安装+Pycharm环境安装
我的配置: CUDA版本:11.7 Pytorch版本:1.13.0 Anaconda版本:anaconda3.2022.10(64-bit) Pycharm版本:2022社区版 具体配置过程如下: 1.Anaconda安装 本次安装的anaconda为win6…...
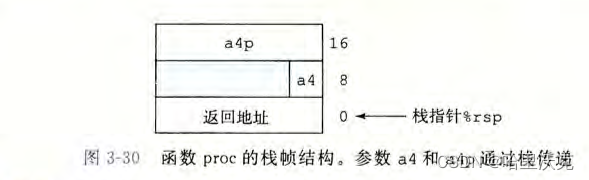
csapp第三章(2) --- 程序的机器级表示
csapp第三章(1) --- 程序的机器级表示https://blog.csdn.net/m0_63488627/article/details/129470787?spm1001.2014.3001.5501本章大纲 目录 3.4.过程 3.4.1运行中的栈 3.4.2转移控制 3.4.3数据传送 3.4.4栈上的局部存储 3.4.5栈的递归实现 3.5.数组分配和访问 3.6结…...