如何在项目中搭建python接口自动化框架?
文章目录
- 前言
- 一、框架目录介绍
- 1、common模块
- 读取Excel代码
- 读取yaml代码(支持场景关联)
- jsonpath断言封装代码
- requests二次封装(get、post)
- configparser读取配置文件
- 递归遍历字典常用方法
- log日志封装
- 2、conf模块
- 3、data模块
- 4、case模块
- 5、run_main.py执行文件
- 6、log模块
- 7、report模块
- 二、接口关联(场景测试)
- 三、接口自动化平台
- 总结
前言
之前因项目需求,自己学习并写了一个python接口自动化的小框架,基于python+requests+pytest+allure,支持Excel、yaml用例数据存储并参数化,生成领导都喜欢的allure报告。博主的代码功底不咋样,望大佬们多指点指点。后面会分不同的章节一一讲解,希望能对你有所帮助。
一、框架目录介绍
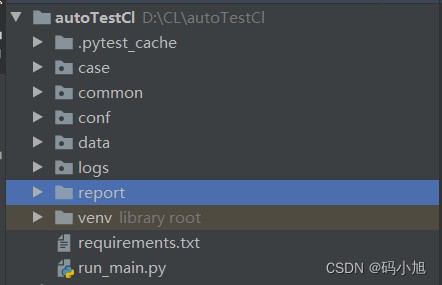
case:用例存放目录
common:存放公共方法目录
conf:存放配置文件目录
data:存放测试数据目录
logs :存放日志目录
report:存放报告目录
run_main.py:用例总执行入口
如上所示,框架的整体目录结构还是分工明确的,封装的方法并不适用每个项目,需要根据自己所在的项目改动,那么下面将每个模块的代码及功能展示。
1、common模块
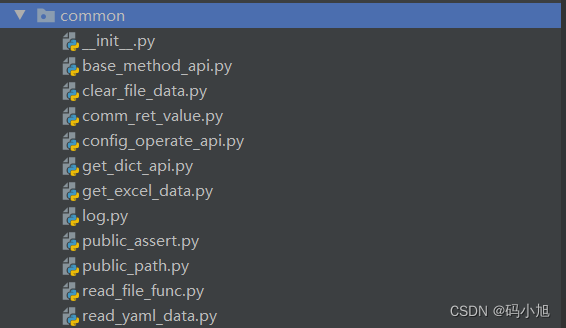
该模块主要存放公共方法,如读取Excel、yaml用例数据,jsonpath断言、日志、configparser读取配置文件、requests二次封装等。根据自己项目所需,封装适合自己的方法,方便后续操作。
读取Excel代码
# coding=utf-8
# @Time : 2022/3/11 9:27
# @Author : 梗小旭
# @File : get_excel_data.py
import os
from openpyxl import load_workbook
from common.public_path import DIR
from common.config_operate_api import Config
class GetExcelData():
"""
封装读取Excel数据
"""
def __init__(self,sheet):
self.path=eval(Config().getconf("excel_path").path) #excel文件路径
self.excel_path=os.path.join(DIR,self.path)
self.wb = load_workbook(self.excel_path)
self.ws = self.wb[sheet]
self.max_columns = self.ws.max_column #最大列数
self.max_rows=self.ws.max_row #最大行数
def get_row_case_list(self,row=None):
"""
按行获取Excel中的用例数据,返回list,如果row=None时,返回整个sheet页所有数据(除表头),
如果row为具体数字时,读取sheet对应的行数数据
:param row: 行数,第一行数据为title,默认已把值加1
:return:
"""
case_list = [] #返回的所有case数据
#当row为None返回当前sheet页中所有用例数据
if row==None:
for i in range(self.max_rows):
temp_case_list=[]
for each in self.ws.iter_cols(min_col=0):
temp_case_list.append(each[i].value)
#openpy的iter_cols用法会读取所有行包含空行(做了格式其他的改变,也会读取),加判断去除空行
if temp_case_list[0]!=None and temp_case_list[:-1]!=None:
case_list.append(temp_case_list)
#去除表头数据
del case_list[0]
return case_list
else:
for i in range(1,self.max_columns+1):
value=self.ws.cell(row=row+1,column=i).value
case_list.append(value)
return case_list
def get_row_case_dict(self,row=None):
"""
按行获取Excel中的用例数据,如果row=None时,返回的数据是全部用例数据,格式为list中存在多个dict
如果row等于具体数字时,读取对应行的数据
:param row: 行数
:return:
"""
case_title_list=self.get_row_case_list(row=0) #获取sheet页第一行,即title
if row==None:
all_case_dict_list=[] #存每个用例的dict格式的list
all_case_list = self.get_row_case_list()
for case in all_case_list:
temp_case_dict=dict(zip(case_title_list,case))
all_case_dict_list.append(temp_case_dict)
return all_case_dict_list
else:
case_list=self.get_row_case_list(row=row)
#通过title和一行的数据使用zip合并成字典
case_dict=dict(zip(case_title_list,case_list))
return case_dict
def get_case_data(self,row=None):
"""
按行获取Excel中用例数据,并把数据中提取url、data、expected_result值,
返回tuple,其中从Excel中读取的键值对数据需要用eval格式转成字典格式
row==None时返回全部用例数据
:param row: 行数
:return:
"""
if row==None:
all_case_list = [] #list存多个tuple,每个tuple中有url,data,expected_result
all_case_dict_list = self.get_row_case_dict()
for temp_case_dict in all_case_dict_list:
temp_list=[]
temp_list.append(temp_case_dict["url"])
data = temp_case_dict["data"]
temp_list.append(eval(data))
temp_list.append(temp_case_dict["expected_result"])
all_case_list.append(tuple(temp_list))
return all_case_list
else:
case_dict=self.get_row_case_dict(row=row)
new_case_list=[]
new_case_list.append(case_dict["url"])
data=case_dict["data"]
new_case_list.append(eval(data))
new_case_list.append(case_dict["expected_result"])
return tuple(new_case_list)
读取yaml代码(支持场景关联)
# coding=utf-8
# @Time : 2022/3/16 14:58
# @Author : 梗小旭
# @File : read_yaml_data.py
import os
import yaml
from common.public_path import DIR
from common.read_file_func import execute_func
from common.get_dict_api import update_dict_val,add_params
class ReadYamlData():
def __init__(self,filename):
self.path=os.path.join(DIR,f"data/{filename}.yaml")
def read_yaml_case(self):
"""
读取yaml文件中数据并返回
:return:
"""
with open(self.path,"r",encoding="utf-8") as f:
data=f.read()
result=yaml.load(data,Loader=yaml.FullLoader)
return result
def yaml_to_list(self,n=None):
"""
把读取yaml的数据转成list中多个tuple,每个tuple放url,data,expected_result,参数化使用
当yaml文件中存在rules规则时,表明该条用例存在接受其他接口传参,读取rules下的规则数据,如下:
position:想要修改数据字典中的key的路径,例如["department","id"],配置文件中写department.id,通过split分解
method:需要调用的函数名称
module:需要调用的函数所在模块及文件路径,例如:interface_data.jiekou,interface_data模块名,jiekou文件名称
params:调用函数所需要的传参,不需要传参时,默认写[]
:param n 对应第几条用例,n为None时,返回全部用例
:return:
"""
result=self.read_yaml_case()
all_case_list=[]
for temp_case in result:
case_list=[]
#判断读取的数据中是否存在rules规则
if "rules" in temp_case:
data = temp_case['data']
for rules in temp_case["rules"]:
position=rules["position"].split('.')
func_name=rules["method"]
module_name=rules["module"]
params=rules["params"]
#读取配置文件中的函数,并执行函数返回值
result=execute_func(func_name=func_name, module_name=module_name,params=params)
#更新data值
update_dict_val(data,position,val=result)
#把数据加到all_case_list中
case_list.append(temp_case["url"])
case_list.append(data)
case_list.append(temp_case["expected_result"])
all_case_list.append(tuple(case_list))
else:
case_list.append(temp_case["url"])
case_list.append(temp_case["data"])
case_list.append(temp_case["expected_result"])
all_case_list.append(tuple(case_list))
#判断n的值,为None时,返回所有的值,n为具体数字时,返回某个案例
if n==None:
return all_case_list
else:
return all_case_list[n-1]
jsonpath断言封装代码
# coding=utf-8
# @Time : 2022/3/17 21:23
# @Author : 梗小旭
# @File : public_assert.py
import jsonpath
def assert_res(res,expected_result):
"""
传入响应体的json格式数据和Excel或yaml中读取的预期结果值,预期结果逐一判断,有一个不符合则返回False
:param res: 请求返回的响应体数据
:param expected_result: 预期结果值,例如:'$.code=201;$.success=False;$.message=用户名或密码错误'
注意:字符串里面不能写引号,比如不能$.message=“用户名或密码错误”,正确写法是:$.message=用户名或密码错误
:return:
"""
for exp in expected_result.split(";"):
rule=exp.split("=")[0] #jsonpath提取规则
exp_value=exp.split("=")[1] #预期结果值
reality_value=jsonpath.jsonpath(res,rule)[0] #真实返回值
#预期结果中存在特殊False和True,读取时要用eval把str类型转成bool,才能和返回值对比判断
if exp_value=='False' or exp_value=='True':
exp_value=eval(exp_value)
if str(exp_value)==str(reality_value):
continue
else:
return False
return True
requests二次封装(get、post)
# coding=utf-8
# @Time : 2022/3/10 15:52
# @Author : 梗小旭
# @File : base_method_api.py
from common.log import log
import requests
import traceback
from common.config_operate_api import Config
class BaseMethodApi():
def __init__(self):
self.conf = Config().getconf("enviro")
self.host=self.conf.host
self.url=self.conf.url
self.data=self.conf.data
def get_token_data(self):
"""
获取当前环境下的token值
:return: 返回登录成功的token值
"""
complete_ulr = "http://" + self.host + self.url # 完整url
res=requests.post(url=complete_ulr,json=eval(self.data),headers=self.choice_headers())
token=res.json()['data']['token']['access_token']
return token
def choice_headers(self,type=None):
"""
封装选择请求头信息,type等于None时,请求头不传token,等于其他值时传token
:param type:
:return:
"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
"Content-Type": "application/json; charset=utf-8"
}
if type:
headers["Authorization"]=self.get_token_data()
return headers
else:
return headers
def get(self,url,params=None,headers=None,files=None):
"""
get请求
:param url: 请求路径
:param params: 请求参数
:param headers: 请求头
:param files: 请求文件
:return:
"""
try:
log.info("============请求信息============")
complete_ulr="http://"+self.host+url#完整url
if not headers:
headers=self.choice_headers(type=1)
else:
headers=self.choice_headers()
res=requests.get(url=complete_ulr,params=params,headers=headers,files=files)
log.info(f"请求url:{complete_ulr}")
log.info(f"请求参数:{params}")
log.info(f"请求头:{headers}")
log.info("============响应信息============")
log.info(f"响应状态码:{res.status_code}")
log.info(f"响应结果:{res.text}")
return res
except:
log.error("============请求失败信息============")
log.error(f"请求异常:{traceback.print_exc()}")
def post(self,url,data=None,json_data=None,headers=None,files=None):
"""
post请求
:param url: 请求路径
:param data: 原始请求参数
:param json_data: json格式请求参数
:param headers: 请求头
:param files: 请求文件
:return:
"""
try:
log.info("============请求信息============")
complete_ulr="http://"+self.host+url#完整url
if not headers:
headers=self.choice_headers(type=1)
else:
headers=self.choice_headers()
res=requests.post(url=complete_ulr,data=data,json=json_data,headers=headers,files=files)
log.info(f"请求url:{complete_ulr}")
if json_data==None:
log.info(f"请求参数:{data}")
else:
log.info(f"请求参数:{json_data}")
log.info(f"请求头:{headers}")
log.info("============响应信息============")
log.info(f"响应状态码:{res.status_code}")
log.info(f"响应结果:{res.text}")
return res
except:
log.error("============请求失败信息============")
log.error(f"请求异常:{traceback.print_exc()}")
configparser读取配置文件
#coding=utf-8
import os
from configparser import ConfigParser
class Dictionary(dict):
'''
把config.ini中的参数添加值dict
'''
def __getattr__(self, keyname):
#如果key值不存在则返回默认值"not find config keyname"
return self.get(keyname, "config.ini中没有找到对应的keyname")
class Config(object):
'''
ConfigParser二次封装,在字典中获取value
'''
def __init__(self):
# 设置配置文件路径
current_dir = os.path.dirname(__file__)
top_one_dir = os.path.dirname(current_dir)
file_name = top_one_dir + "/conf/config.ini"
# 实例化ConfigParser对象
self.config = ConfigParser()
self.config.read(file_name,encoding="utf-8")
#根据section把key、value写入字典
for section in self.config.sections():
setattr(self, section, Dictionary())
for keyname, value in self.config.items(section):
setattr(getattr(self, section), keyname, value)
def getconf(self, section):
'''
用法:
conf = Config()
info = conf.getconf("main").url
'''
if section in self.config.sections():
pass
else:
print(" 找不到该 section")
return getattr(self, section)
递归遍历字典常用方法
#coding=utf-8
from typing import Dict,List
def get_dict(dict_value ,obj_key ,default=None):
"""
遍历字典,得到想要的value
:param dict_value: 所需要遍历的字典
:param obj_key: 所需要value的键
:param default:进行取值中报错时所返回的默认值 (default: None)
:return:
"""
for k ,v in dict_value.items():
if k == obj_key:
return v
else:
if type(v) is dict : # 如果键对应的值还是字典
re = get_dict(v ,obj_key ,default) # 递归
if re is not default:
return re
def get_list_dict(list_value ,obj_key,obj_value):
"""
遍历列表中的每个字典,判断obj_key,obj_value值是否存在,存在则任何True,否则False
:param list_value: 所需要遍历的列表
:param obj_key: 想要判断的key
:param obj_value: 想要判断的value
:return:
"""
for dict_value in list_value:
for k ,v in dict_value.items():
if k == obj_key and v == obj_value:
return True
else:
continue
#列表中所有数据都不存在时,返回False
return False
def updata_dict_value(dict_data ,obj_key,update_value=None):
"""
遍历字典,得到想要的key对象,给读取文件时修改值,如果obj_key存在一样的情况下,就会改错
:param dict_value: 所需要遍历的字典
:param obj_key: 所需要value的键
:return:
"""
for k ,v in dict_data.items():
if k == obj_key:
dict_data[k]=update_value
else:
if type(v) is dict : # 如果键对应的值还是字典
updata_dict_value(v ,obj_key,update_value) # 递归
def update_dict_val(data:Dict, key_list:List, val:int,i=0):
"""
传入data字典格式数据,根据对应的key_list,把对应的key的val值修改
:param data: 传入的字典数据
:param key_list: 传入修改的key list,例如["department","id"],配置文件中写department.id,通过split分解
:param val: 想要修改的值
:param i: i值默认为0,递归时默认+1
:return:
"""
if i==len(key_list)-1:
data[key_list[i]] = val
return
return update_dict_val(data[key_list[i]], key_list, val,i=i+1)
def add_params(func_str,params):
"""
根据传入的函数名称,和函数所需要的数据来拼接成函数传参的字符串格式,通过eval转成可以执行的函数
:param func_str: 函数的名称,必须传字符串
:param params: 函数所需要的参数,params是一个list,例如函数为:add(a,b,c=4),huanc
:return:
"""
value = ",".join([str(i) for i in params])
val = f'{func_str}({value})'
return eval(val)
log日志封装
#coding=utf-8
import logging
from common.public_path import DIR
import time
import os
def get_log(logger_name):
"""
:param logger_name: 填项目名称表示哪个项目
:return:
"""
#创建一个logger
logger = logging.getLogger(logger_name)
logger.setLevel(logging.INFO)
#获取本地时间,转换为设置的格式
#rq = time.strftime('%Y%m%d%H%M',time.localtime(time.time()))
rq = time.strftime("%Y_%m_%d_")
#设置日志文件存放路径,日志文件名
#设置所有日志和错误日志的存放路径
# 通过getcwd.py文件的绝对路径来拼接日志存放路径
all_log_path = os.path.join(DIR,'logs/info_logs/')
error_log_path = os.path.join(DIR,'logs/error_logs/')
#设置日志文件名
all_log_name = all_log_path + rq + '.log'
error_log_name = error_log_path + rq + '.log'
#创建handler
#创建一个handler,写入所有日志
fh = logging.FileHandler(all_log_name,encoding="utf-8")
fh.setLevel(logging.INFO)
#创建一个handler,写入错误日志
eh = logging.FileHandler(error_log_name,encoding="utf-8")
eh.setLevel(logging.ERROR)
#创建一个handler,输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
#定义日志输出格式
#以时间-日志器名称-日志级别-日志内容的形式展示
all_log_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 以时间-日志器名称-日志级别-文件名-函数行号-错误内容
error_log_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(module)s - %(lineno)s - %(message)s')
# 将定义好的输出形式添加到handler
fh.setFormatter(all_log_formatter)
ch.setFormatter(all_log_formatter)
eh.setFormatter(error_log_formatter)
# 给logger添加handler
logger.addHandler(fh)
logger.addHandler(eh)
logger.addHandler(ch)
return logger
#实例化log,调用时,直接调用log
log = get_log("CL接口自动化")
2、conf模块

该模块主要放配置数据,ini文件中数据格式如下,可存放环境数据、文件路径、邮箱等,根据自己需要配置
[enviro]
host=127.0.0.1:8000
url=/interface/login
data={'username':'zwx','password':'123123'}
[excel_path]
path='data/case_data.xlsx'
3、data模块
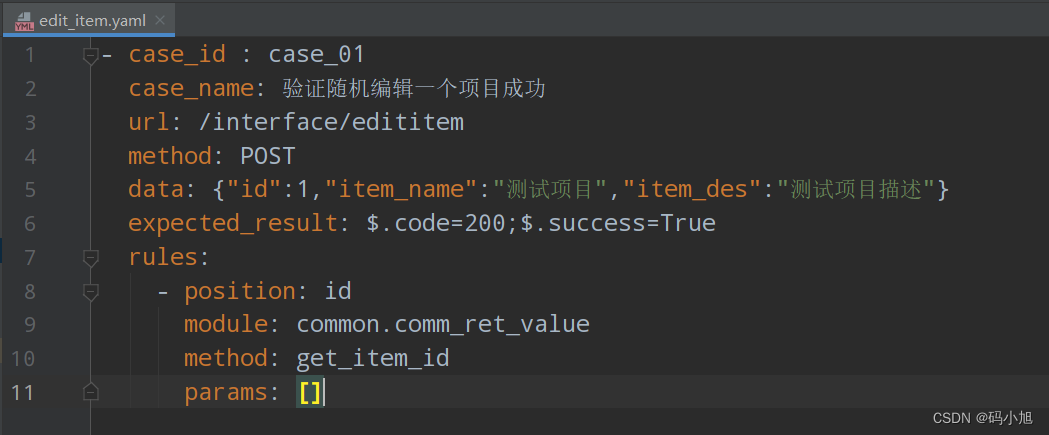
该模块下存放参数化用例数据,支持yaml或者Excel,使用common中封装读取方法,读取测试用例并参数化使用。
yaml文件格式如下(如果不需要接口关联,可以不用写rules,后续文章会讲解):
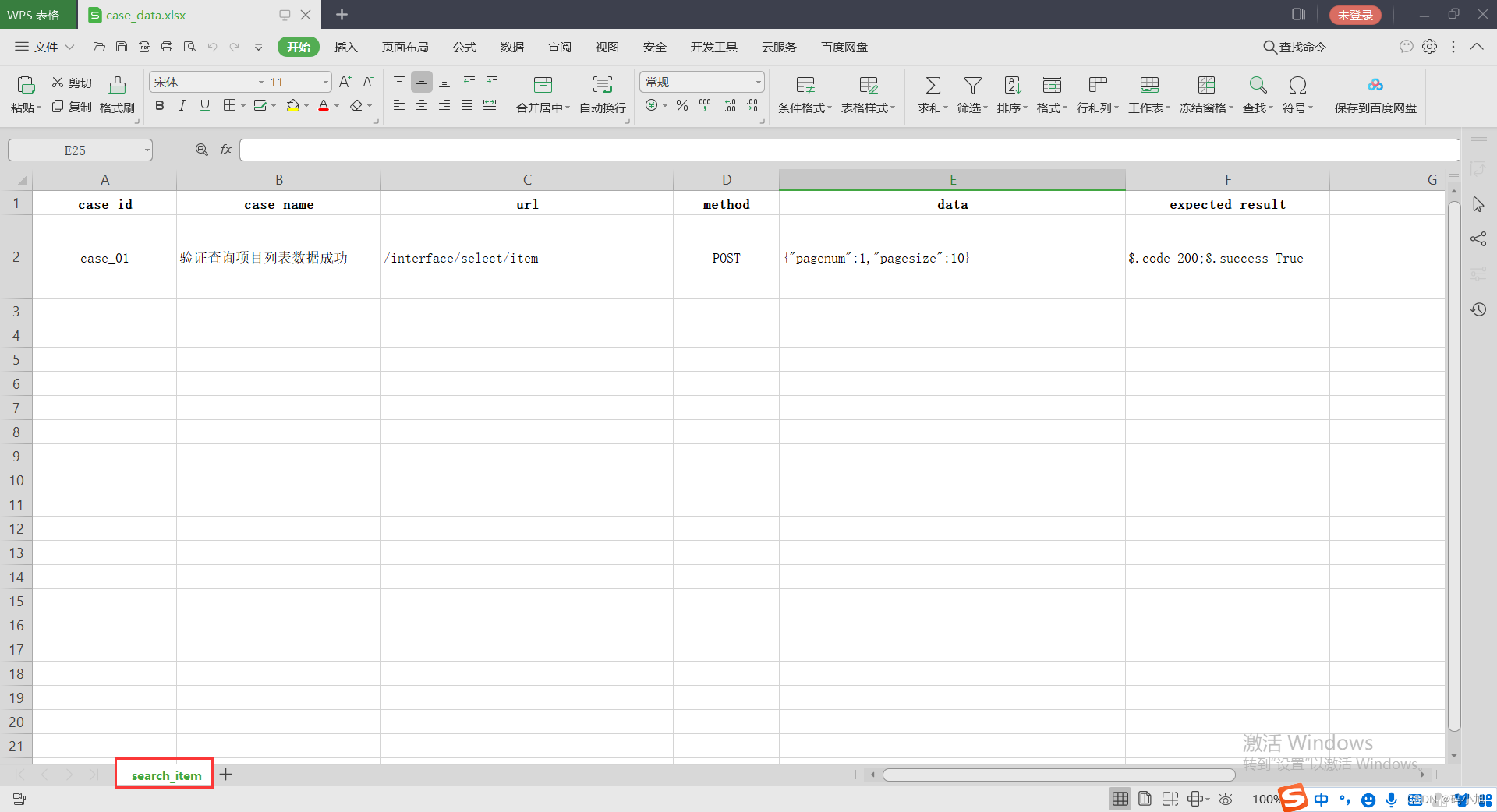
Excel文件格式如下(可以用sheet页区分不同模块或接口的用例):
4、case模块
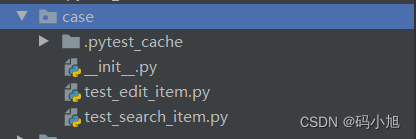
case模块主要用于存放测试用例,简单写了两条查询项目的接口用例,用例存放在yaml中,这里采用jsonpath断言,通过封装好的读取yaml数据的方法,读取数据后通过parametrize参数化,如下:
yaml文件:
- case_id : case_01
case_name: 验证查询项目列表数据成功
url: /interface/select/item
method: POST
data: {"pagenum":1,"pagesize":10}
expected_result: $.code=200;$.success=True
- case_id : case_02
case_name: 验证查询页数pagenum为-1时,查询失败
url: /interface/select/item
method: POST
data: {"pagenum":-1,"pagesize":10}
expected_result: $.code=2003;$.success=False;$.msg=查询项目数据失败
用例文件:
# coding=utf-8
# @Time : 2022/5/24 11:17
# @Author : 梗小旭
# @File : test_search_item.py
import pytest
from common.base_method_api import BaseMethodApi
from common.read_yaml_data import ReadYamlData
from common.public_assert import assert_res
from common.get_excel_data import GetExcelData
case_list=ReadYamlData("search_item").yaml_to_list() #读取该文件下所有测试用例
@pytest.mark.parametrize("url,data,expected_result",case_list)
def test_login(url,data,expected_result):
bma=BaseMethodApi()
res=bma.post(url=url,json_data=data)
result=res.json()
assert assert_res(result,expected_result)
if __name__ == '__main__':
pytest.main(["-s","test_search_item.py"])
5、run_main.py执行文件
该文件执行所有用例,代码如下:
# coding=utf-8
# @Time : 2022/3/10 15:33
# @Author : 梗小旭
# @File : run_main.py
import os
import shutil
from common.public_path import DIR
path=DIR+'/report'
if os.path.exists(path):
shutil.rmtree(path)
os.system("pytest -s -q --alluredir report")#生成allure报告
os.system("allure generate report/ -o report/html --clean")#清除报告数据
6、log模块
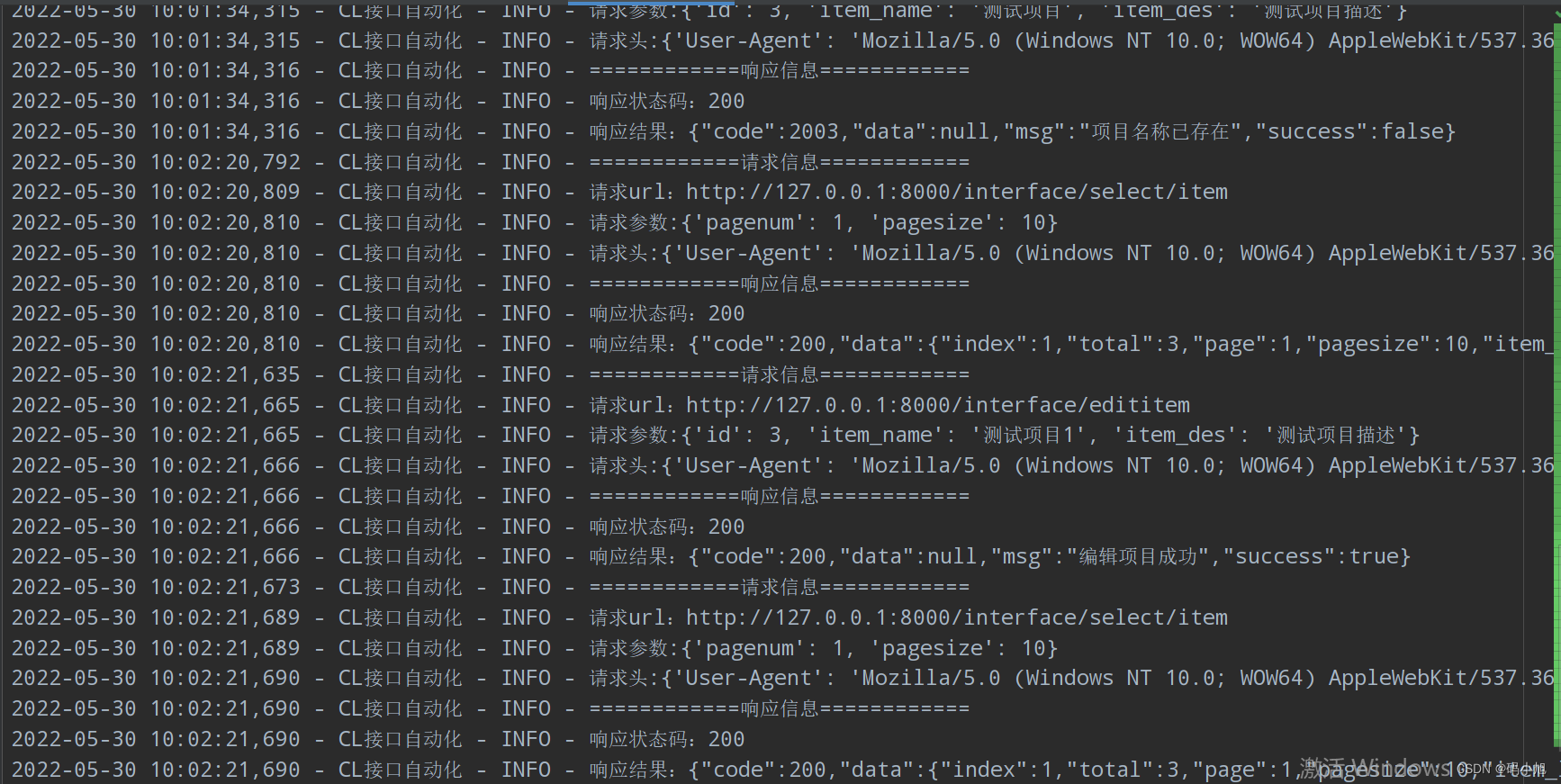
该模块主要放info和error日志数据,如下:
7、report模块
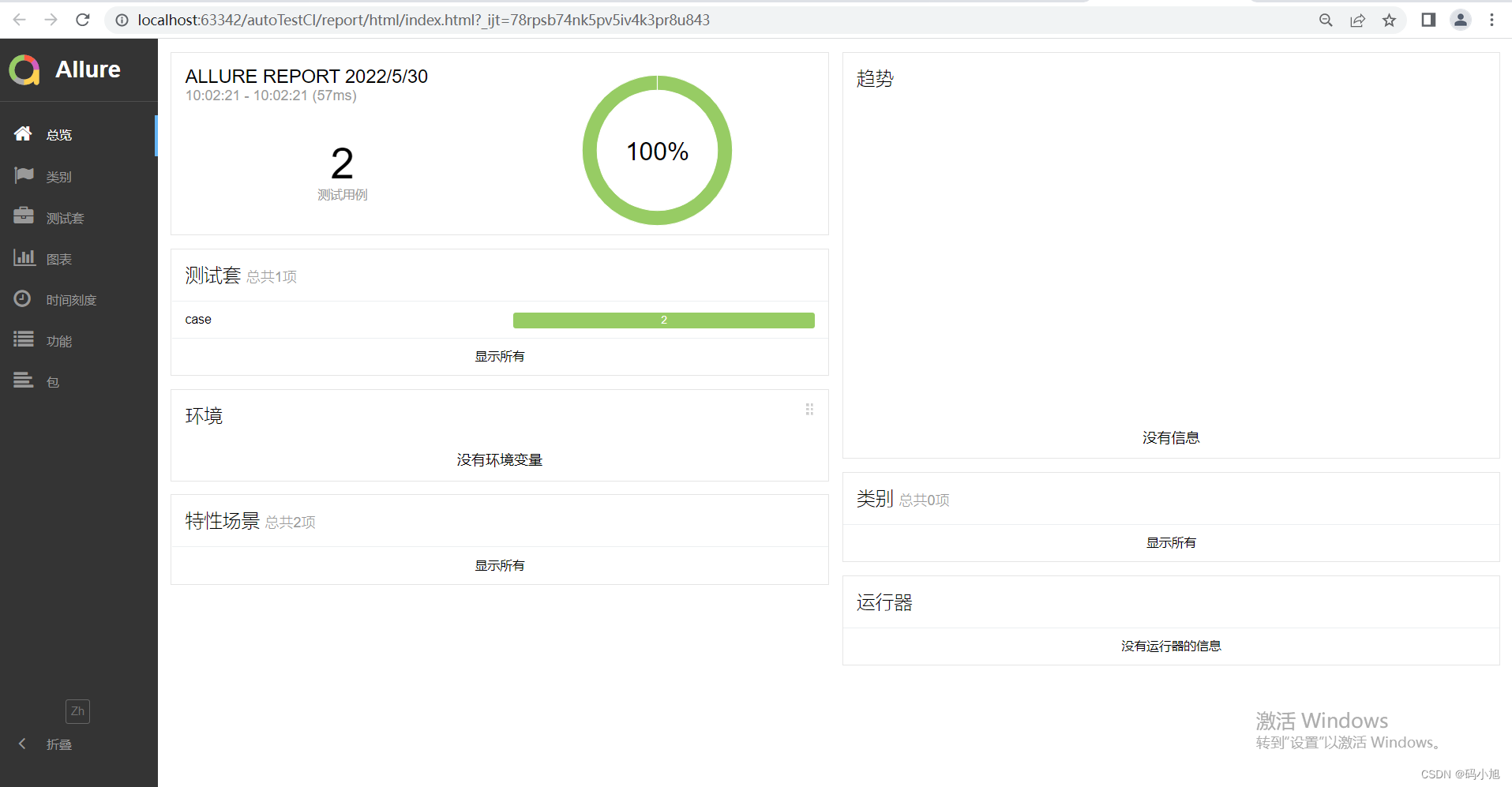
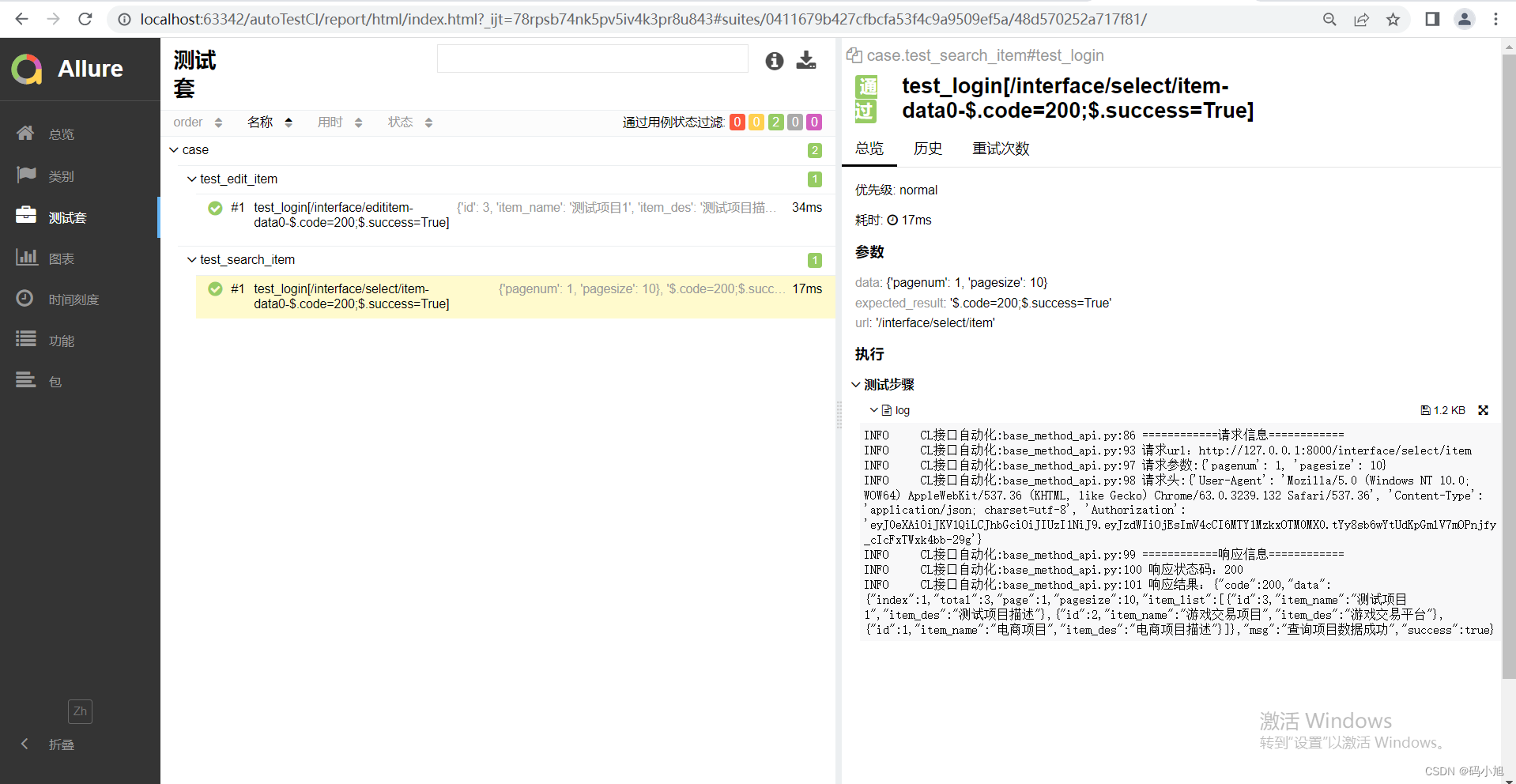
该模块存放执行生成的allure报告数据,可以通过allure添加步骤,描述、优先级等详细信息,本文未添加,用例标题可通过在parametrize中ids参数中添加,报告如下:
二、接口关联(场景测试)
在我们做接口测试时,接口关联的测试必不可少且非常重要的,那么我们在做接口自动化时,接口关联的场景我们如何做呢?
1、假如B接口的入参需要A接口的返回值,那么执行A接口的用例后把返回值存在文件中,B接口用例执行时读取文件中数据,形成接口关联。这样做虽然可以,但是存在一个问题,会导致每条用例不独立,如果接口A失败了,接口B的用例全部失败。
2、假如B接口的入参需要A接口的返回值,接口A单独写用例,不存返回值数据。单独封装一个接口A的方法返回值,接口B使用数据时调用封装的A方法,实现接口A和接口B的用例解耦。
本文中使用的是第2种方式,在yaml文件中增加rules规则,存在rules规则时,会调用对应模块的方法获取返回值,并修改这条用例的position字段值。大佬们有其他方法可以在评论区下留言。
rules:
- position: id
module: common.comm_ret_value
method: get_item_id
params: []
三、接口自动化平台
最近自己也写了一个接口自动化小平台,仅供自己学习使用,功能还未完善,完善后续更新出来,采用vue+fastapi前后端分离实现,话不多说,上图:
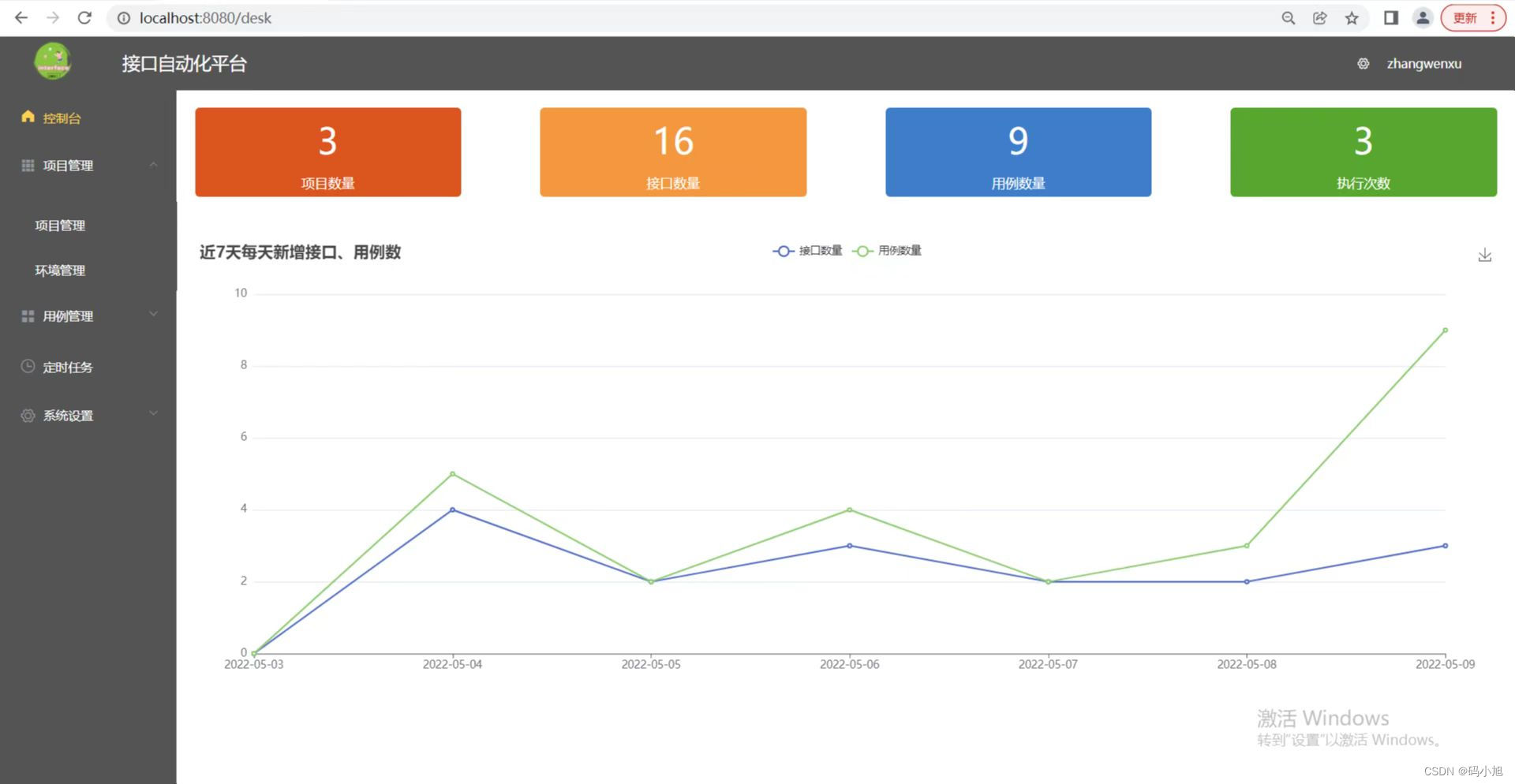
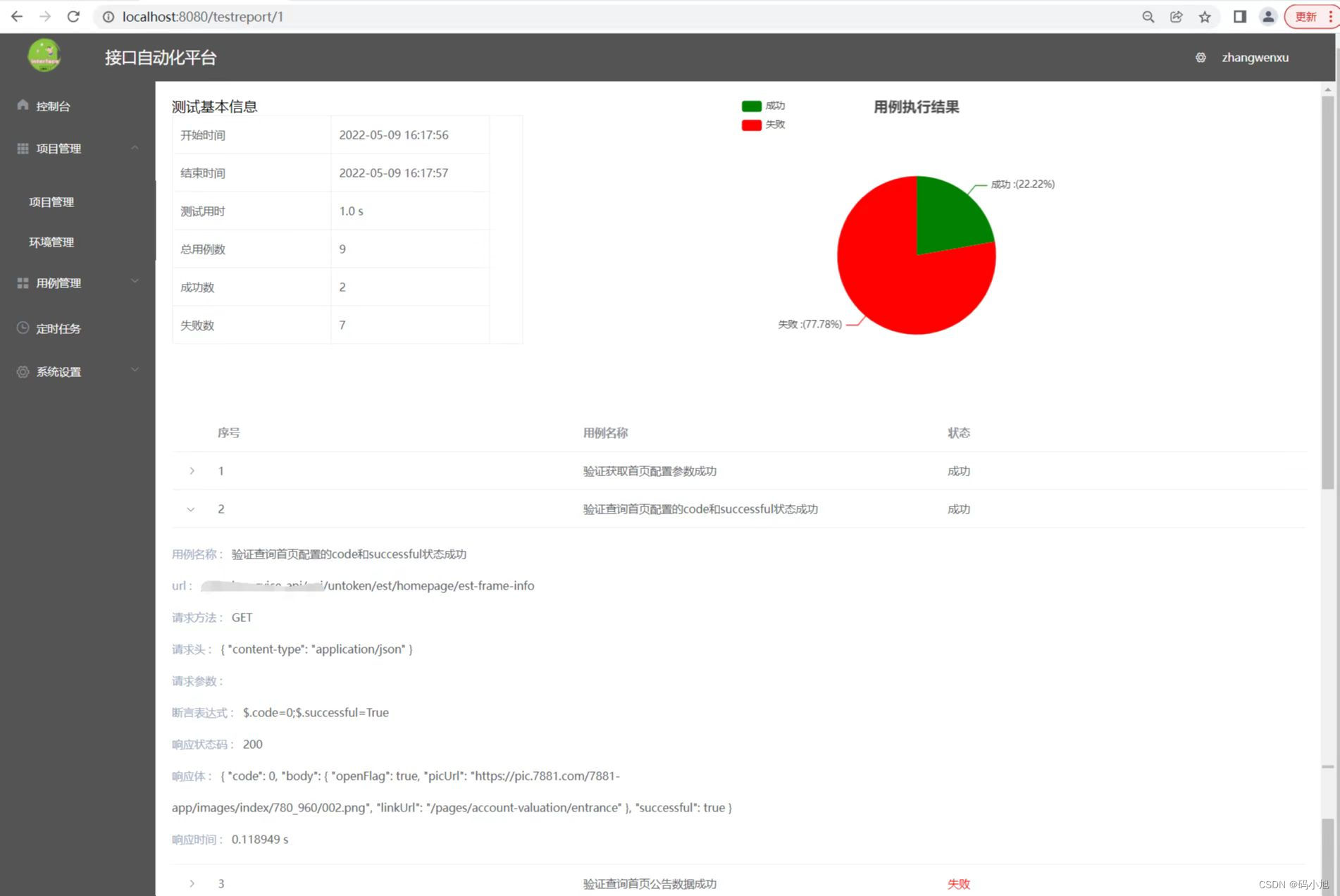
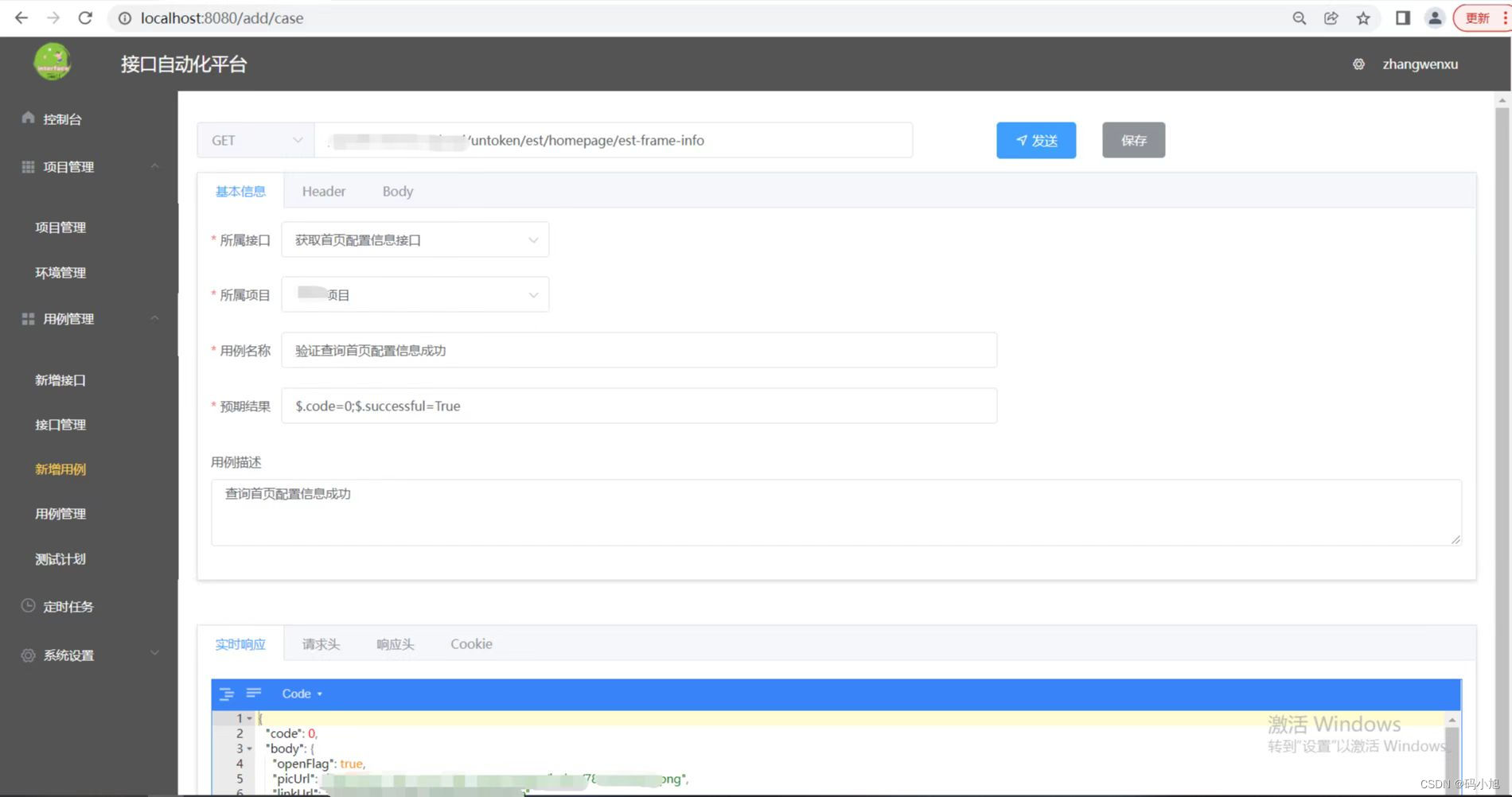
总结
目前框架只实现了基本的功能,未涉及到当接口用例过多时,接口变动,如何快速修改用例,pytest的失败重试、数据库校验、Jenkins集成等问题,后续在根据项目需求加上对应功能。希望大佬们给点好的建议改进改进。
相关文章:
应用统计432考研复试复试提问总结精简版【一】
一、区间估计与假设检验的联系与区别 联系:二者利用样本进行推断,都属于推断统计区别: 原理: 前者是基于大概率,后者基于小概率;统计量:前者是构造枢轴量(不含未知参数,…...

Pytorch模型量化
在深度学习中,量化指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的bit来完成原本以浮点数完成的计算。这么做的好处主要有如下几点: 更少的模型体积,接近4倍的减少;可以更快的计算,由于…...

已解决Encountered error while trying to install package.> lxml
已解决(pip安装第三方模块lxml模块报错)Building wheels for collected packages: lxml Building wheel for lxml (setup.py) … error error: subprocess-exited-with-error python setup.py bdist_wheel did not run successfully. note: This error o…...

距离度量 —— 闵可夫斯基距离(Minkowski Distance)
Python学习系列文章:👉 目录 👈 文章目录一、概述二、计算公式1. 闵氏距离公式2. 闵氏距离的参数 p3. 闵氏距离的缺点一、概述 闵可夫斯基距离 (Minkowski Distance),也被称为 闵氏距离。它不仅仅是一种距离,而是将多…...
python(模块)xlwt
目录一、xlwt简介二、xlwt语法1、模块安装2、模块导入3、向xls文件中写入内容4、设置写入文件的格式4.1 字体设置(font)4.2 背景颜色设置(pattern)4.3 边框设置(borders)4.4 对齐方式设置(align…...

Pytorch中torch.unsqueeze()和torch.squeeze()函数解析
一. torch.squeeze()函数解析 1. 官网链接 torch.squeeze(),如下图所示: 2. torch.squeeze()函数解析 torch.squeeze(input, dimNone, outNone) squeeze()函数的功能是维度压缩。返回一个tensor(张量),其中 input…...
python绘制相关系数热力图
python绘制相关系数热力图一.数据说明和需要安装的库二.准备绘图三.设置配色,画出多幅图全部代码:本文讲述如何利用python绘制如上的相关系数热力图一.数据说明和需要安装的库 数据是31个省市有关教育的12个指标,如下所示。,在文…...
DeepSpeed使用指南(简略版)
现在的模型越来越大,动辄几B甚至几百B。但是显卡显存大小根本无法支撑训练推理。例如,一块RTX2090的10G显存,光把模型加载上去,就会OOM,更别提后面的训练优化。 作为传统pytorch Dataparallel的一种替代,D…...
【Python】tqdm 介绍与使用
文章目录一、tqdm 简介二、tqdm 使用1. 基于迭代对象运行: tqdm(iterator)2. tqdm(list)3. trange(i)4. 手动更新参考链接一、tqdm 简介 tqdm 是一个快速,可扩展的 Python 进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装…...
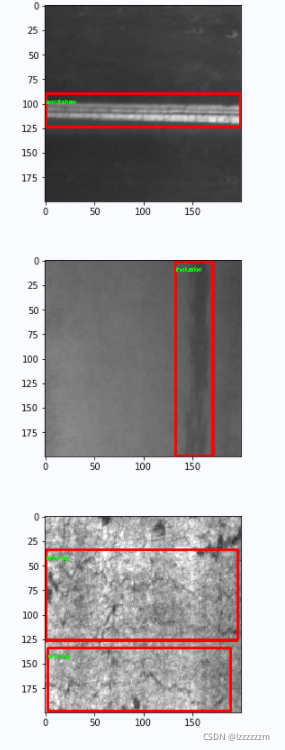
Pytorch机器学习(十)—— 目标检测中k-means聚类方法生成锚框anchor
Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 目录 Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 前言 一、K-means聚类 k-means代码 k-means算法 二、YOLO中使用k-means聚类生成anchor 读取VO…...
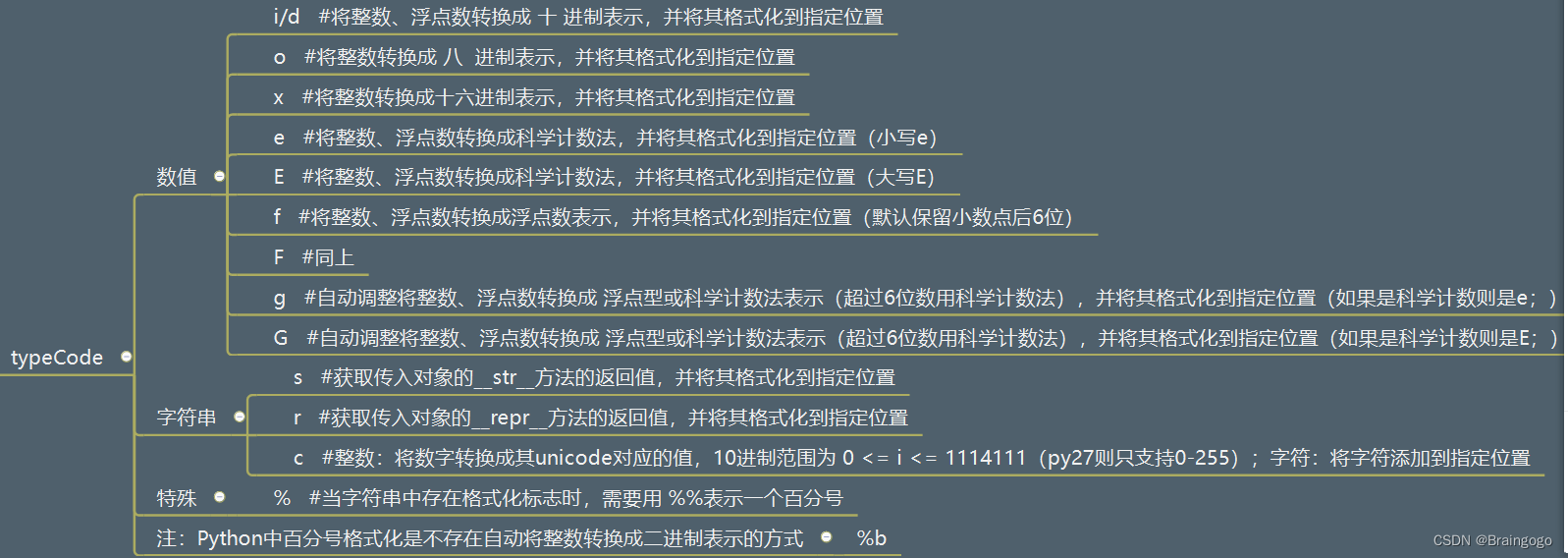
Python的占位格式符
对于print函数里的语句 print("我的名字是%s, 年龄是%d"%(name, age)) 中的%s和%d叫做占位符,它们的完整形态是 %[(name)][flags][width][.precision]typecode 其中带有[]的前缀都是可以省略的。 [(name)]: (name)表示, 根据, 制定的名称(…...
关于sklearn库的安装
对于安装sklearn真的是什么问题都被我遇到了 例如pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(hostfiles.pythonhosted.org, port443): Read timed out.遇到了 这种也遇到了Requirement already satisfied: numpy in c:\users\yjq\appdata\roamin…...
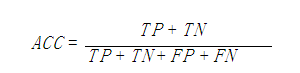
accuracy_score函数
1.acc计算原理 sklearn中accuracy_score函数计算了准确率。 在二分类或者多分类中,预测得到的label,跟真实label比较,计算准确率。 在multilabel(多标签问题)分类中,该函数会返回子集的准确率。如果对于一…...
怎么成为稚晖君?
如何成为IT大佬稚晖君——电子系统设计应具备的基本技能和方法论 快速提高电子技术的必经之路_一些老生常谈的道理 嵌入式AI入坑经历 稚晖君软件硬件开发环境总结 首先,机器学习深度学习这些和硬件是两个领域的内容,个人不建议一起学,注意力…...

Pandas库
Pandas是python第三方库,提供高性能易用数据类型和分析工具。Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用。pandas库引用: import pandas as pd 包括两个数据类型:Series(相当于一维数据类型)&…...

通过两道一年级数学题反思自己
背景 做完这两道题我开始反思自己,到底是什么限制了我?是我自己?是曾经教导我的老师?还是我的父母? 是考试吗?还是什么? 提目 1、正方体个数问题 2、相碰可能性 过程 静态思维: …...
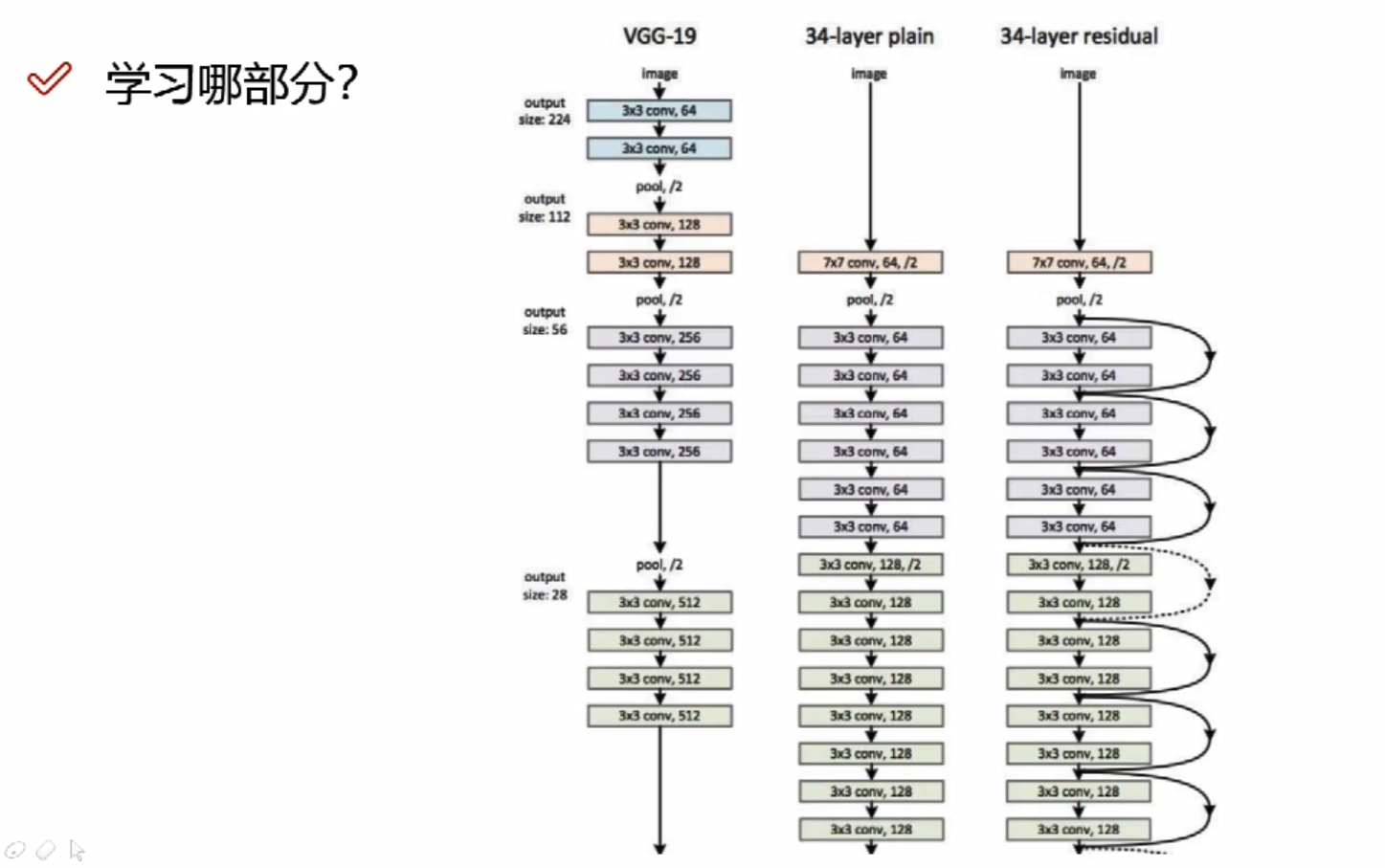
深度学习—卷积神经网络(CNN)全笔记,附代码
本文内容为哔站学习笔记【卷积神经网络-CNN】深度学习(唐宇迪带你学AI):卷积神经网络理论详解与项目实战,计算机视觉,图像识别模块实战_哔哩哔哩_bilibili 目录 深度学习基础 什么是深度学习? 机器学习流…...
Building wheel for mmcv-full (setup.py) ... error解决办法!
mmdetection 安装后,根据官方给的程序安装mmcv时,出现:Building wheel for mmcv-full (setup.py) … error 环境:CUDA11.3, Pytorch1.11 安装根据官网给的安装程序:pip install mmcv-full -f https://download.openmm…...
联邦学习开山之作代码解读与收获
参考:联邦学习代码解读,超详细_一只揪的博客-CSDN博客_联邦学习代码 参考文献:[1602.05629] Communication-Efficient Learning of Deep Networks from Decentralized Data (arxiv.org) 参考代码:GitHub - AshwinRJ/Federated-L…...
Python安装第三方库常用方法 超详细~
Python安装第三方库常用方法前言安装方法1. 通过pychram安装2. pip安装大法3. 下载whl文件到本地离线安装3.1 补充4.其他方法4.1 Python官方的Pypi菜单4.2 国内镜像源解决pip安装过慢的问题小结前言 在pyhton的学习中,相信大家通常都会碰到第三方库的安装问题&…...
Python--找出字符串中出现次数最多的字符及其出现的次数
方法一: 1、循环遍历列表或字符串,如果字符在字典中则值加1,如果不在则创建(key,value) 2、找到字典中,最大的value值 3、根据最大的value值,找对应的key值,打印出出现次数最多的字符 str &qu…...

滤波笔记一:卡尔曼滤波(Kalman Filtering)详解
本笔记是总结了B站DR_CAN的卡尔曼滤波器的课程,他的B站主页为:DR_CAN的个人空间_哔哩哔哩_bilibili PS:虽然我不是学自控的,但是老师真的讲的很好! 目录 Lesson1 递归算法 Lesson2 数学基础_数据融合_协方差矩阵_状态空间方程…...
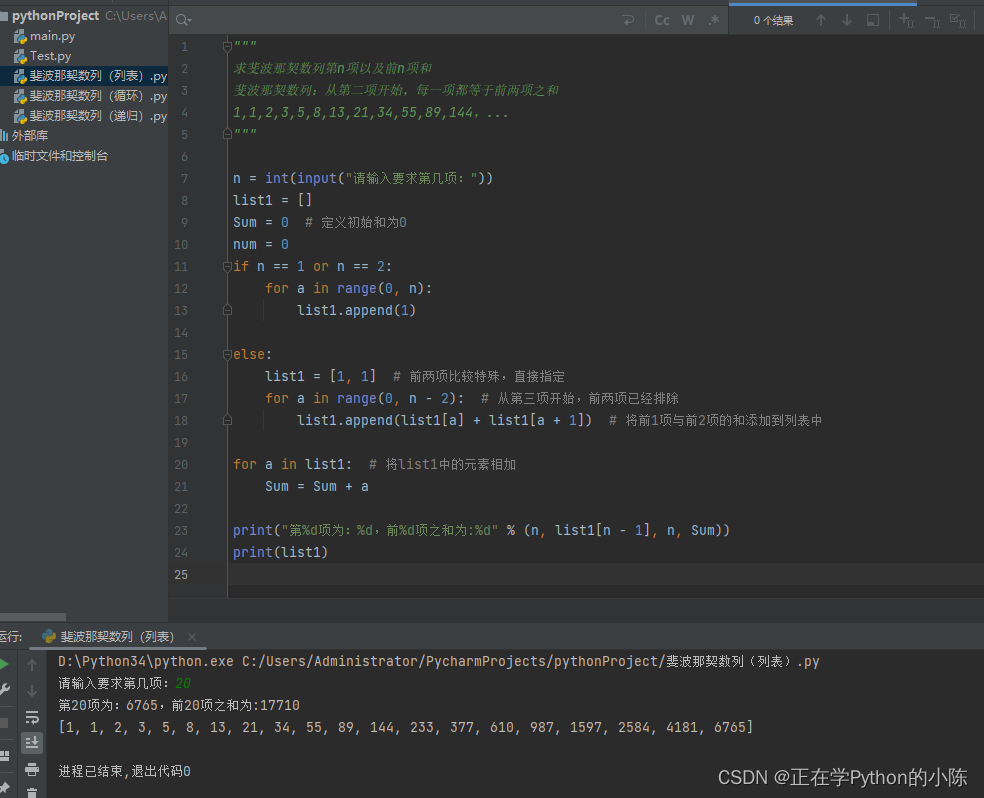
利用Python求斐波那契数列的第N项以及前N项和(循环、递归、集合)
著名的斐波那契数列,即从第三项开始,每一项都等于前两项之和。 之前写过利用Java语言来编写,由于最近正在学Python,所以将自己的想法记录在此,有需要的朋友可以参考一下。 写在前面:这里的三个方法其实思…...
一文速学(十八)-数据分析之Pandas处理文本数据(str/object)各类操作+代码一文详解(三)
目录 前言 一、子串提取 提取匹配首位子串 提取所有匹配项(extractall)...
Python数据分析-数据预处理
数据预处理 文章目录数据预处理1.前言2.数据探索2.1缺失值分析2.2 异常值分析2.2.1 简单统计量分析2.2.2 3$\sigma$原则2.2.3 箱线图分析2.3 一致性分析2.4 相关性分析3.数据预处理3.1 数据清洗3.1.1 缺失值处理3.1.2 异常值处理3.2 数据集成3.2.1 实体识别3.2.2 冗余属性识别3…...
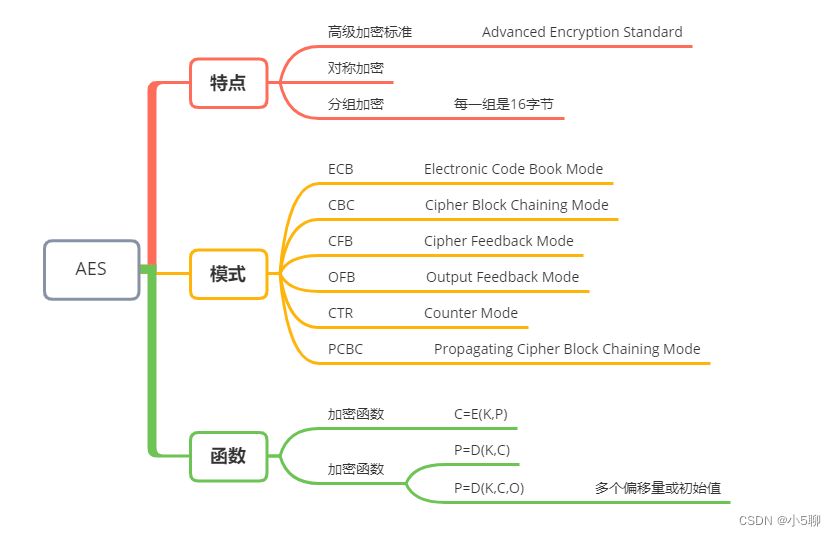
【Python】AES加解密代码,文章还有加密串等你来解密,等你来挑战
🍦🍦写这篇AES文章也是有件趣事,有位小伙伴发了段密文,看看谁解密速度快,学过Python的小伙伴一下子就解开来了,内容也挺有趣的。 🍟🍟原来加解密也可以这么有趣,虽然看起…...
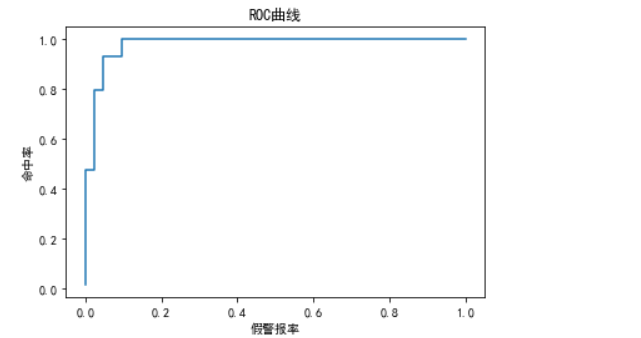
朴素贝叶斯模型及案例(Python)
目录 1 朴素贝叶斯的算法原理 2 一维特征变量下的贝叶斯模型 3 二维特征变量下的贝叶斯模型 4 n维特征变量下的贝叶斯模型 5 朴素贝叶斯模型的sklearn实现 6 案例:肿瘤预测模型 6.1 读取数据与划分 6.1.1 读取数据 6.1.2 划分特征变量和目标变量 6.2 模型…...
python之Tkinter详解
Python之Tkinter详解 文章目录Python之Tkinter详解1、Tkinter是什么2、Tkinter创建窗口①导入 tkinter的库 ,创建并显示窗口②修改窗口属性③创建按钮④窗口内的组件布局3、Tkinter布局用法①基本界面、label(标签)和button(按钮)用法②entry(输入)和text(文本)用法…...

【python】python进行debug操作
文章目录前言一、debug环境介绍二、debug按钮介绍2.1、step into:单步执行(遇到函数也是单步)2.2、step over:单步执行(遇到函数,全部运行)2.3、step into my code:(直接跳到下一个断点)2.4、st…...

Python安装tensorflow过程中出现“No matching distribution found for tensorflow”的解决办法
在Pycharm中使用pip install tensorflow安装tensorflow时报错: ERROR: Could not find a version that satisfies the requirement tensorflow(from versions: none) ERROR: No matching distribution found for tensorflow搜了好多帖子有的说可能是网络的问题&…...

pandas中的read_csv参数详解
1.官网语法 pandas.read_csv(filepath_or_buffer, sepNoDefault.no_default**,** delimiterNone**,** headerinfer’, namesNoDefault.no_default**,** index_colNone**,** usecolsNone**,** squeezeFalse**,** prefixNoDefault.no_default**,** mangle_dupe_colsTrue**,** dty…...
Python — — turtle 常用代码
目录 一、设置画布 二、画笔 1、画笔属性 2、绘图命令 (1) 画笔运动命令 (2) 画笔控制命令 (3) 全局控制命令 (4) 其他命令 3. 命令详解 三、文字显示为一个圆圈 四、画朵小花 一、设置画布 turtle为我们展开用于绘图区域,我们可以设置它的…...

【我是土堆 - PyTorch教程】学习随手记(已更新 | 已完结 | 10w字超详细版)
目录 1. Pytorch环境的配置及安装 如何管理项目环境? 如何看自己电脑cuda版本? 安装Pytorch 2. Python编辑器的选择、安装及配置 PyCharm PyCharm神器 Jupyter(可交互) 3. Python学习中的两大法宝函数 说明 实战操…...
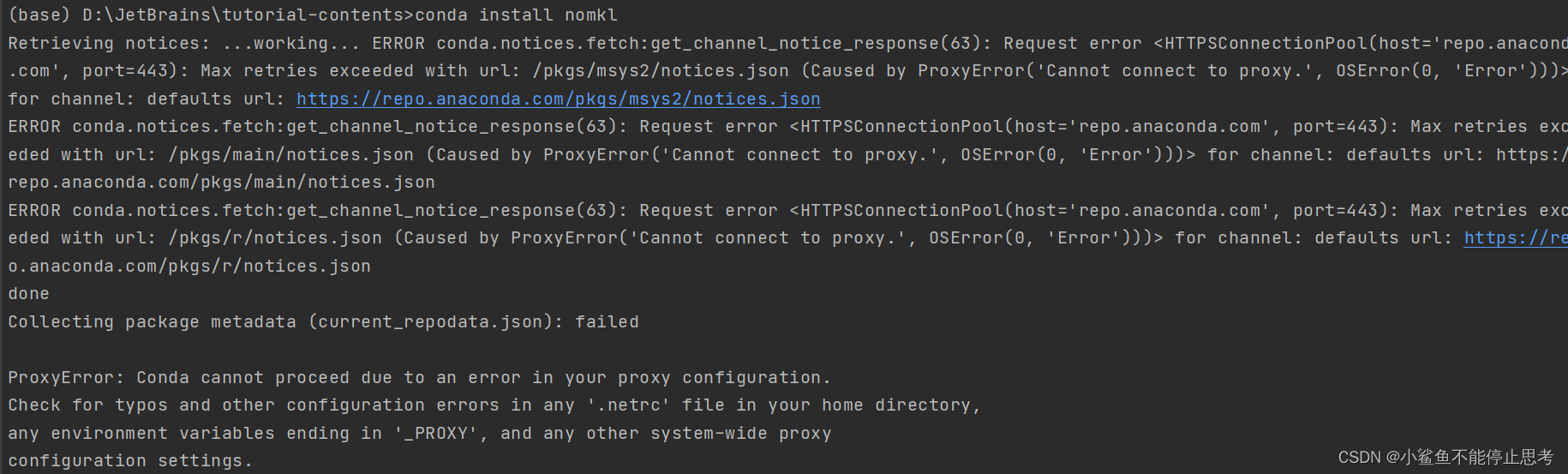
“OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.”解决方法总结
一、问题描述 跑了点神经网络的代码,想画几个激活函数的图像,代码如下: 运行后报了以下错误: 翻译如下: OMP:错误 #15:正在初始化 libiomp5md.dll,但发现 libiomp5md.dll 已经初…...
python3.11.2安装 + pycharm安装
下载 :https://www.python.org/ 2.双击下载的软件: 3.进入安装界面 下一步,点击 是 上一步点击后就看到如下: 安装成功了,接下来检测一下:cmd 安装pycharm PyCharm是一种Python IDE(Integr…...
Python中numpy.polyfit的用法详解
numpy中polyfit的用法 参数 polyfit(x, y, deg, rcondNone, fullFalse, wNone, covFalse):x:M个采样点的横坐标数组; y:M个采样点的纵坐标数组;y可以是一个多维数组,这样即可拟合相同横坐标的多个多项式; deg:多项式…...
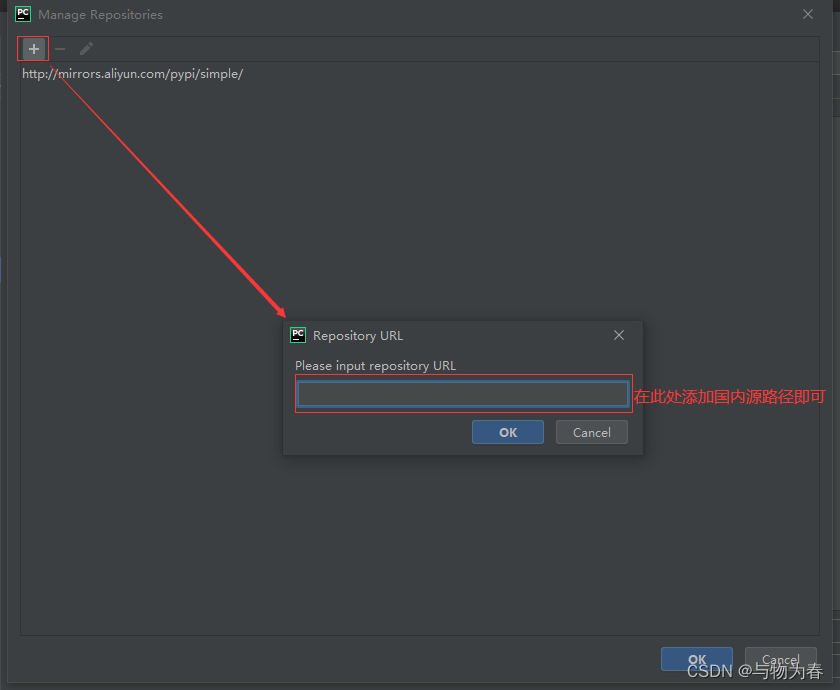
彻底解决Python包下载慢问题
python默认使用的是国外镜像,有时候下载非常慢,最快的办法就是在下载命令中增加国内源: 常用的国内源如下: 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/ 阿里云:http://mirrors.aliyun.com/pypi/…...
Anaconda 使用指南,少走弯路
anaconda包管理器和环境管理器,强烈建议食用 1.下载 官网下载太慢可选用镜像下载 官网下载 :Anaconda | Individual Editionhttps://www.anaconda.com/products/distribution 镜像下载:Index of /anaconda/archive/ | 清华大…...
使用stable diffusion webui时,安装gfpgan失败的解决方案(windows下的操作)
1.问题描述 初次打开stable diffusion webui时,需要安装gfpgan等github项目。但在安装gfpgan时,显示RuntimeError: Couldnt install gfpgan 2.解决方案 无法安装gfpgan的原因是网络问题,就算已经科学上网,并设置为全局&#x…...

Python 中导入csv数据的三种方法
这篇文章主要介绍了Python 中导入csv数据的三种方法,内容比较简单,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下微点阅读小编收集的文章介绍。 Python 中导入csv数据的三种方法,具体内容如下所示: 1、通过…...
相关性分析、相关系数矩阵热力图
相关性 相关性分析是研究两组变量之间是否具有线性相关关系,所以做相关性分析的前提是假设变量之间存在线性相关性,得到的结果也是描述变量间的线性相关程度。除此之外,相关性分析方法还会有其他的假设条件。而灰色关联度分析首先对数据量要求…...
【python123】题目答案整理 ------更多答案见专栏
目录 二老鼠打洞 来自计算机的问候-任意数量参数 自定义幂函数 来自计算机的问候-多参函数 编写函数输出自除数 最大素数 求数列前n项的平方和 生兔子 计算圆周率——割圆法 数列求前n项和 素数: *如有错误请私聊纠正 二老鼠打洞 nint(input()) # 每日打…...
Python编程题汇总
Python编程复习 1.1找出列表中单词最长的一个 找出列表中单词最长的一个def test():a ["hello", "world", "yoyo", "congratulations"]length len(a[0])# 在列表中循环for i in a:if len(i) > length:length ireturn length p…...
Matplotlib详解
视频教程 1.什么是matplotlib matplotlib: 最流行的Python底层绘图库,主要做数据可视化图表,名字取材于MATLAB,模仿MATLAB构建 2.样例 2.1折线图 eg:假设一天中每隔两个小时(range(2,26,2))的气温(℃)分别是[15,13,14.5,17,20,25,26,26,…...

Jetson AGX Orin安装Anaconda、Cuda、Cudnn、Pytorch、Tensorrt最全教程
文章目录一:Anaconda安装二:Cuda、Cudnn安装三:Pytorch安装四:Tensorrt安装一:Anaconda安装 Jetson系列边缘开发板,其架构都是arm64,而不是传统PC的amd64,深度学习的环境配置方法大…...
pytorch入门篇2 玩转tensor(查看、提取、变换)
上一篇博客讲述了如何根据自己的实际需要在pytorch中创建tensor:pytorch入门篇1——创建tensor,这一篇主要来探讨关于tensor的基本数据变换,是pytorch处理数据的基本方法。 文章目录1 tensor数据查看与提取2 tensor数据变换2.1 重置tensor形状…...

随机森林算法
随机森林1.1定义1.2随机森林的随机性体现的方面1.3 随机森林的重要作用1.4 随机森林的构建过程1.5 随机森林的优缺点2. 随机森林参数描述3. 分类随机森林的代码实现1.1定义 随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法。随机森林非常简单&am…...
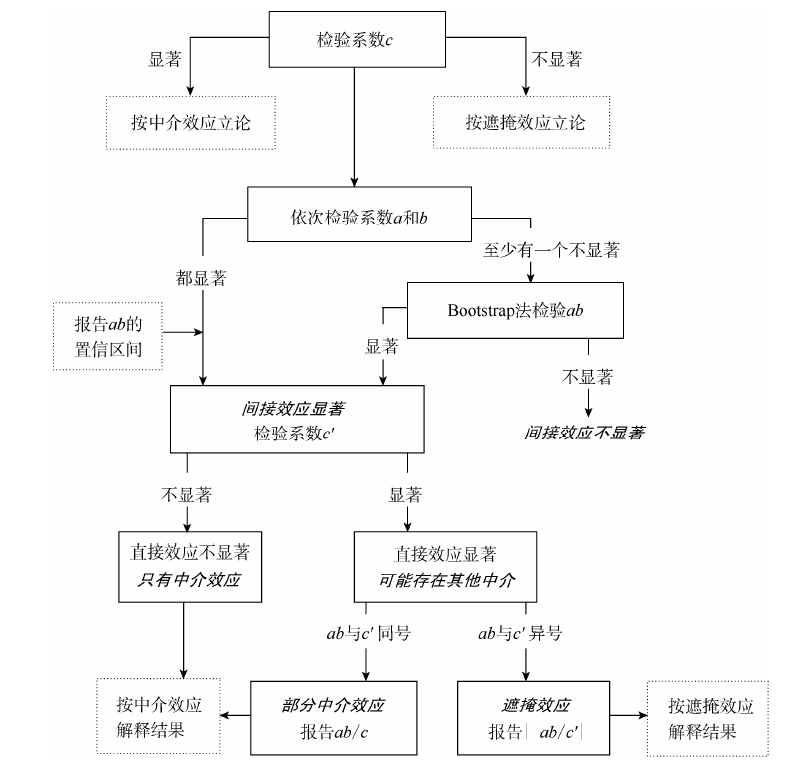
实证分析 | 中介效应检验原理与Stata代码实现
前言 本文是温忠鳞和叶宝娟2014年刊载于《心理科学进展》的论文《中介效应分析:方法和模型发展》的简要笔记与拓展。 温忠麟、叶宝娟:《中介效应分析:方法和模型发展》,《心理科学进展》,2014年第5期 中介效应检验 要…...

几个代码画出漂亮的词云图,python最简单的词云图教程(建议收藏)
在开始编写程序之前,我们先了解一下词云图的作用,我们拿到一篇文章,想得到一些关键词,但文章篇幅很大,无法短时间得到关键词,这时我们可以通过程序将文章中的每个词组识别出来,统计每个词组出现…...

mac m1,m2 安装 提供GPU支持的pytorch和tensorflow
mac m1,m2 安装 提供GPU支持的pytorch和tensorflowAnaconda安装测试Pytorch参考链接安装步骤安装 Xcode创建conda环境测试加速效果注意Tensorflow参考链接安装步骤安装 Xcode指定安装环境加速效果测试The Endmac m1 刚出的时候,各种支持都不完善。那时候要使用conda…...