Pandas库
Pandas是python第三方库,提供高性能易用数据类型和分析工具。Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用。pandas库引用: import pandas as pd
包括两个数据类型:Series(相当于一维数据类型),DataFrame(相当于二维-多维数据类型),构成pandas的基础。进行基本操作、运算操作、特征类操作(提取数据特征)、关联类操作(挖掘数据关联关系)
Series类型 = 索引 + 一维数据
Series类型由一组数据及与之相关的数据索引组成。(数据和索引的对应关系)是一维带“标签”的数组,![]()
Series类型索引
自动索引/自定义索引(index=[])pd.Series([ ],index=[ ]),index一词可省略,但index里的‘’不能省
Series类型创建
pd.Series([6,7,8]) pd.Series(25,index=['a','b','c']) pd.Series({'a':8,'b':9}) pd.Series(np.arange(5))




Series类型的基本操作
包括b.index和b.values两部分,索引、切片、运算


 类似ndarray类型,索引切片,运算
类似ndarray类型,索引切片,运算
 似python字典类型,in,.get()方法
似python字典类型,in,.get()方法
Series类型的对齐操作
Series类型有索引,是基于索引的计算,更精确不易出错;numpy是基于维度的计算。
Series类型的name属性
Series对象和索引都可以有一个名字,存储在属性.name中。b.name=' ' b.index.name=' '

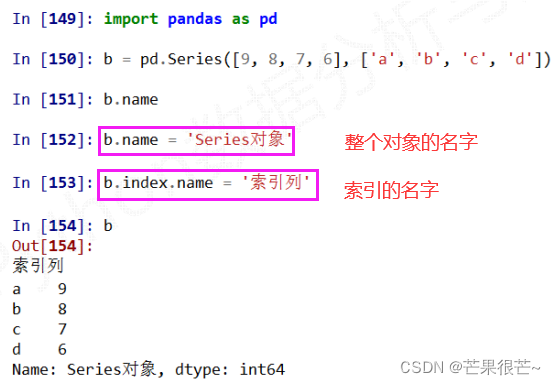
Series类型的修改
Series对象可以随时修改并即刻生效。b[' '] = 15 b[' ',' '] = 15

DataFrame类型 = 行列索引 + 二维数据
DataFrame是二维带“标签”数组,基本操作类似Series,依据行列索引获得。多列数据共用1列索引。
DataFrame是一个表格型的数据类型,每列值类型可不同。有行索引,也有列索引。常用于表达二维数据,也可表达多维数据。

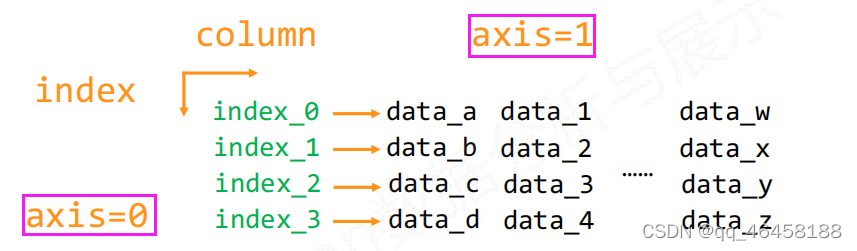
axis=1 :数组的变化为横向,体现出列的增加或者减少。当axis=0时,数组的变化是纵向的,体现出行的增加或减少。
DataFrame类型的创建

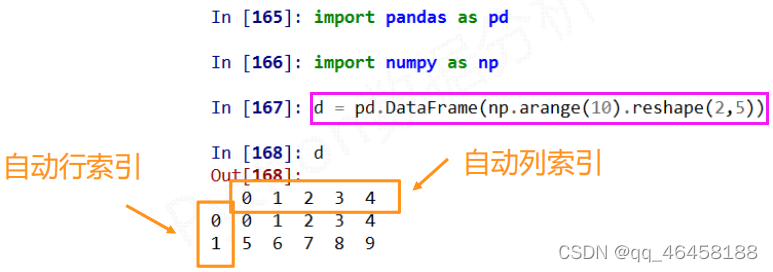 二维ndarray对象创建
二维ndarray对象创建

两个一维Series创建,以字典形式组织,字典的键即为列索引,从左到右---从上到下排列下来。

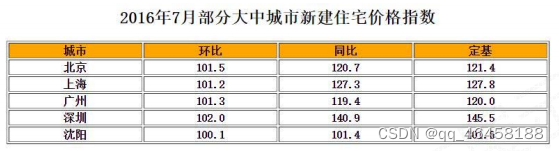
dl = {'城市':['北京','上海','广州','深圳','沈阳'],
'环比':[101.5,101.2,101.3,102.0,100.1],
'同比':[120.7,127.3,119.4,140.9,101.4],
'定基':[121.4,127.8,120.0,145.5,101.6]}
d = pd.DataFrame(dl) #d = pd.DataFrame(dl,index=['c1','c2','c3','c4','c5'])
d
Out[43]:
城市 环比 同比 定基
0 北京 101.5 120.7 121.4
1 上海 101.2 127.3 127.8
2 广州 101.3 119.4 120.0
3 深圳 102.0 140.9 145.5
4 沈阳 100.1 101.4 101.6import pandas as pd
dl = {'城市':pd.Series(['北京','上海','广州','深圳','沈阳']),
'环比':pd.Series([101.5,101.2,101.3,102.0,100.1]),
'同比':pd.Series([120.7,127.3,119.4,140.9,101.4]),
'定基':pd.Series([121.4,127.8,120.0,145.5,101.6])}
#'环比':pd.Series([101.5,101.2,101.3,102.0,100.1],index=['c1','c2','c3','c4','c5']),
pd.DataFrame(dl)
Out[51]:
城市 环比 同比 定基
0 北京 101.5 120.7 121.4
1 上海 101.2 127.3 127.8
2 广州 101.3 119.4 120.0
3 深圳 102.0 140.9 145.5
4 沈阳 100.1 101.4 101.6
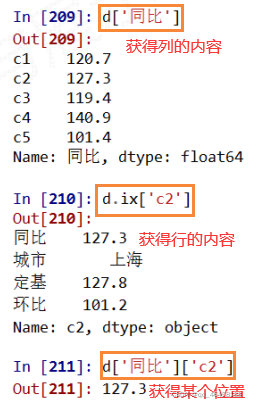
Pandas库的数据类型操作
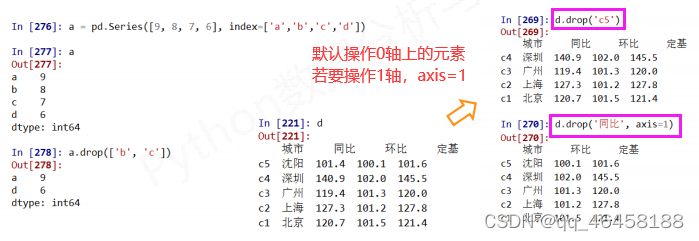
如何改变Series和DataFrame对象? 增加或重排:重新索引 删除:drop
.reindex( )能够改变或重排Series和DataFrame索引
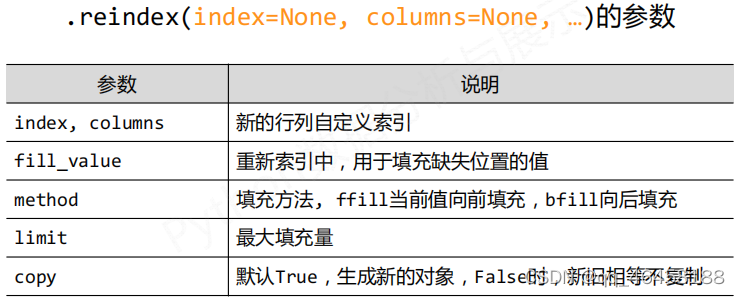
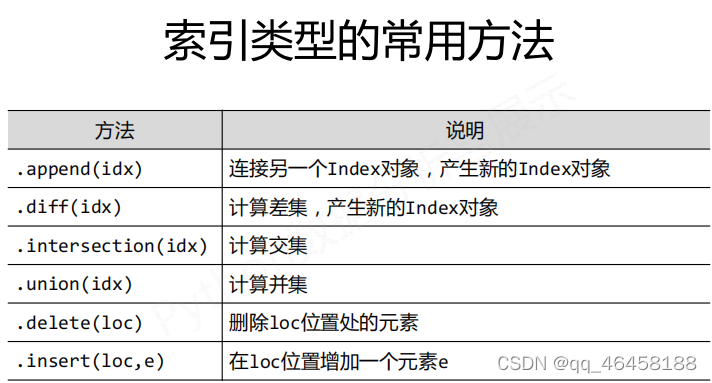

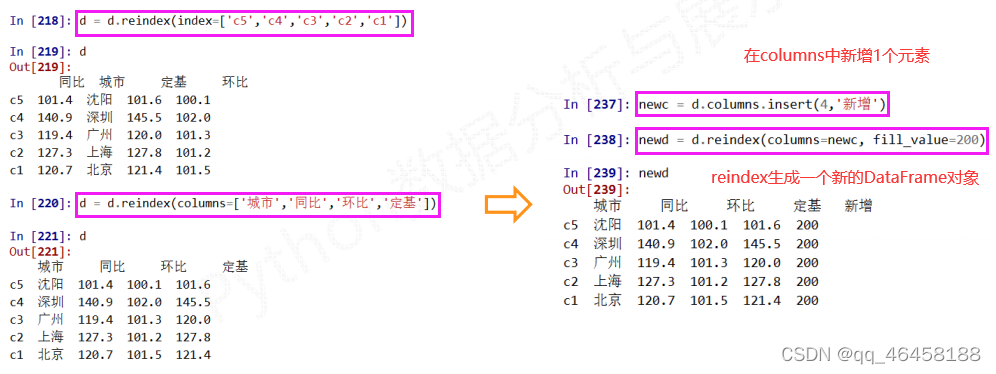
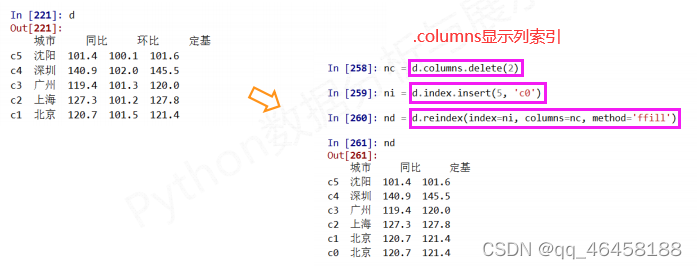
.drop( )能够删除Series和DataFrame指定行或列索引 d.drop('c5')---删除c5行,d.drop('同比',axis=1)---删除'同比'列
Pandas库的数据类型运算
算数运算

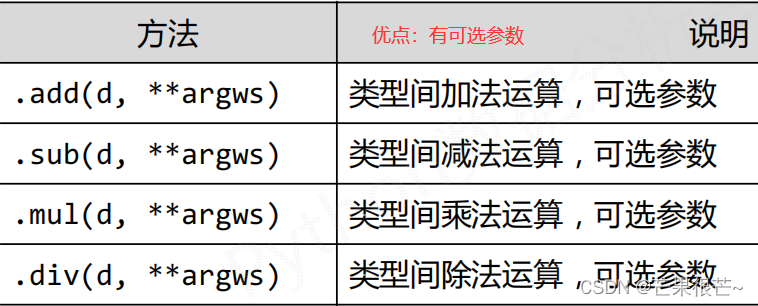




比较运算


Pandas的数据特征分析
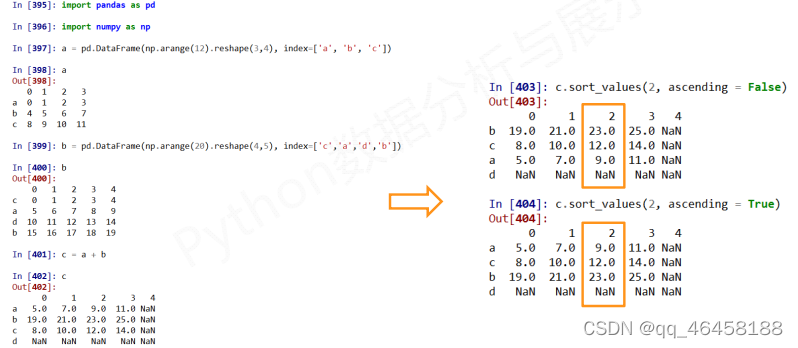
数据的排序 .sort_index( )/.sort_values( )
pandas库既可以操作索引,又可以操作数据。数据的排序,Pandas提供了两种方法。
.sort_index( )方法在指定轴上根据索引进行排序,默认升序。
.sort_index(axis=0,ascending=True) ascending=True表示递增排序


.sort_values( )方法在指定轴上 根据数值进行排序,默认升序。
.sort_values(索引,axis=0/1,ascending=True/False) 索引必须有,默认0轴,默认升序
!对数值进行排序,直接标明列索引/标明行索引+axis=1

NaN统一放到排序末尾
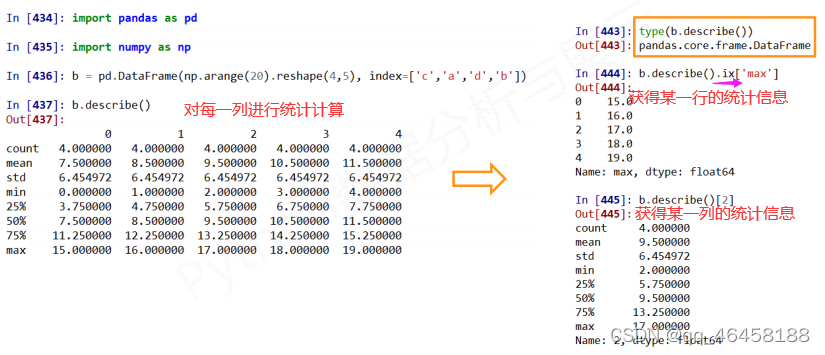
数据的基本统计分析 .describe( )




对于DataFrame格式的,要获取整行的信息或者对行进行排列,需行标签外还需要其他,如axis=1,ix
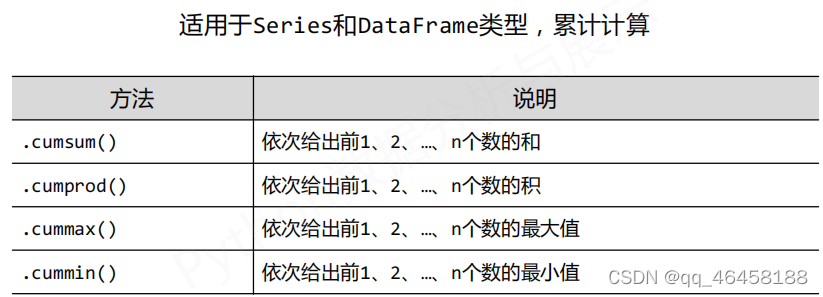
数据的累计统计分析 .cum*( )/.rolling( ).*( )

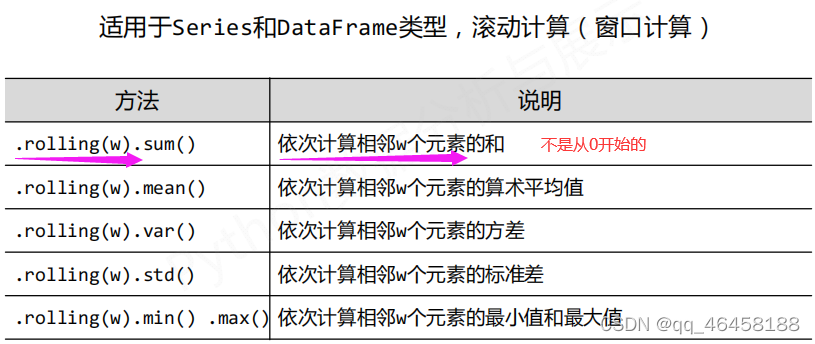
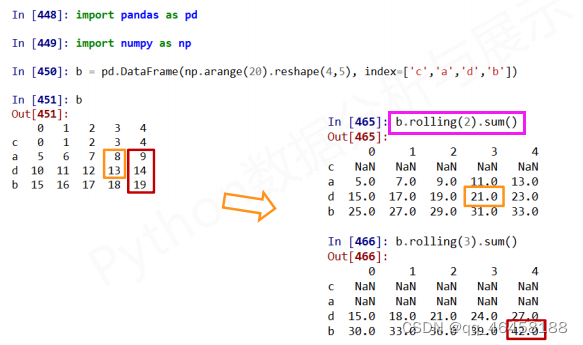
数据的相关分析 .corr( )/.cov( )
相关分析:两个事物,表示为X和Y,如何判断它们之间的存在相关性?
相关性:X增大,Y增大,两个变量正相关; X增大,Y减小,两个变量负相关; X增大,Y无视(无明显变化),两个变量不相关。 ——基础的描述,如何度量???



实例:房价增幅与M2增幅的相关性
import pandas as pd
hprice = pd.Series([3.04,22.93,12.75,22.6,12.33],index=['2008','2009','2010','2011','2012'])
m2 = pd.Series([8.18,13.18,9.13,7.82,6.69],index=['2008','2009','2010','2011','2012'])
hprice.corr(m2)
Out[21]: 0.48136149747121026pandas读取excel数据
data = pd.read_excel(io,sheet_name='Sheet1',
header / names / index_col / usecols / squeeze=True/False / skiprows= / nrows= / skipfooter /parse_dates),
sheet_name = 1代表第2个工作表;sheet_name = 'Sheet5'代表第5个sheet;sheet_name = '红色资源'目标Sheet的名称。
sheet_name = [0, '英超射手榜', 'Sheet4'],组合列表,读取三个工作表:第1个工作表、名为“英超射手榜”工作表、第4个工作表。
header, 用哪一行作列名:默认为0 ,如果header = [0,1],则表示将前两行作为多重索引。
names, 自定义最终列名,适用于Excel缺少列名,或需重新定义列名,names的长度须和Excel列长度一致,否则会报错。
index_col, 用作索引的列,如index_col = '排名';整型或整型列表,如index_col = 0 或 [0, 1],选择多个列,则返回多重索引。
usecols,需要读取哪些列,usecols = [0,2,3];usecols = 'A:C, E';
squeeze,当数据仅包含一列,squeeze为True返回Series,反之返回DataFrame (print(type(data))可查看是Series/DataFrame)
skiprows,跳过特定行,skiprows= n,跳过前n行; skiprows = [a, b, c],跳过第a+1,b+1,c+1行(索引从0开始);可能首行(即列名)也会被跳过。
nrows ,需要读取的行数,如果只想了解Excel的列名及概况,不必读取全量数据,nrows会十分有用。 nrows = 10
skipfooter , 跳过末尾n行,skipfooter = 43
parse_dates:将csv中的时间字符串转换成日期格式
import pandas as pd
io = r'C:\Users\木头目\Desktop\1.xls'
data = pd.read_excel(io,sheet_name='Sheet1',header=[0,1])
print(data.head()) 地点 起始坐标 终点坐标
0 红军树 108.703668,29.241944 106.550483,29.563707
1 黔江纪念碑 108.773174,29.664914 106.550483,29.563707
2 马喇湖纪念碑 108.867973,29.307534 106.550483,29.563707
3 水车坪纪念地 108.872107,29.306239 106.550483,29.563707
4 万涛故居 108.798008,29.398731 106.550483,29.563707原文链接:https://blog.csdn.net/weixin_38546295/article/details/83537558
pandas去重神器:df.drop_duplicates()
a = data.groupby(['User_ID','Gender']):对数据data(DataFrame结构)按’User_ID’和’Gender’分组
python-把excel里面的数据存储到矩阵中
读取excel/csv文件数据后,在训练模型之前常要对数据进行数组转化。(将DataFrame的表格类型转为ndarray的数组类型)
注:.as_matrix()方法将会在未来版本移除,请使用 .values。
import pandas as pd #导入pandas库
df = pd.read_excel("data.xlsx") # 读取excle
#以下方法等价
array1 = df.values #方法一
array2 = df.as_matrix() #方法二 注意:此方法将会在未来版本移除,请使用 .values
array3 = np.array(df) #方法三Dataframe指定列转化为矩阵matrix、数组list
import numpy as np
import pandas as pd
#创建数据框data
data=pd.DataFrame(np.arange(16).reshape(4,4),index=list('ABCD'),columns=list('EFGH'))
print(type(data))
print(data)
#将所有数据输出为矩阵
data1 = data.values
print(type(data1))
print(data1)
#将指定列输出为矩阵
data2 = data[['E','F']].values
print(type(data2))
print(data2)
#将制定列输出为数组
data3 = data['E'].tolist()
print(type(data3))
print(data3)<class 'pandas.core.frame.DataFrame'>
E F G H
A 0 1 2 3
B 4 5 6 7
C 8 9 10 11
D 12 13 14 15
<class 'numpy.ndarray'>
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
<class 'numpy.ndarray'>
[[ 0 1]
[ 4 5]
[ 8 9]
[12 13]]
<class 'list'>
[0, 4, 8, 12]List、Series 类型转换为DataFrame类型并保存为excel或csv文件
想要将数据以excel/csv文件保存,需要将其转换为DataFrame类型
y1 = pd.DataFrame(clusters) #clusters为Series数据,y1为DataFrame数据
y1.to_csv('new1.xlsx') #保存为csv文件
y1.to_excel('new1.xlsx') #保存为excel文件相关文章:

通过两道一年级数学题反思自己
背景 做完这两道题我开始反思自己,到底是什么限制了我?是我自己?是曾经教导我的老师?还是我的父母? 是考试吗?还是什么? 提目 1、正方体个数问题 2、相碰可能性 过程 静态思维: …...
深度学习—卷积神经网络(CNN)全笔记,附代码
本文内容为哔站学习笔记【卷积神经网络-CNN】深度学习(唐宇迪带你学AI):卷积神经网络理论详解与项目实战,计算机视觉,图像识别模块实战_哔哩哔哩_bilibili 目录 深度学习基础 什么是深度学习? 机器学习流…...

Building wheel for mmcv-full (setup.py) ... error解决办法!
mmdetection 安装后,根据官方给的程序安装mmcv时,出现:Building wheel for mmcv-full (setup.py) … error 环境:CUDA11.3, Pytorch1.11 安装根据官网给的安装程序:pip install mmcv-full -f https://download.openmm…...
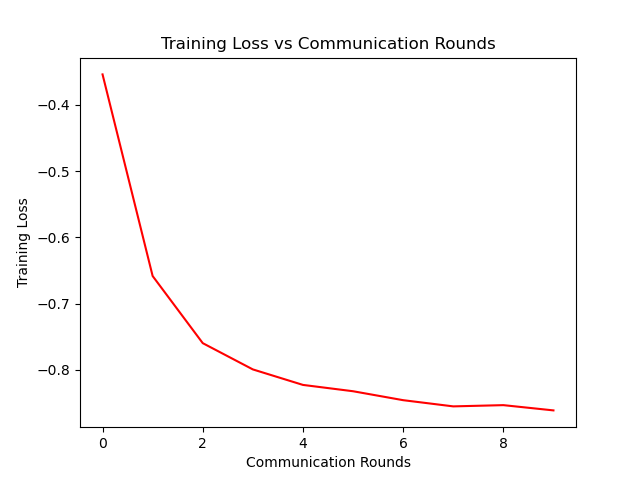
联邦学习开山之作代码解读与收获
参考:联邦学习代码解读,超详细_一只揪的博客-CSDN博客_联邦学习代码 参考文献:[1602.05629] Communication-Efficient Learning of Deep Networks from Decentralized Data (arxiv.org) 参考代码:GitHub - AshwinRJ/Federated-L…...
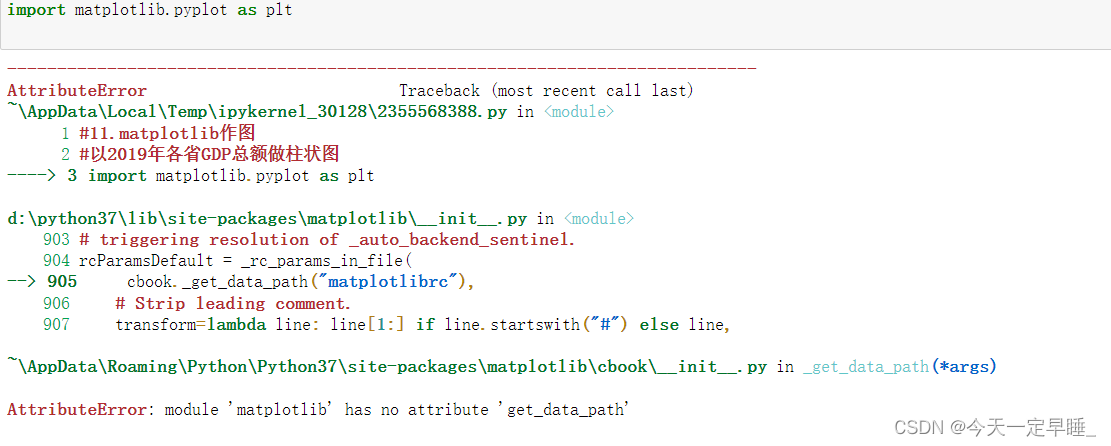
Python安装第三方库常用方法 超详细~
Python安装第三方库常用方法前言安装方法1. 通过pychram安装2. pip安装大法3. 下载whl文件到本地离线安装3.1 补充4.其他方法4.1 Python官方的Pypi菜单4.2 国内镜像源解决pip安装过慢的问题小结前言 在pyhton的学习中,相信大家通常都会碰到第三方库的安装问题&…...
Python--找出字符串中出现次数最多的字符及其出现的次数
方法一: 1、循环遍历列表或字符串,如果字符在字典中则值加1,如果不在则创建(key,value) 2、找到字典中,最大的value值 3、根据最大的value值,找对应的key值,打印出出现次数最多的字符 str &qu…...

滤波笔记一:卡尔曼滤波(Kalman Filtering)详解
本笔记是总结了B站DR_CAN的卡尔曼滤波器的课程,他的B站主页为:DR_CAN的个人空间_哔哩哔哩_bilibili PS:虽然我不是学自控的,但是老师真的讲的很好! 目录 Lesson1 递归算法 Lesson2 数学基础_数据融合_协方差矩阵_状态空间方程…...
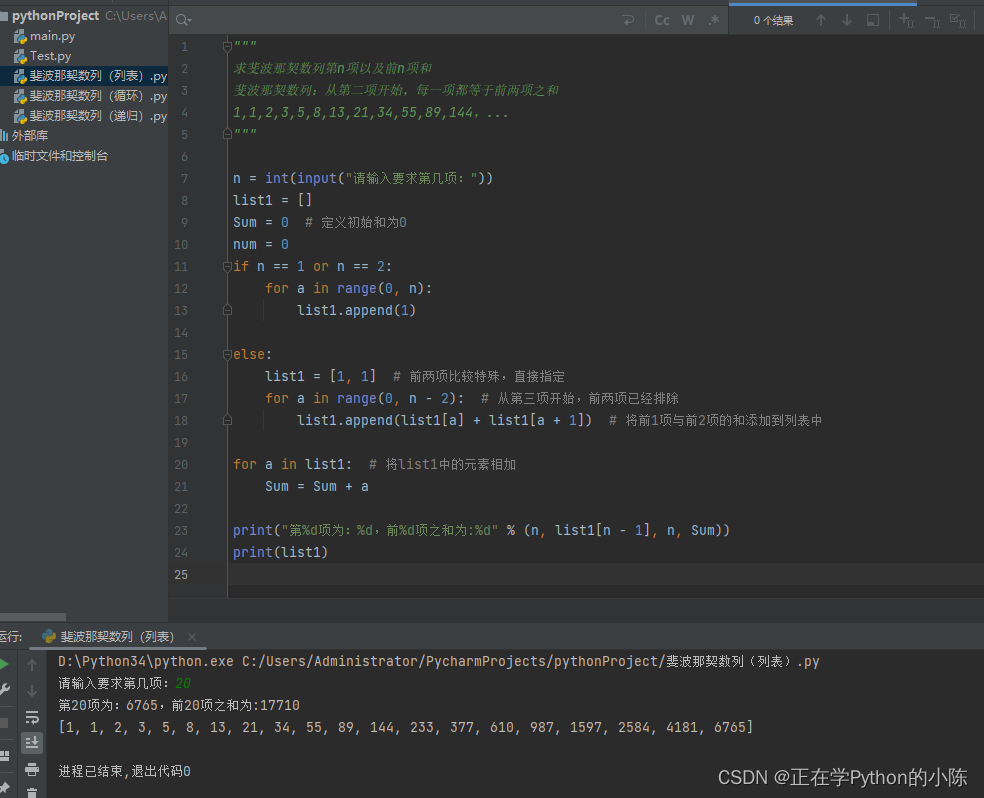
利用Python求斐波那契数列的第N项以及前N项和(循环、递归、集合)
著名的斐波那契数列,即从第三项开始,每一项都等于前两项之和。 之前写过利用Java语言来编写,由于最近正在学Python,所以将自己的想法记录在此,有需要的朋友可以参考一下。 写在前面:这里的三个方法其实思…...
一文速学(十八)-数据分析之Pandas处理文本数据(str/object)各类操作+代码一文详解(三)
目录 前言 一、子串提取 提取匹配首位子串 提取所有匹配项(extractall)...
Python数据分析-数据预处理
数据预处理 文章目录数据预处理1.前言2.数据探索2.1缺失值分析2.2 异常值分析2.2.1 简单统计量分析2.2.2 3$\sigma$原则2.2.3 箱线图分析2.3 一致性分析2.4 相关性分析3.数据预处理3.1 数据清洗3.1.1 缺失值处理3.1.2 异常值处理3.2 数据集成3.2.1 实体识别3.2.2 冗余属性识别3…...
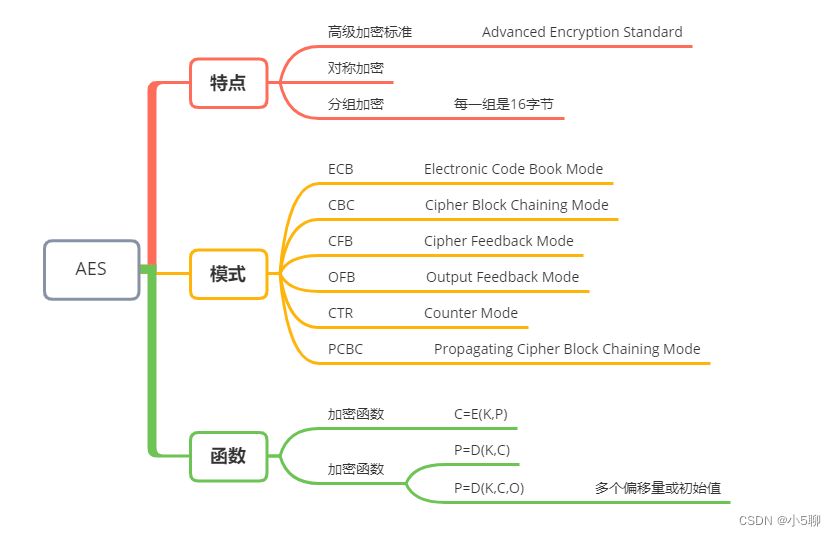
【Python】AES加解密代码,文章还有加密串等你来解密,等你来挑战
🍦🍦写这篇AES文章也是有件趣事,有位小伙伴发了段密文,看看谁解密速度快,学过Python的小伙伴一下子就解开来了,内容也挺有趣的。 🍟🍟原来加解密也可以这么有趣,虽然看起…...
朴素贝叶斯模型及案例(Python)
目录 1 朴素贝叶斯的算法原理 2 一维特征变量下的贝叶斯模型 3 二维特征变量下的贝叶斯模型 4 n维特征变量下的贝叶斯模型 5 朴素贝叶斯模型的sklearn实现 6 案例:肿瘤预测模型 6.1 读取数据与划分 6.1.1 读取数据 6.1.2 划分特征变量和目标变量 6.2 模型…...
python之Tkinter详解
Python之Tkinter详解 文章目录Python之Tkinter详解1、Tkinter是什么2、Tkinter创建窗口①导入 tkinter的库 ,创建并显示窗口②修改窗口属性③创建按钮④窗口内的组件布局3、Tkinter布局用法①基本界面、label(标签)和button(按钮)用法②entry(输入)和text(文本)用法…...

【python】python进行debug操作
文章目录前言一、debug环境介绍二、debug按钮介绍2.1、step into:单步执行(遇到函数也是单步)2.2、step over:单步执行(遇到函数,全部运行)2.3、step into my code:(直接跳到下一个断点)2.4、st…...

Python安装tensorflow过程中出现“No matching distribution found for tensorflow”的解决办法
在Pycharm中使用pip install tensorflow安装tensorflow时报错: ERROR: Could not find a version that satisfies the requirement tensorflow(from versions: none) ERROR: No matching distribution found for tensorflow搜了好多帖子有的说可能是网络的问题&…...

pandas中的read_csv参数详解
1.官网语法 pandas.read_csv(filepath_or_buffer, sepNoDefault.no_default**,** delimiterNone**,** headerinfer’, namesNoDefault.no_default**,** index_colNone**,** usecolsNone**,** squeezeFalse**,** prefixNoDefault.no_default**,** mangle_dupe_colsTrue**,** dty…...
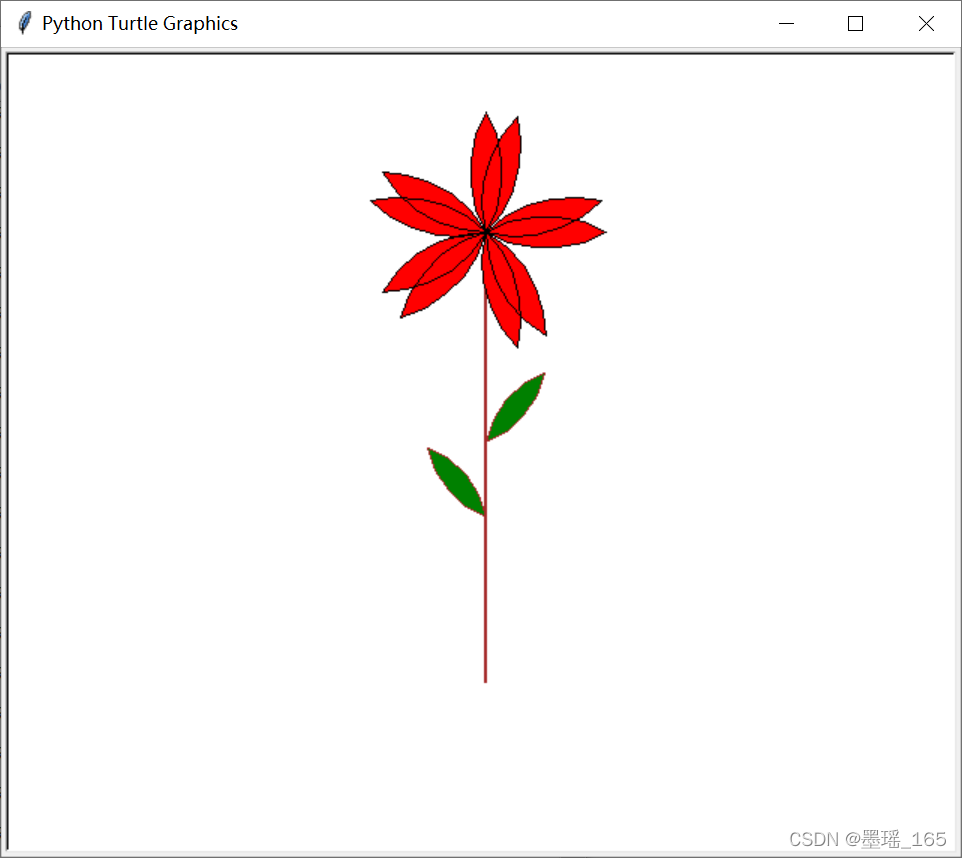
Python — — turtle 常用代码
目录 一、设置画布 二、画笔 1、画笔属性 2、绘图命令 (1) 画笔运动命令 (2) 画笔控制命令 (3) 全局控制命令 (4) 其他命令 3. 命令详解 三、文字显示为一个圆圈 四、画朵小花 一、设置画布 turtle为我们展开用于绘图区域,我们可以设置它的…...

【我是土堆 - PyTorch教程】学习随手记(已更新 | 已完结 | 10w字超详细版)
目录 1. Pytorch环境的配置及安装 如何管理项目环境? 如何看自己电脑cuda版本? 安装Pytorch 2. Python编辑器的选择、安装及配置 PyCharm PyCharm神器 Jupyter(可交互) 3. Python学习中的两大法宝函数 说明 实战操…...
“OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.”解决方法总结
一、问题描述 跑了点神经网络的代码,想画几个激活函数的图像,代码如下: 运行后报了以下错误: 翻译如下: OMP:错误 #15:正在初始化 libiomp5md.dll,但发现 libiomp5md.dll 已经初…...
python3.11.2安装 + pycharm安装
下载 :https://www.python.org/ 2.双击下载的软件: 3.进入安装界面 下一步,点击 是 上一步点击后就看到如下: 安装成功了,接下来检测一下:cmd 安装pycharm PyCharm是一种Python IDE(Integr…...
Python中numpy.polyfit的用法详解
numpy中polyfit的用法 参数 polyfit(x, y, deg, rcondNone, fullFalse, wNone, covFalse):x:M个采样点的横坐标数组; y:M个采样点的纵坐标数组;y可以是一个多维数组,这样即可拟合相同横坐标的多个多项式; deg:多项式…...
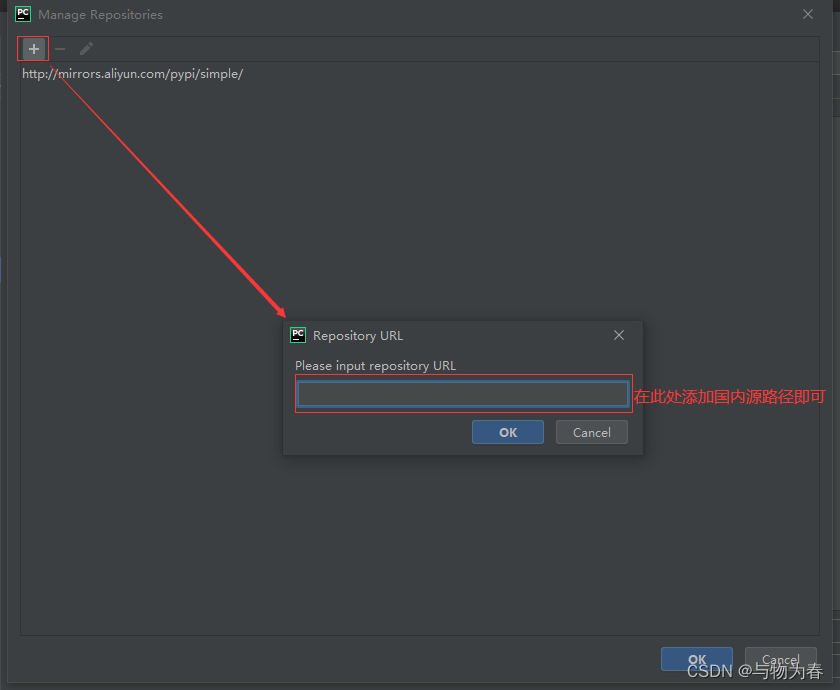
彻底解决Python包下载慢问题
python默认使用的是国外镜像,有时候下载非常慢,最快的办法就是在下载命令中增加国内源: 常用的国内源如下: 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/ 阿里云:http://mirrors.aliyun.com/pypi/…...
Anaconda 使用指南,少走弯路
anaconda包管理器和环境管理器,强烈建议食用 1.下载 官网下载太慢可选用镜像下载 官网下载 :Anaconda | Individual Editionhttps://www.anaconda.com/products/distribution 镜像下载:Index of /anaconda/archive/ | 清华大…...
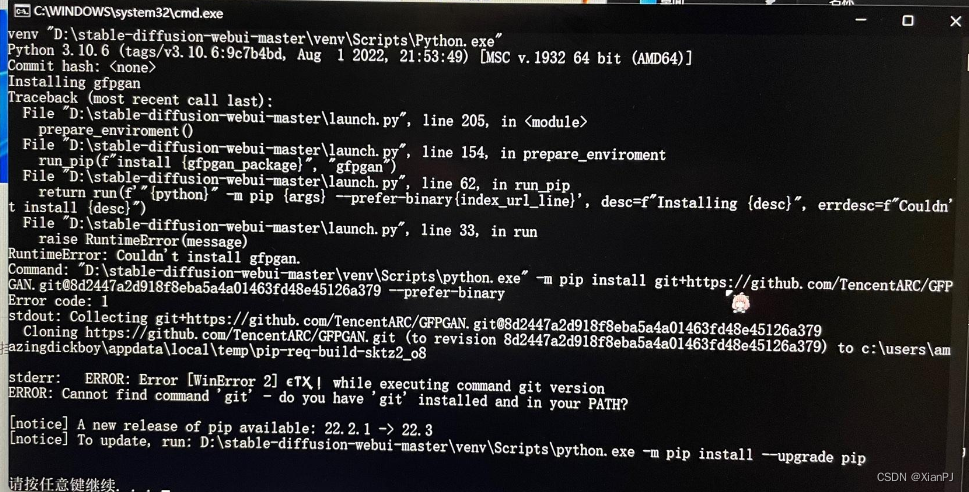
使用stable diffusion webui时,安装gfpgan失败的解决方案(windows下的操作)
1.问题描述 初次打开stable diffusion webui时,需要安装gfpgan等github项目。但在安装gfpgan时,显示RuntimeError: Couldnt install gfpgan 2.解决方案 无法安装gfpgan的原因是网络问题,就算已经科学上网,并设置为全局&#x…...

Python 中导入csv数据的三种方法
这篇文章主要介绍了Python 中导入csv数据的三种方法,内容比较简单,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下微点阅读小编收集的文章介绍。 Python 中导入csv数据的三种方法,具体内容如下所示: 1、通过…...
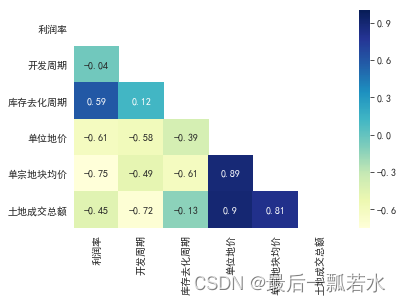
相关性分析、相关系数矩阵热力图
相关性 相关性分析是研究两组变量之间是否具有线性相关关系,所以做相关性分析的前提是假设变量之间存在线性相关性,得到的结果也是描述变量间的线性相关程度。除此之外,相关性分析方法还会有其他的假设条件。而灰色关联度分析首先对数据量要求…...
【python123】题目答案整理 ------更多答案见专栏
目录 二老鼠打洞 来自计算机的问候-任意数量参数 自定义幂函数 来自计算机的问候-多参函数 编写函数输出自除数 最大素数 求数列前n项的平方和 生兔子 计算圆周率——割圆法 数列求前n项和 素数: *如有错误请私聊纠正 二老鼠打洞 nint(input()) # 每日打…...
Python编程题汇总
Python编程复习 1.1找出列表中单词最长的一个 找出列表中单词最长的一个def test():a ["hello", "world", "yoyo", "congratulations"]length len(a[0])# 在列表中循环for i in a:if len(i) > length:length ireturn length p…...
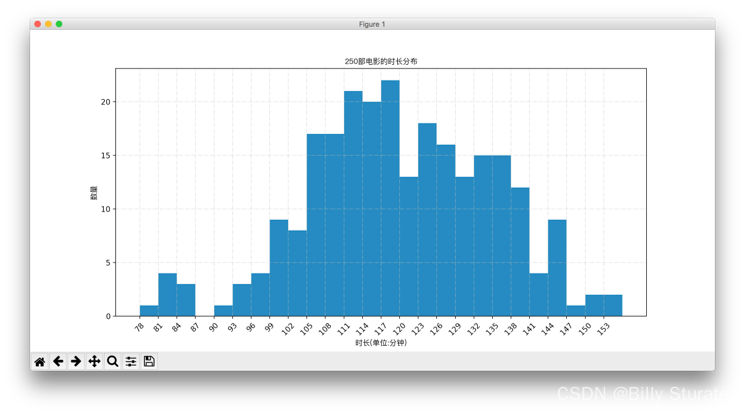
Matplotlib详解
视频教程 1.什么是matplotlib matplotlib: 最流行的Python底层绘图库,主要做数据可视化图表,名字取材于MATLAB,模仿MATLAB构建 2.样例 2.1折线图 eg:假设一天中每隔两个小时(range(2,26,2))的气温(℃)分别是[15,13,14.5,17,20,25,26,26,…...

Jetson AGX Orin安装Anaconda、Cuda、Cudnn、Pytorch、Tensorrt最全教程
文章目录一:Anaconda安装二:Cuda、Cudnn安装三:Pytorch安装四:Tensorrt安装一:Anaconda安装 Jetson系列边缘开发板,其架构都是arm64,而不是传统PC的amd64,深度学习的环境配置方法大…...
pytorch入门篇2 玩转tensor(查看、提取、变换)
上一篇博客讲述了如何根据自己的实际需要在pytorch中创建tensor:pytorch入门篇1——创建tensor,这一篇主要来探讨关于tensor的基本数据变换,是pytorch处理数据的基本方法。 文章目录1 tensor数据查看与提取2 tensor数据变换2.1 重置tensor形状…...

随机森林算法
随机森林1.1定义1.2随机森林的随机性体现的方面1.3 随机森林的重要作用1.4 随机森林的构建过程1.5 随机森林的优缺点2. 随机森林参数描述3. 分类随机森林的代码实现1.1定义 随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法。随机森林非常简单&am…...
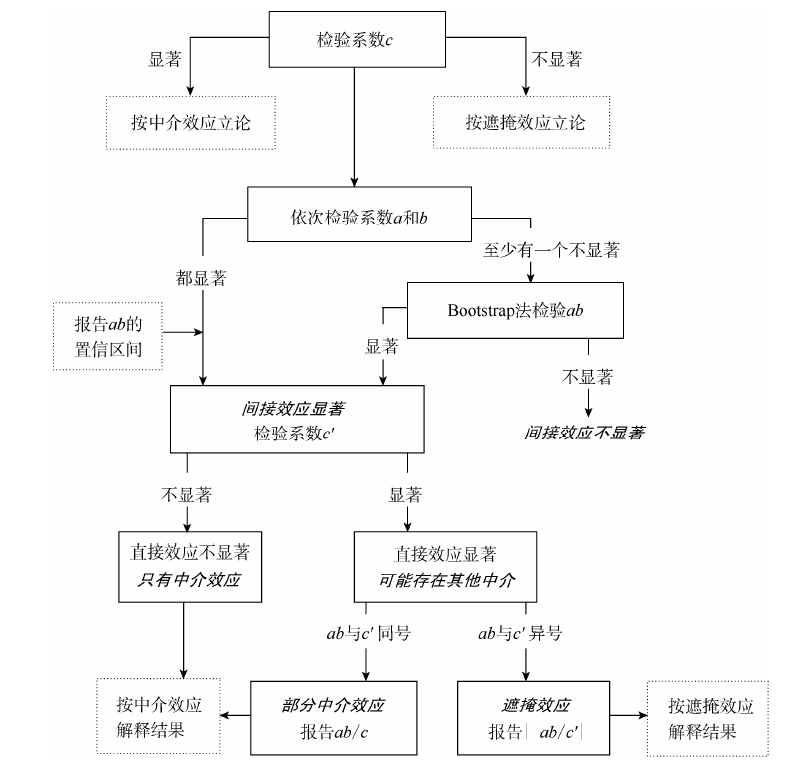
实证分析 | 中介效应检验原理与Stata代码实现
前言 本文是温忠鳞和叶宝娟2014年刊载于《心理科学进展》的论文《中介效应分析:方法和模型发展》的简要笔记与拓展。 温忠麟、叶宝娟:《中介效应分析:方法和模型发展》,《心理科学进展》,2014年第5期 中介效应检验 要…...

几个代码画出漂亮的词云图,python最简单的词云图教程(建议收藏)
在开始编写程序之前,我们先了解一下词云图的作用,我们拿到一篇文章,想得到一些关键词,但文章篇幅很大,无法短时间得到关键词,这时我们可以通过程序将文章中的每个词组识别出来,统计每个词组出现…...

mac m1,m2 安装 提供GPU支持的pytorch和tensorflow
mac m1,m2 安装 提供GPU支持的pytorch和tensorflowAnaconda安装测试Pytorch参考链接安装步骤安装 Xcode创建conda环境测试加速效果注意Tensorflow参考链接安装步骤安装 Xcode指定安装环境加速效果测试The Endmac m1 刚出的时候,各种支持都不完善。那时候要使用conda…...
如何用Python优雅的合并两个Dict
假设有两个dict x和y,合并成一个新的dict,不改变 x和y的值,例如 x {a: 1, b: 2}y {b: 3, c: 4} 期望得到一个新的结果Z,如果key相同,则y覆盖x。期望的结果是 >>> z {a: 1, b: 3, c: 4} 在PEP448中ÿ…...
python读取文件的几种方式
下面是不同场景较为合适的数据读取方法: 1.python内置方法(read、readline、readlines) 纯文本格式或非格式化、非结构化的数据,常用语自然语言处理、非结构文本解析、应用正则表达式等后续应用场景下,Python默认的三…...

python常用模块大全
目录 时间模块time() 与 datetime()random()模块os模块sys模块tarfile用于将文件夹归档成 .tar的文件shutil 创建压缩包,复制,移动文件zipfile将文件或文件夹进行压缩 shelve 模块 json和pickle序列化hashlib 模块subprocess 模块re模块 时间模块time() 与 datetime() time()模…...

成本降低90%,OpenAI正式开放ChαtGΡΤ
今天凌晨,OpenAI官方发布ChαtGΡΤ和Whisper的接囗,开发人员现在可以通过API使用最新的文本生成和语音转文本功能。OpenAI称:通过一系列系统级优化,自去年12月以来,ChαtGΡΤ的成本降低了90%;现在OpenAI用…...

Python:ModuleNotFoundError错误解决
前言: 大家都知道python项目中需要导入各种包(这里的包引鉴于java中的),官话来讲就是Module。 而什么又是Module呢,通俗来讲就是一个模块,当然模块这个意思百度搜索一下都能出来,Python 模块(…...
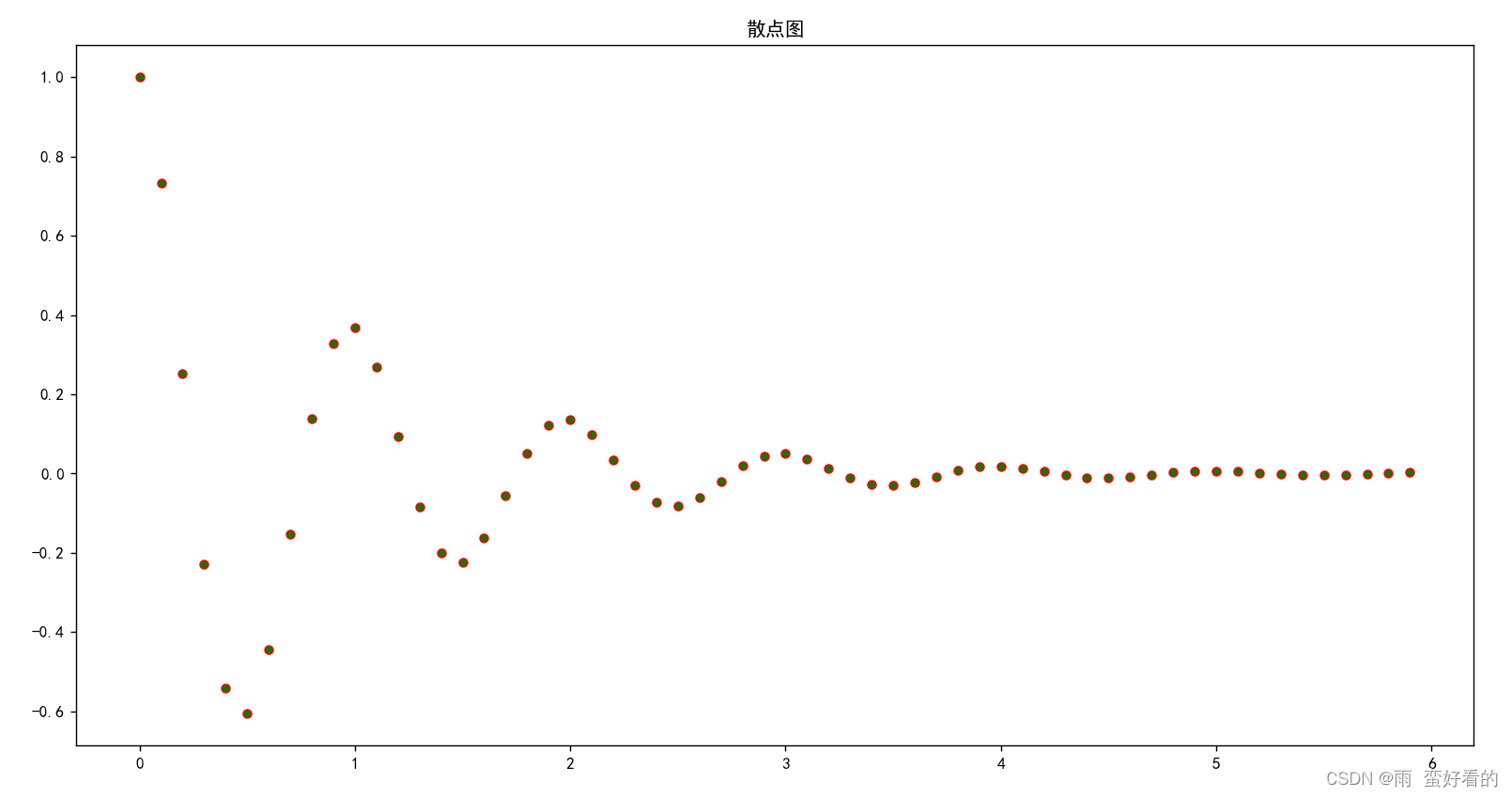
python案例——利用python画图
1、画直线 问题描述: 利用python中的 turtle (海龟绘图)模块提供的函数绘制直线 算法设计: turtle.penup(): 画笔抬起turtle.color(): 设置颜色turtle.goto(): 画笔移动到下一目标turtle.pendown(): …...

pandas.DataFrame设置某一行为表头(列索引),设置某一列为行索引,按索引取多行多列
pandas读取文件 pandas.DataFrame 设置索引 pandas.DataFrame 读取单行/列,多行多列 pandas.DataFrame 添加行/列 利用pandas处理表格类型数据,快捷方便,不常用但是有的时候又是必要技能,在这里记录一下一些常用函数和自己的踩坑…...

主成分分析(PCA)算法模型实现及分析(MATLAB实现)PCA降维
主成分分析(PCA)算法模型实现及分析(源码在文章后附录)1 引言2 关于PCA原理和算法实现2.1 PCA基本原理2.2 协方差计算2.3 PCA实现步骤 (1)PCA算法实现步骤 (2)基于特征值分解协…...

python 识别图片验证码/滑块验证码准确率极高的 ddddocr 库
前言 验证码的种类有很多,它是常用的一种反爬手段,包括:图片验证码,滑块验证码,等一些常见的验证码场景。 识别验证码的python 库有很多,用起来也并不简单,这里推荐一个简单实用的识别验证码的…...
华为OD机试 - 称砝码(Java JS Python)
题目描述 现有n种砝码,重量互不相等,分别为 m1,m2,m3…mn ; 每种砝码对应的数量为 x1,x2,x3...xn 。现在要用这些砝码去称物体的重量(放在同一侧),问能称出多少种不同的重量。 输入描述 对于每组测试数据: 第一行:n --- 砝码的种数(范围[1,10]) 第二行:m1 m2 m3 ... m…...

DataFrame转化为json的方法教程
网络上有好多的教程,讲得不太清楚和明白,我用实际的例子说明了一下内容,附档代码,方便理解和使用 DataFrame.to_json(path_or_bufNone, orientNone, date_formatNone, double_precision10, force_asciiTrue, date_unitms, defau…...
requests库的使用(一篇就够了)
urllib库使用繁琐,比如处理网页验证和Cookies时,需要编写Opener和Handler来处理。为了更加方便的实现这些操作,就有了更为强大的requests库。 request库的安装 requests属于第三方库,Python不内置,因此需要我们手动…...
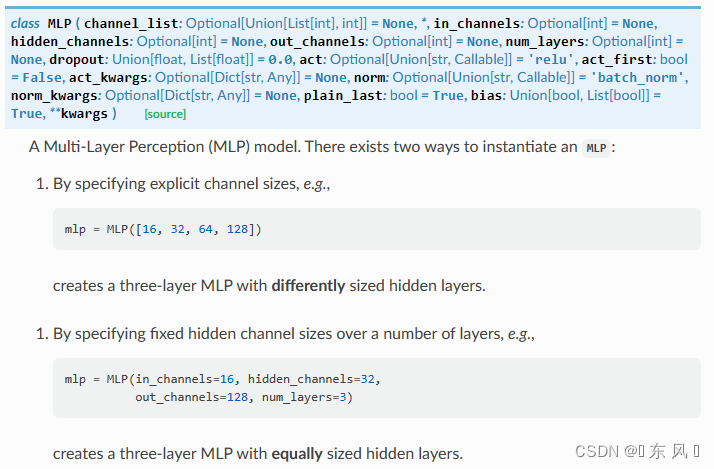
Pytorch+PyG实现MLP
文章目录前言一、导入相关库二、加载Cora数据集三、定义MLP网络四、定义模型五、模型训练六、模型验证七、结果完整代码前言 大家好,我是阿光。 本专栏整理了《图神经网络代码实战》,内包含了不同图神经网络的相关代码实现(PyG以及自实现&a…...
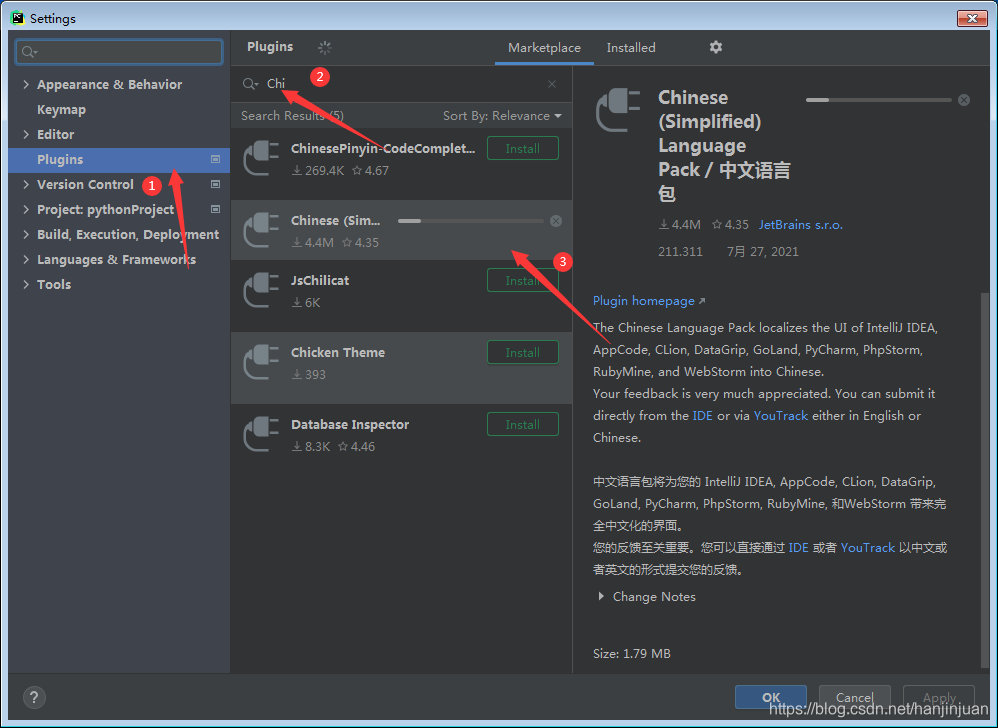
PYcharm怎么用,一篇教会你
文章目录一、界面介绍二、设置中文(无需汉化包)三、常用快捷键四、Python 标识符和关键字1、标识符2、 关键字五、行和缩进六、Python 引号七、Python注释1、单行注释2、多行注释八、Python空行九、输入和输出1、print 输出2、input 输入十、多行语句一、…...
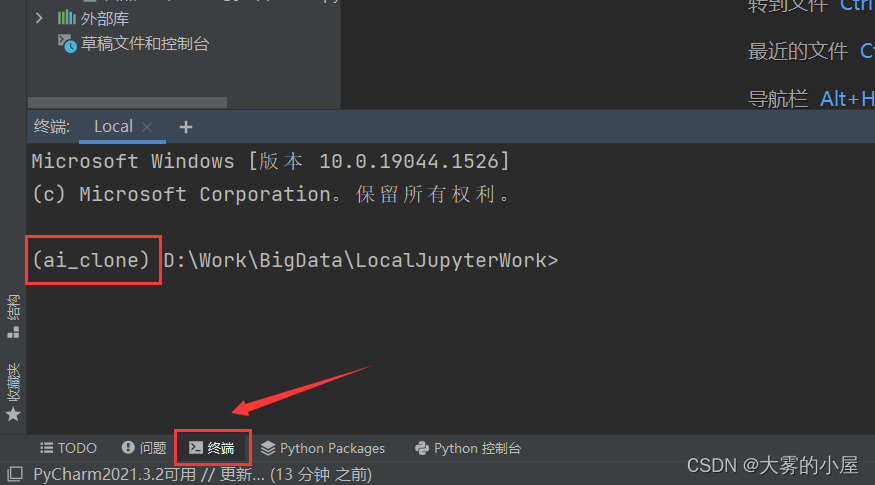
如何在pycharm中使用anaconda的虚拟环境
最近项目中有许多同学咨询如何在pycharm中使用anaconda的虚拟环境(envs),这里就给大家简单介绍一下。 首先我们需要安装anaconda,这里就不在追述了,网上安装教程非常多。anaconda的安装路径大家需要记着因为后面会使用…...