百度飞桨PaddleSpeech的简单使用
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型,一些典型的应用示例如下:语音识别、语音翻译 (英译中)、语音合成、标点恢复等。
我只用到了语音识别(语音转文字)、语音合成(文字转语音)。
安装
我只在CentOS上用了(虚拟机CentOS Linux release 7.9.2009和云服务器CentOS Linux release 8.5.2111),因截止到写这篇文章(2022年11月18日),官方README中说
我们强烈建议用户在 Linux 环境下,3.7 以上版本的 python 上安装 PaddleSpeech。
linux
- yum install gcc gcc-c++ # from https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install_cn.md#linux
- pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple # GPU版去官网看命令
- pip install pytest-runner
- pip install setuptools_scm # 安装paddlespeech需要,否则报错ERROR: Could not find a version that satisfies the requirement setuptools_scm (from versions: none)和ERROR: No matching distribution found for setuptools_scm,且这两句报错没有高亮,而是在高亮的报错'error: subprocess-exited-with-error'的下面。from https://github.com/PaddlePaddle/PaddleSpeech/issues/2150
- pip install paddlespeech -i https://pypi.tuna.tsinghua.edu.cn/simple
- 从安装文档中下载nltk_data并解压到家目录,文字转语音需要它 # from https://github.com/PaddlePaddle/PaddleSpeech/issues/2456
- yum install libsndfile # 运行若报错OSError: sndfile library not found和OSError: cannot load library 'libsndfile.so': libsndfile.so: cannot open shared object file: No such file or directory再装。from https://github.com/PaddlePaddle/PaddleSpeech/issues/2198和https://github.com/PaddlePaddle/PaddleSpeech/issues/440,但这两个链接中的命令不对
指定源是因为安装文档中建议的
- 提示: 我们建议在安装
paddlepaddle的时候使用百度源 https://mirror.baidu.com/pypi/simple ,而在安装paddlespeech的时候使用清华源 https://pypi.tuna.tsinghua.edu.cn/simple 。
不过README中没说要指定源。
显卡驱动的安装可以看我另一篇文章。
使用
如果你的机器CPU或内存不够,可能运行不起来代码,终端中能看到进程会被自动结束掉。
测试语音转文字时,我用手机的录音机录了wav音频,用PaddleSpeech转文字时提示
The sample rate of the input file is not 16000.The program will resample the wav file to 16000.If the result does not meet your expectations,Please input the 16k 16 bit 1 channel wav file.
它要求音频文件的采样率是16000Hz,如果输入的文件不符合要求,根据提示按y后,程序会自动将音频文件调整成它能识别的样子,然后给出识别结果。此时我用的官方的示例代码,只不过音频文件是我自己录的。
from paddlespeech.cli.asr.infer import ASRExecutor
asr = ASRExecutor()
result = asr(audio_file="luyin.wav")
print(result)我需要把这个功能写成接口,接口中程序运行时,若输入的音频文件不符合要求,用户是无法用键盘进行交互的,导致输入的音频无法被转成文字。这就需要提前将音频文件转成16k 16 bit 1 channel wav,然后将转换后的音频文件传给PaddleSpeech。我不知道源码中有没有提供可供调用的转换函数(因为服务器上只有vim,找代码看代码不方便),我直接用ffmpeg转换了(python执行shell命令),ffmpeg的安装可以参考这两个链接:CentOS安装使用ffmpeg - 开普勒醒醒吧 - 博客园 (cnblogs.com)、centos 安装ffmpeg_qq_duhai的博客-CSDN博客。
也可以直接在这里下载静态编译好的,不用自己解决依赖问题。
ffmpeg -y -i input.wav -ac 1 -ar 16000 -b:a 16k output.wav # from https://blog.csdn.net/Ezerbel/article/details/124393431这个命令输出的文件的格式,和PaddleSpeech给的示例zh.wav的格式一样,可以用PotPlayer查看。
接口形式的语音转文字、文字转语音的完整代码
import os
import random
import time
import json
import base64
import shutil
from paddlespeech.cli.asr.infer import ASRExecutor
from paddlespeech.cli.tts.infer import TTSExecutor
from flask import Flask, request
app=Flask(__name__)
asr = ASRExecutor() # 初始化成全局变量,防止多次初始化导致显存不够 from https://github.com/PaddlePaddle/PaddleSpeech/issues/2881和https://github.com/PaddlePaddle/PaddleSpeech/issues/2908
tts = TTSExecutor()
# 公共函数,所有接口都能用
def random_string(length=32): # 生成32位随机字符串,为了生成随机文件名
string='abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'
return ''.join(random.choice(string) for i in range(length))
# 公共函数,所有接口都能用
def base64_to_audio(audio_base64, folder_name=None): # 服务器上用folder_name参数,用于在audio_file_path中拼接路径,如f'/home/www/card/{folder_name}/',不同的folder_name对应不同的识别任务(如身份证识别、营业执照识别),本地测试不用
audio_base64 = audio_base64.split(',')[-1]
audio = base64.b64decode(audio_base64)
audio_file_name = random_string() + '_' + (str(time.time()).split('.')[0]) # 不带扩展名,因为不知道收到的音频文件的原始扩展名,手机录的不一定是什么格式
audio_file_path = f'/home/python/speech/{folder_name}/' + audio_file_name
with open(audio_file_path, 'wb') as f:
f.write(audio)
return audio_file_path
# 将收到的音频文件转为16k 16 bit 1 channel的wav文件,16k表示16000Hz的采样率,16bit不知道是什么
# 若给paddlespeech传的文件不对,会提示The sample rate of the input file is not 16000.The program will resample the wav file to 16000.If the result does not meet your expectations,Please input the 16k 16 bit 1 channel wav file.所以要提前转换。
def resample_rate(audio_path_input):
audio_path_output = audio_path_input + '_output' + '.wav' # 传入的audio_path_input不带扩展名,所以后面直接拼接字符串
command = f'ffmpeg -y -i {audio_path_input} -ac 1 -ar 16000 -b:a 16k {audio_path_output}' # 这个命令输出的wav文件,格式上和PaddleSpeech在README中给的示例zh.wav(https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav,内容是'我认为跑步最重要的就是给我带来了身体健康')一样。from https://blog.csdn.net/Ezerbel/article/details/124393431
command_result = os.system(command) # from https://blog.csdn.net/liulanba/article/details/115466783
assert command_result == 0
if os.path.exists(audio_path_output):
return audio_path_output
elif not os.path.exists(audio_path_output): # ffmpeg输出的文件不存在,可能是ffmpeg命令没执行完,等1秒(因在虚拟机测试转一个8.46M的MP3需0.48秒),1秒后若还没有输出文件,说明报错了
time.sleep(1)
if os.path.exists(audio_path_output):
return audio_path_output
else:
return None
# 语音转文字
# 只接受POST方法访问
@app.route("/speechtotext",methods=["POST"])
def speech_to_text():
audio_file_base64 = request.get_json().get('audio_file_base64') # 要转为文字的语音文件的base64编码,开头含不含'data:audio/wav;base64,'都行
audio_file_path = base64_to_audio(audio_file_base64, folder_name='speech_to_text/audio_file') # 存放收到的原始音频文件
audio_path_output = resample_rate(audio_path_input=audio_file_path)
if audio_path_output:
# asr = ASRExecutor()
result = asr(audio_file=audio_path_output) # 会在当前代码所在文件夹中产生exp/log文件夹,里面是paddlespeech的日志文件,每一次调用都会生成一个日志文件。记录这点时的版本号是paddlepaddle==2.3.2,paddlespeech==1.2.0。 from https://github.com/PaddlePaddle/PaddleSpeech/issues/1211
os.remove(audio_file_path) # 识别成功时删除收到的原始音频文件和转换后的音频文件
os.remove(audio_path_output)
# try:
# shutil.rmtree('') # 删除文件夹,若文件夹不存在会报错。若需删除日志文件夹,用这个。from https://blog.csdn.net/a1579990149wqh/article/details/124953746
# except Exception as e:
# pass
return json.dumps({'code':200, 'msg':'识别成功', 'data':result}, ensure_ascii=False)
else:
return json.dumps({'code':400, 'msg':'识别失败'}, ensure_ascii=False)
# 文字转语音
# 只接受POST方法访问
@app.route("/texttospeech",methods=["POST"])
def text_to_speech():
text_str = request.get_json().get('text') # 要转为语音的文字
# tts = TTSExecutor()
audio_file_name = random_string() + '_' + (str(time.time()).split('.')[0]) + '.wav'
audio_file_path = '/home/python/speech/text_to_speech/audio_file' + audio_file_name
tts(text=text_str, output=audio_file_path) # 输出24k采样率wav格式音频。同speech_to_text()中一样,会在当前代码所在文件夹中产生exp/log文件夹,里面是paddlespeech的日志文件,每一次调用都会生成一个日志文件。
if os.path.exists(audio_file_path):
with open(audio_file_path, 'rb') as f:
base64_str = base64.b64encode(f.read()).decode('utf-8') # 开头不含'data:audio/wav;base64,'
os.remove(audio_file_path) # 识别成功时删除转换后的音频文件
# try:
# shutil.rmtree('') # 删除文件夹,若文件夹不存在会报错。若需删除日志文件夹,用这个。from https://blog.csdn.net/a1579990149wqh/article/details/124953746
# except Exception as e:
# pass
return json.dumps({'code':200, 'msg':'识别成功', 'data':base64_str}, ensure_ascii=False)
elif not os.path.exists(audio_file_path):
return json.dumps({'code':400, 'msg':'识别失败'}, ensure_ascii=False)
if __name__=='__main__':
app.run(host='127.0.0.1', port=9723)最后
如果你想调整语速,可以看请问自己 finetune 的 tts 模型能够改变语速吗? · Issue #2383 · PaddlePaddle/PaddleSpeech · GitHub
如果你用的是GPU版,查看是否调用了GPU,请问语音合成可以使用GPU进行推理吗,如果可以应该怎么操作呢? · Issue #2467 · PaddlePaddle/PaddleSpeech · GitHub,也可以用nvidia-smi命令查看GPU占用情况
如果在使用过程中遇到显存未释放,导致显存不够,可以看音频转文字过程中显存不断增加,最终 out of memory · Issue #2881 · PaddlePaddle/PaddleSpeech · GitHub
[TTS]使用gpu合成后显存未释放 · Issue #2908 · PaddlePaddle/PaddleSpeech · GitHub
相关文章:
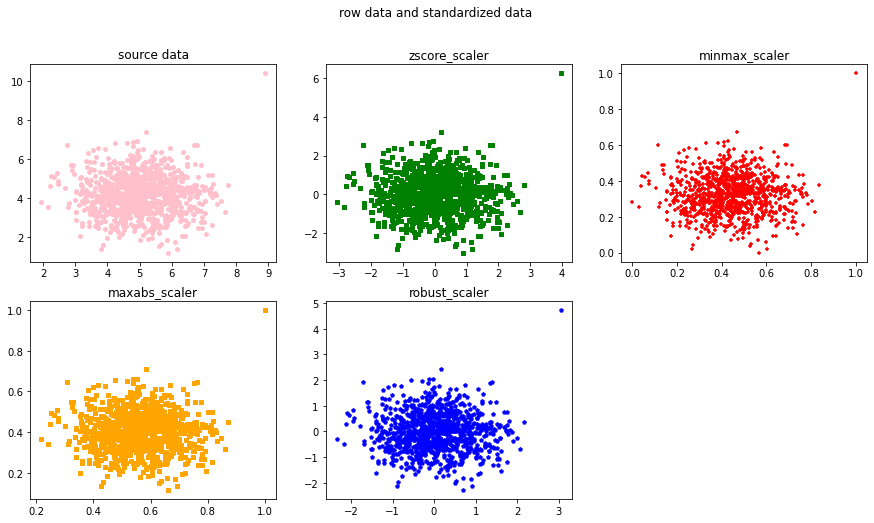
Python数据标准化
目录 一.数据标准化方式 1.实现中心化和正态分布的Z-Score 2.实现归一化的Max-Min 3.用于稀疏数据的MaxAbs 4.针对离群点的RobustScaler 二.Python针对以上几种标准化方法处理数据 三.总结 一.数据标准化方式 1.实现中心化和正态分布的Z-Score Z-Score标准化是基于原…...
Pycharm无法下载汉化包,一招教你搞定
Pycharm无法下载汉化包,一招教你搞定Pycharm直接导入汉化包Pycharm 无法采用自带的插件安装汉化包Pycharm直接导入汉化包 Pycharm 是可以直接导入汉化包的,这为很多初学者省区了不少麻烦。具体就是: 1:点击pycharm界面右上角的设…...

python成功实现“高配版”王者小游戏?【赠源码】
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 本游戏完整源码、素材: 点击此处跳转文末名片获取 咳咳,又是一款新的小游戏,就是大家熟悉的王者~ 来看我用python来实现高(di)配版的王者 是一款拿到代码运行后,…...
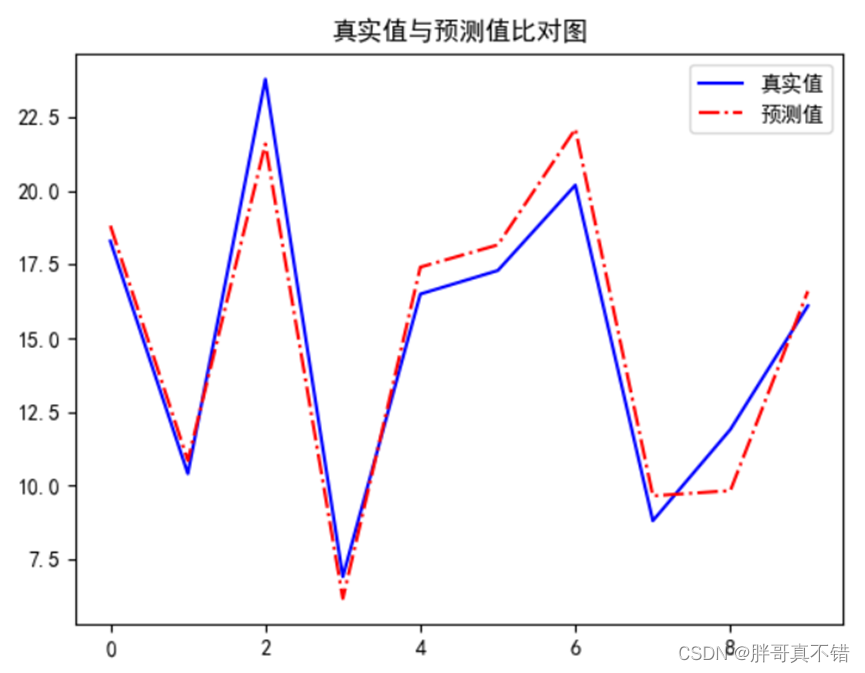
【项目实战】Python实现多元线性回归模型(statsmodels OLS算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 回归问题是一类预测连续值的问题,而能满足这样要求的数学模型称作回归模型,本项…...
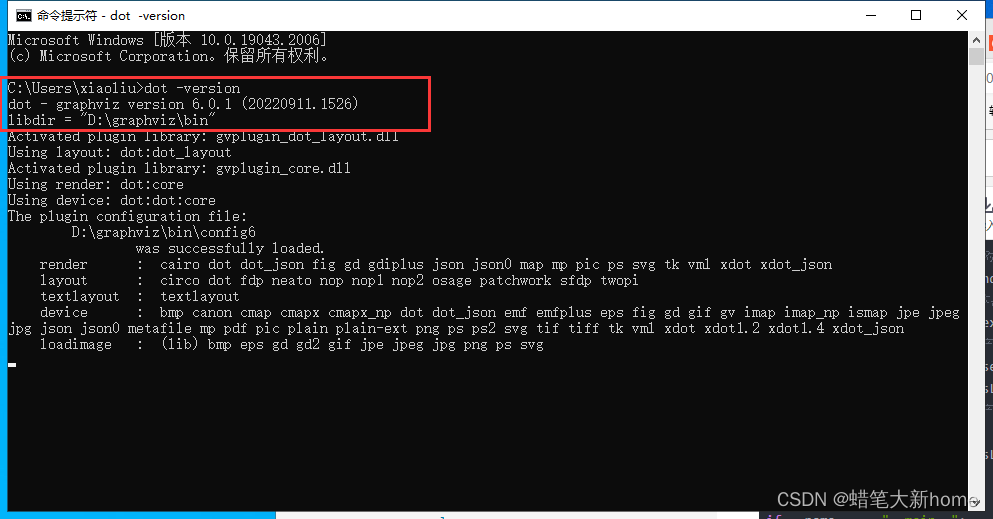
graphviz安装教程(2022最新版)初学者适用
1、首先在官网下载graphviz 下载网址:https://www.graphviz.org/download/ 2、安装。 打开第一步已经下载好的软件。点击下一步,在安装路径选择时可将安装路径修改为 D:\graphviz 接着一直点下一步,即可安装完成。 3、配置环境变量 右键…...

【Windows】搭建Pytorch环境(GPU版本,含CUDA、cuDNN),并在Pycharm上使用(零基础小白向)
文章目录前言一、安装CUDA1、检查电脑是否支持CUDA2、下载并安装CUDA3、下载并安装cuDNN二、安装Pytorch1、安装Anaconda2、切换清华镜像源3、创建环境并激活4、输入Pytorch安装命令5、测试三、在Pycharm上使用搭建好的环境参考文章前言 本人纯python小白,第一次使用…...

Tensorflow与CUDA、cudnn版本对应关系
不同版本的Tensorflow需对应不同的CUDA和cudnn版本,否者容易安装失败。可按下图所示,根据想要安装的Tensorflow版本,选择对应版本的CUDA和cudnn。 其中CUDA的下载链接为: CUDA Toolkit Archive | NVIDIA Developer cudnn下载链…...
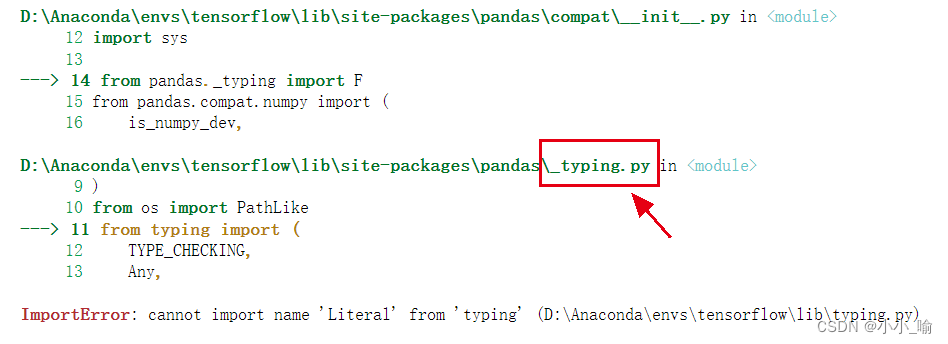
ImportError: cannot import name ‘Literal‘ from ‘typing‘ (D:\Anaconda\envs\tensorflow\lib\typing.py)
报错背景: 因为安装tensorflow-gpu版本需要,我把原来的新建的anaconda环境(我的名为tensorflow)中的python3.8降为了3.7。 在导入seaborn包时,出现了以下错误: ImportError: cannot import name Literal …...

100天精通Python(数据分析篇)——第67天:Pandas数据连接、合并、加入、添加、重构函数(merge、concat、join、append、stack、unstack)
文章目录 一、数据连接(pd.merge)1. left、right2. how3. on4. left_on、right_on5. sort6. suffixes7. left_index、right_index二、数据合并(pd.concat)1. index 没有重复的情况2. index 有重复的情况3. DataFrame合并时同时查看行索引和列索引有无重复三、数据加入(pd.…...
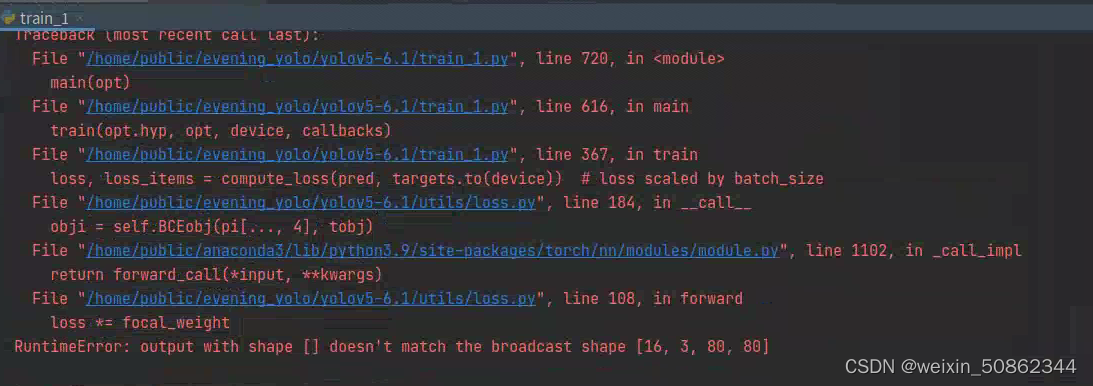
yolov5 优化系列(三):修改损失函数
1.使用 Focal loss 在util/loss.py中,computeloss类用于计算损失函数 # Focal lossg h[fl_gamma] # focal loss gammaif g > 0:BCEcls, BCEobj FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)其中这一段就是开启Focal loss的关键!!&…...
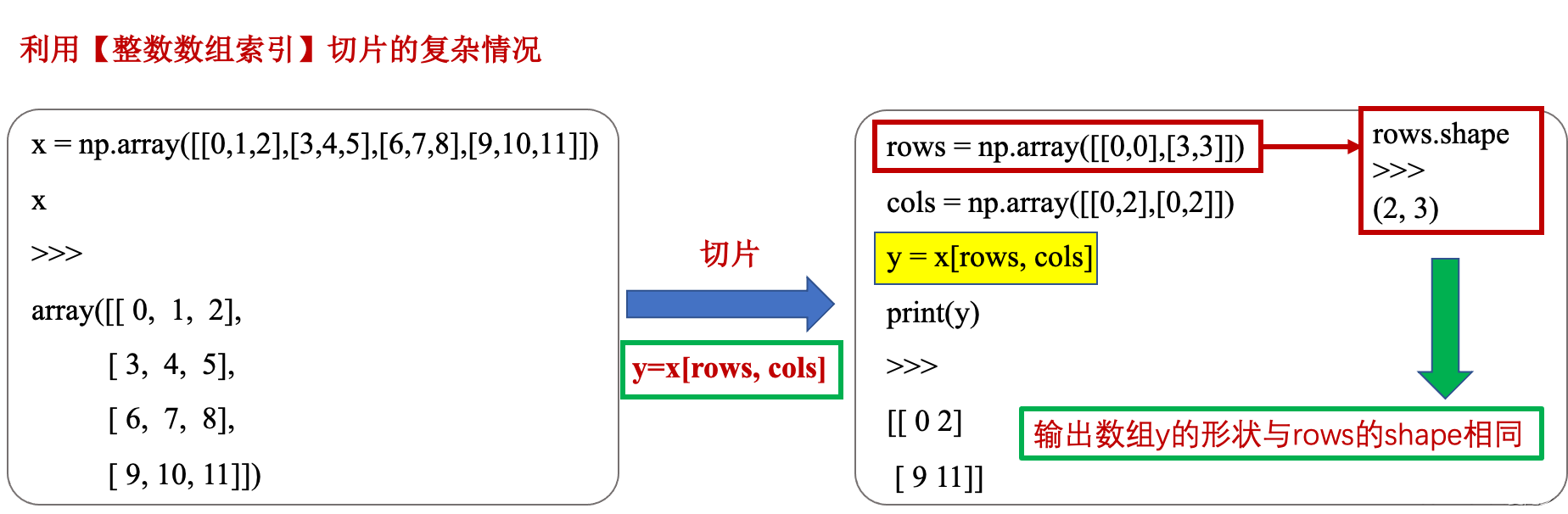
Python中数组切片的用法详解
Python中数组切片的用法详解一、python中“::-1”代表什么?二、python中“:”的用法三、python中数组切片三、numpy中的整数数组索引四、numpy中借助【切片 : 或 …与索引数组】组合进行复杂切片五、布尔索引六、花式索引一、python中“::-1”代表什么? …...
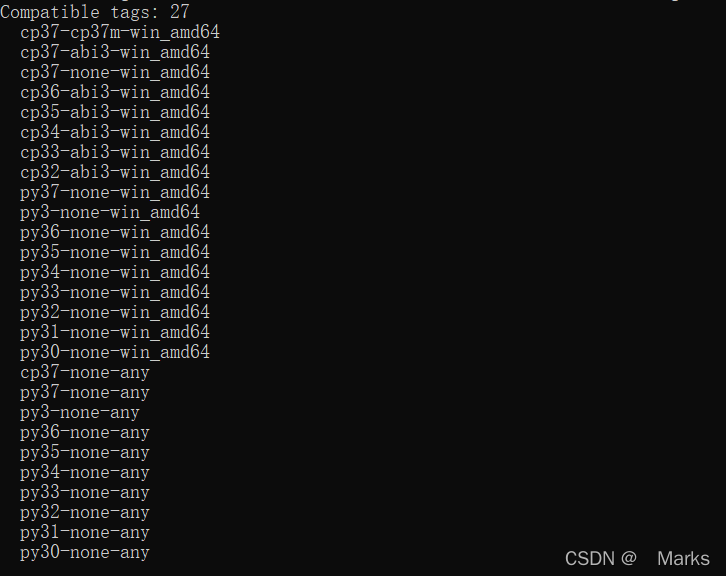
python 安装whl文件
前言 WHL文件是以Wheel格式保存的Python安装包,Wheel是Python发行版的标准内置包格式。在本质上是一个压缩包,WHL文件中包含了Python安装的py文件和元数据,以及经过编译的pyd文件,这样就使得它可以在不具备编译环境的条件下&#…...
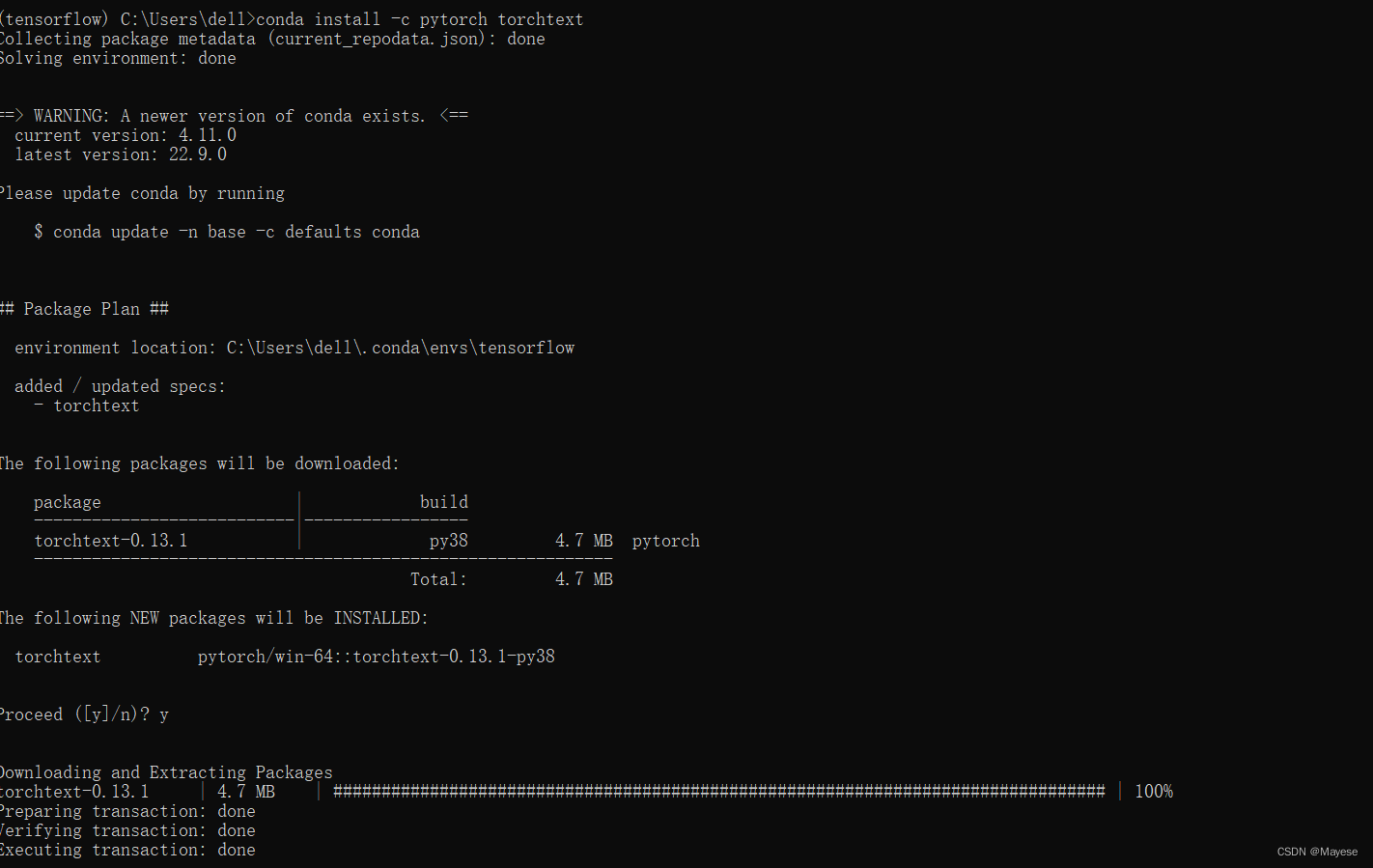
Pycharm中安装pytorch
配置虚拟环境 为什么要安装虚拟环境?虚拟环境:把一部分内容独立出来,称之为容器。在容器中,安装我们自己想要的东西,比如不容版本的依赖包。各容器之间相互独立,互不影响。比如下载完 Anaconda 之后&#…...
Package | 解决 module ‘cv2‘ has no attribute ‘gapi_wip_gst_GStreamerPipeline‘
. 问题背景 由于这个问题出现了两回,决定记录一下。实验背景是使用opencv python库进行数据预处理,遇到报错信息如下: “ import cv2 File “/opt/conda/lib/python3.8/site-packages/cv2/init.py”, line 181, in bootstrap() File “/op…...
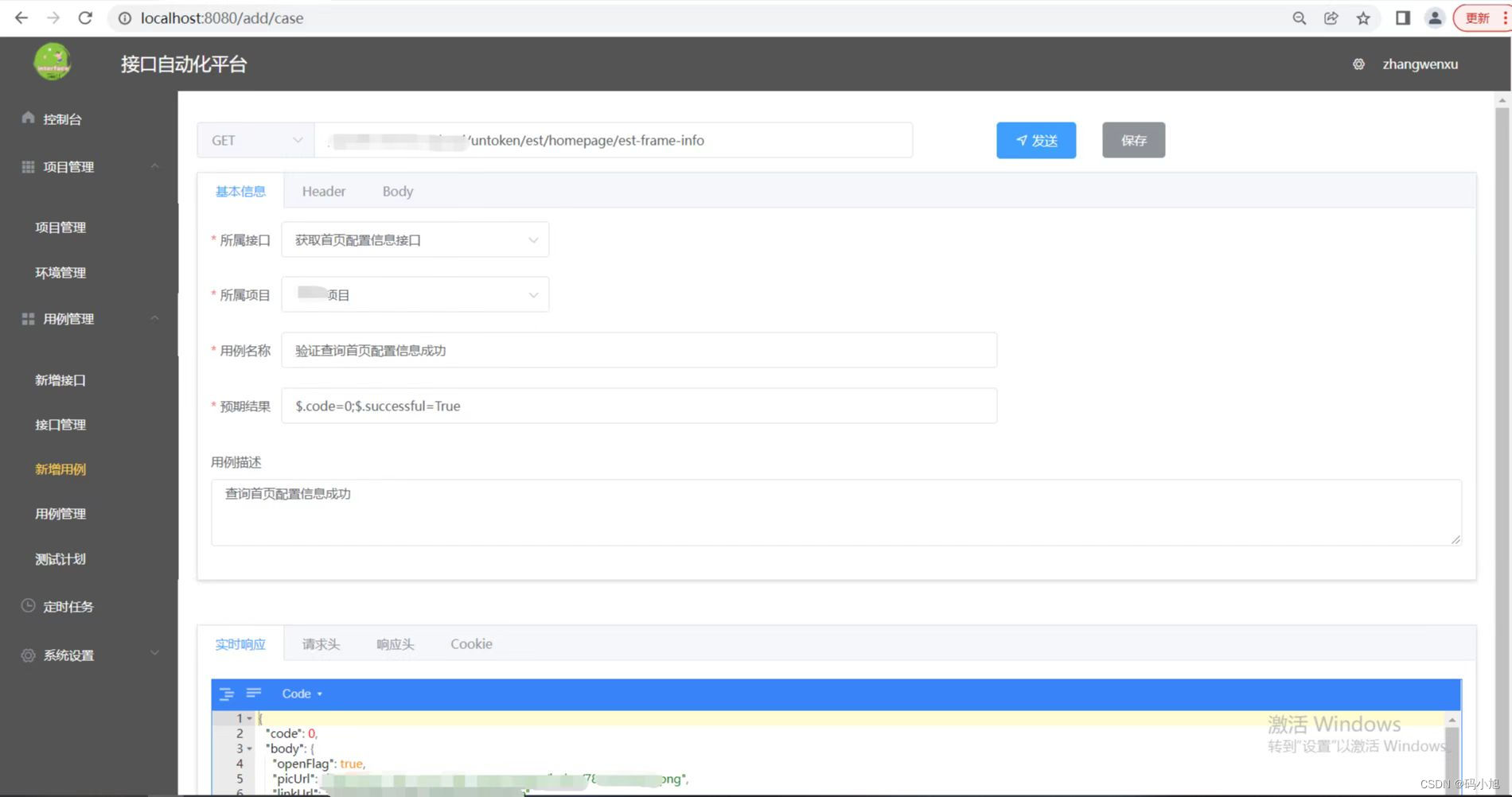
如何在项目中搭建python接口自动化框架?
文章目录前言一、框架目录介绍1、common模块读取Excel代码读取yaml代码(支持场景关联)jsonpath断言封装代码requests二次封装(get、post)configparser读取配置文件递归遍历字典常用方法log日志封装2、conf模块3、data模块4、case模…...
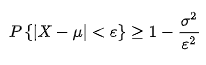
应用统计432考研复试复试提问总结精简版【一】
一、区间估计与假设检验的联系与区别 联系:二者利用样本进行推断,都属于推断统计区别: 原理: 前者是基于大概率,后者基于小概率;统计量:前者是构造枢轴量(不含未知参数,…...
Pytorch模型量化
在深度学习中,量化指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的bit来完成原本以浮点数完成的计算。这么做的好处主要有如下几点: 更少的模型体积,接近4倍的减少;可以更快的计算,由于…...

已解决Encountered error while trying to install package.> lxml
已解决(pip安装第三方模块lxml模块报错)Building wheels for collected packages: lxml Building wheel for lxml (setup.py) … error error: subprocess-exited-with-error python setup.py bdist_wheel did not run successfully. note: This error o…...

距离度量 —— 闵可夫斯基距离(Minkowski Distance)
Python学习系列文章:👉 目录 👈 文章目录一、概述二、计算公式1. 闵氏距离公式2. 闵氏距离的参数 p3. 闵氏距离的缺点一、概述 闵可夫斯基距离 (Minkowski Distance),也被称为 闵氏距离。它不仅仅是一种距离,而是将多…...
python(模块)xlwt
目录一、xlwt简介二、xlwt语法1、模块安装2、模块导入3、向xls文件中写入内容4、设置写入文件的格式4.1 字体设置(font)4.2 背景颜色设置(pattern)4.3 边框设置(borders)4.4 对齐方式设置(align…...

Pytorch中torch.unsqueeze()和torch.squeeze()函数解析
一. torch.squeeze()函数解析 1. 官网链接 torch.squeeze(),如下图所示: 2. torch.squeeze()函数解析 torch.squeeze(input, dimNone, outNone) squeeze()函数的功能是维度压缩。返回一个tensor(张量),其中 input…...
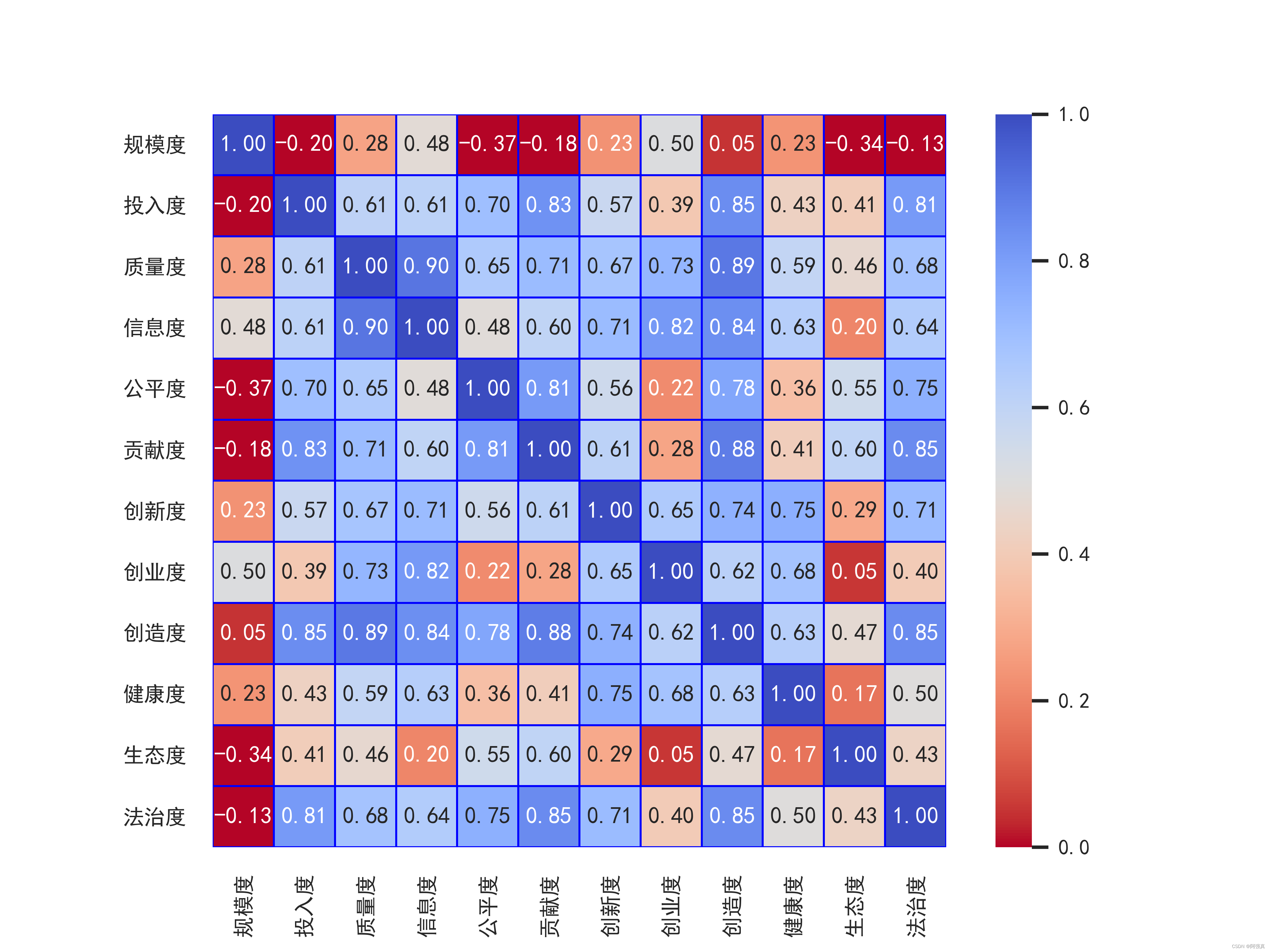
python绘制相关系数热力图
python绘制相关系数热力图一.数据说明和需要安装的库二.准备绘图三.设置配色,画出多幅图全部代码:本文讲述如何利用python绘制如上的相关系数热力图一.数据说明和需要安装的库 数据是31个省市有关教育的12个指标,如下所示。,在文…...
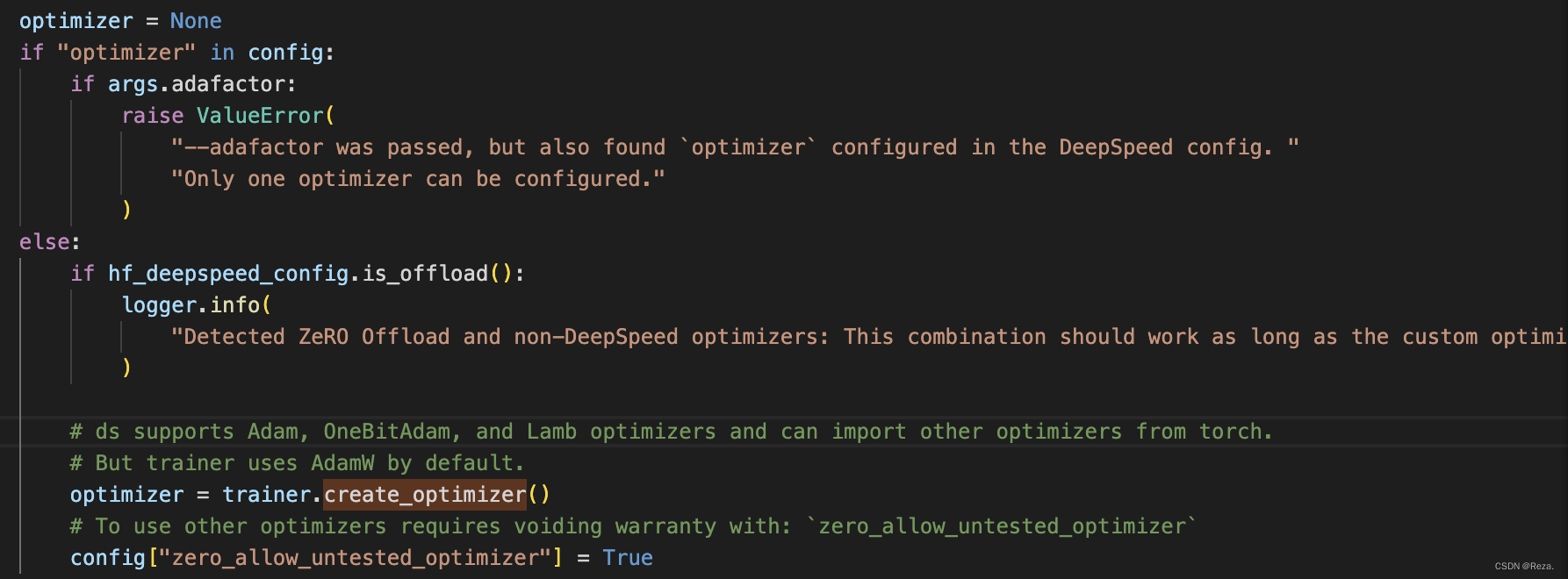
DeepSpeed使用指南(简略版)
现在的模型越来越大,动辄几B甚至几百B。但是显卡显存大小根本无法支撑训练推理。例如,一块RTX2090的10G显存,光把模型加载上去,就会OOM,更别提后面的训练优化。 作为传统pytorch Dataparallel的一种替代,D…...
【Python】tqdm 介绍与使用
文章目录一、tqdm 简介二、tqdm 使用1. 基于迭代对象运行: tqdm(iterator)2. tqdm(list)3. trange(i)4. 手动更新参考链接一、tqdm 简介 tqdm 是一个快速,可扩展的 Python 进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装…...
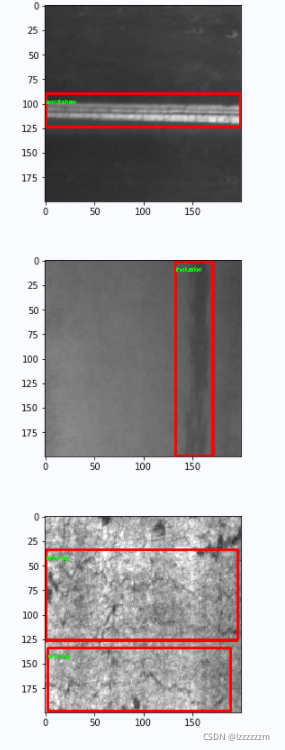
Pytorch机器学习(十)—— 目标检测中k-means聚类方法生成锚框anchor
Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 目录 Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 前言 一、K-means聚类 k-means代码 k-means算法 二、YOLO中使用k-means聚类生成anchor 读取VO…...
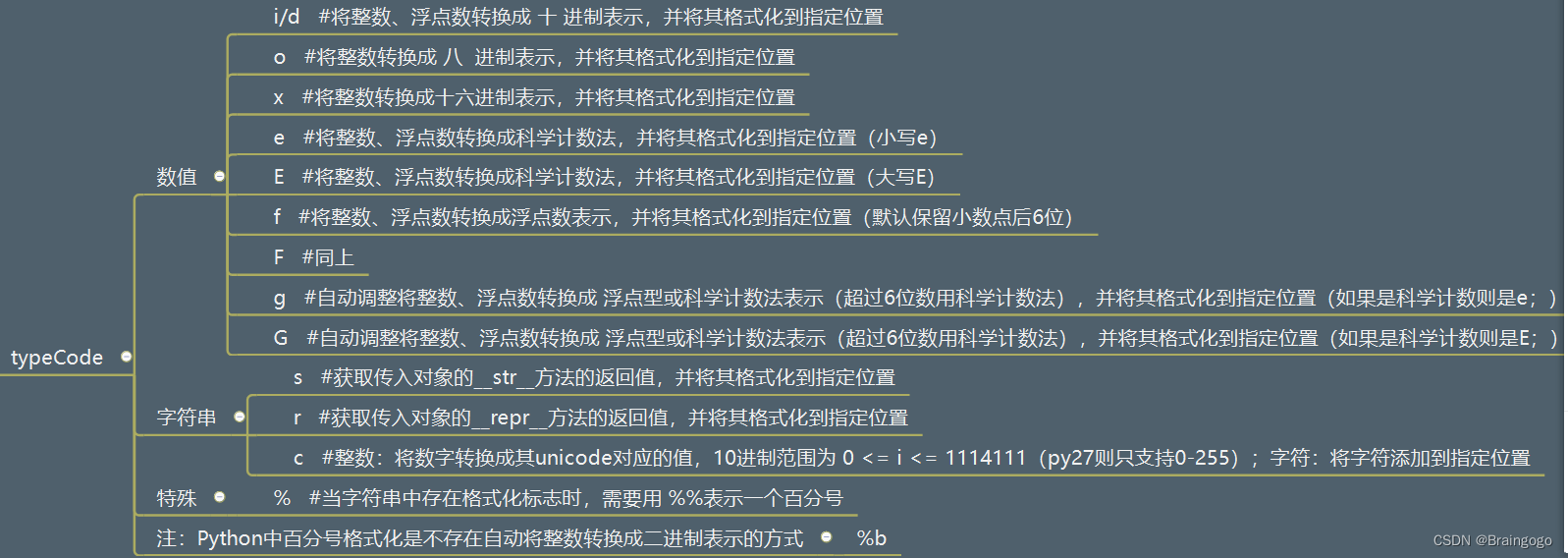
Python的占位格式符
对于print函数里的语句 print("我的名字是%s, 年龄是%d"%(name, age)) 中的%s和%d叫做占位符,它们的完整形态是 %[(name)][flags][width][.precision]typecode 其中带有[]的前缀都是可以省略的。 [(name)]: (name)表示, 根据, 制定的名称(…...
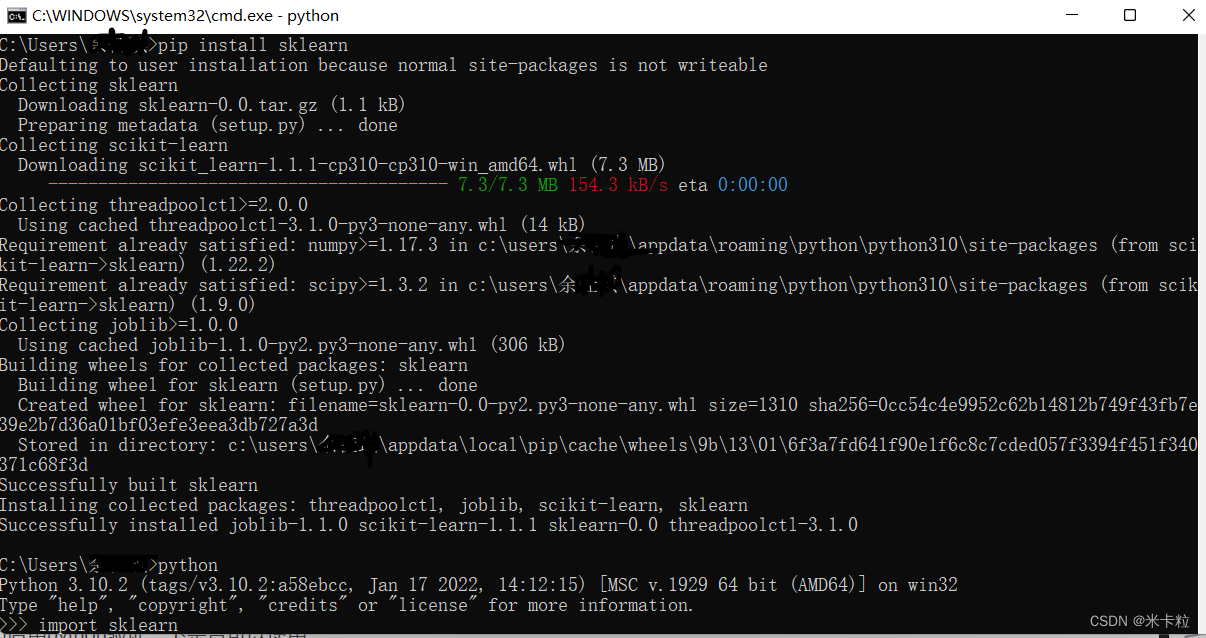
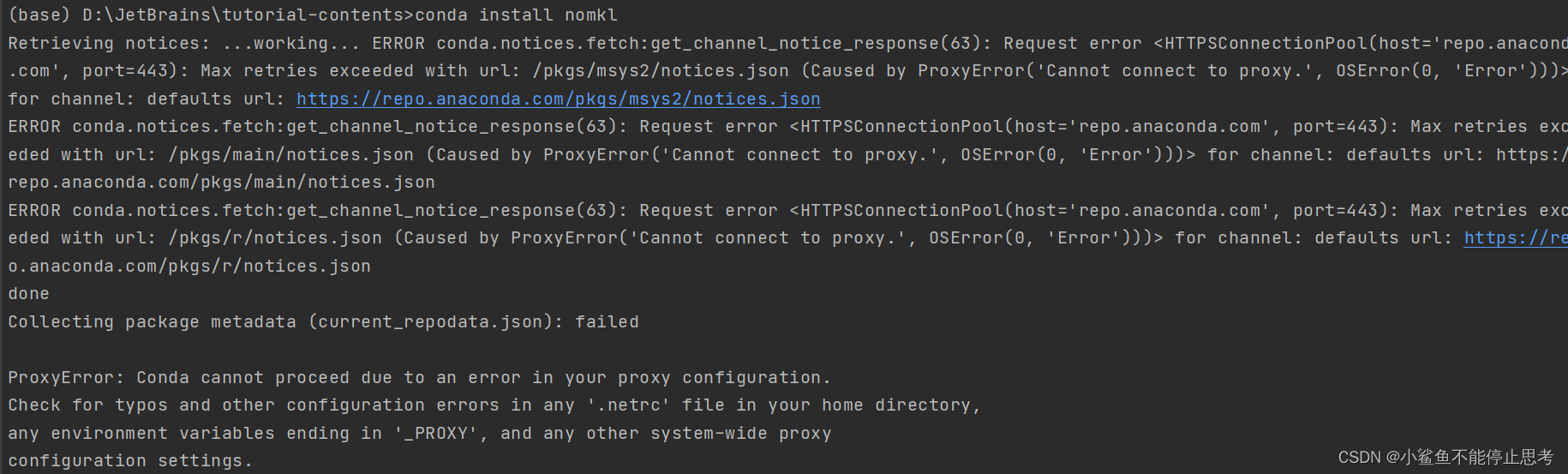
关于sklearn库的安装
对于安装sklearn真的是什么问题都被我遇到了 例如pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(hostfiles.pythonhosted.org, port443): Read timed out.遇到了 这种也遇到了Requirement already satisfied: numpy in c:\users\yjq\appdata\roamin…...
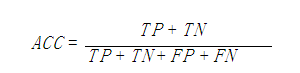
accuracy_score函数
1.acc计算原理 sklearn中accuracy_score函数计算了准确率。 在二分类或者多分类中,预测得到的label,跟真实label比较,计算准确率。 在multilabel(多标签问题)分类中,该函数会返回子集的准确率。如果对于一…...
怎么成为稚晖君?
如何成为IT大佬稚晖君——电子系统设计应具备的基本技能和方法论 快速提高电子技术的必经之路_一些老生常谈的道理 嵌入式AI入坑经历 稚晖君软件硬件开发环境总结 首先,机器学习深度学习这些和硬件是两个领域的内容,个人不建议一起学,注意力…...

Pandas库
Pandas是python第三方库,提供高性能易用数据类型和分析工具。Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用。pandas库引用: import pandas as pd 包括两个数据类型:Series(相当于一维数据类型)&…...

通过两道一年级数学题反思自己
背景 做完这两道题我开始反思自己,到底是什么限制了我?是我自己?是曾经教导我的老师?还是我的父母? 是考试吗?还是什么? 提目 1、正方体个数问题 2、相碰可能性 过程 静态思维: …...
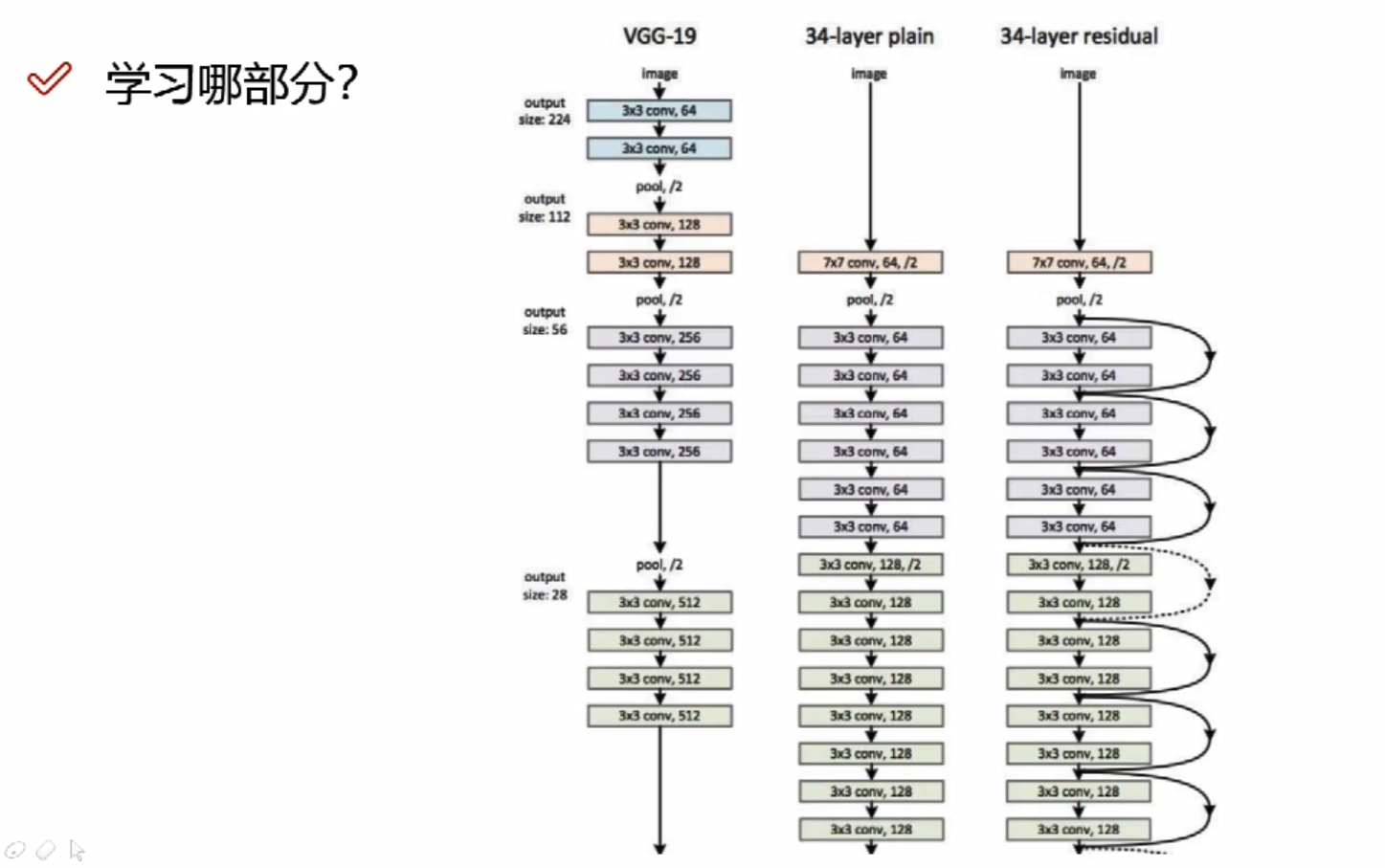
深度学习—卷积神经网络(CNN)全笔记,附代码
本文内容为哔站学习笔记【卷积神经网络-CNN】深度学习(唐宇迪带你学AI):卷积神经网络理论详解与项目实战,计算机视觉,图像识别模块实战_哔哩哔哩_bilibili 目录 深度学习基础 什么是深度学习? 机器学习流…...
Building wheel for mmcv-full (setup.py) ... error解决办法!
mmdetection 安装后,根据官方给的程序安装mmcv时,出现:Building wheel for mmcv-full (setup.py) … error 环境:CUDA11.3, Pytorch1.11 安装根据官网给的安装程序:pip install mmcv-full -f https://download.openmm…...
联邦学习开山之作代码解读与收获
参考:联邦学习代码解读,超详细_一只揪的博客-CSDN博客_联邦学习代码 参考文献:[1602.05629] Communication-Efficient Learning of Deep Networks from Decentralized Data (arxiv.org) 参考代码:GitHub - AshwinRJ/Federated-L…...
Python安装第三方库常用方法 超详细~
Python安装第三方库常用方法前言安装方法1. 通过pychram安装2. pip安装大法3. 下载whl文件到本地离线安装3.1 补充4.其他方法4.1 Python官方的Pypi菜单4.2 国内镜像源解决pip安装过慢的问题小结前言 在pyhton的学习中,相信大家通常都会碰到第三方库的安装问题&…...
Python--找出字符串中出现次数最多的字符及其出现的次数
方法一: 1、循环遍历列表或字符串,如果字符在字典中则值加1,如果不在则创建(key,value) 2、找到字典中,最大的value值 3、根据最大的value值,找对应的key值,打印出出现次数最多的字符 str &qu…...

滤波笔记一:卡尔曼滤波(Kalman Filtering)详解
本笔记是总结了B站DR_CAN的卡尔曼滤波器的课程,他的B站主页为:DR_CAN的个人空间_哔哩哔哩_bilibili PS:虽然我不是学自控的,但是老师真的讲的很好! 目录 Lesson1 递归算法 Lesson2 数学基础_数据融合_协方差矩阵_状态空间方程…...
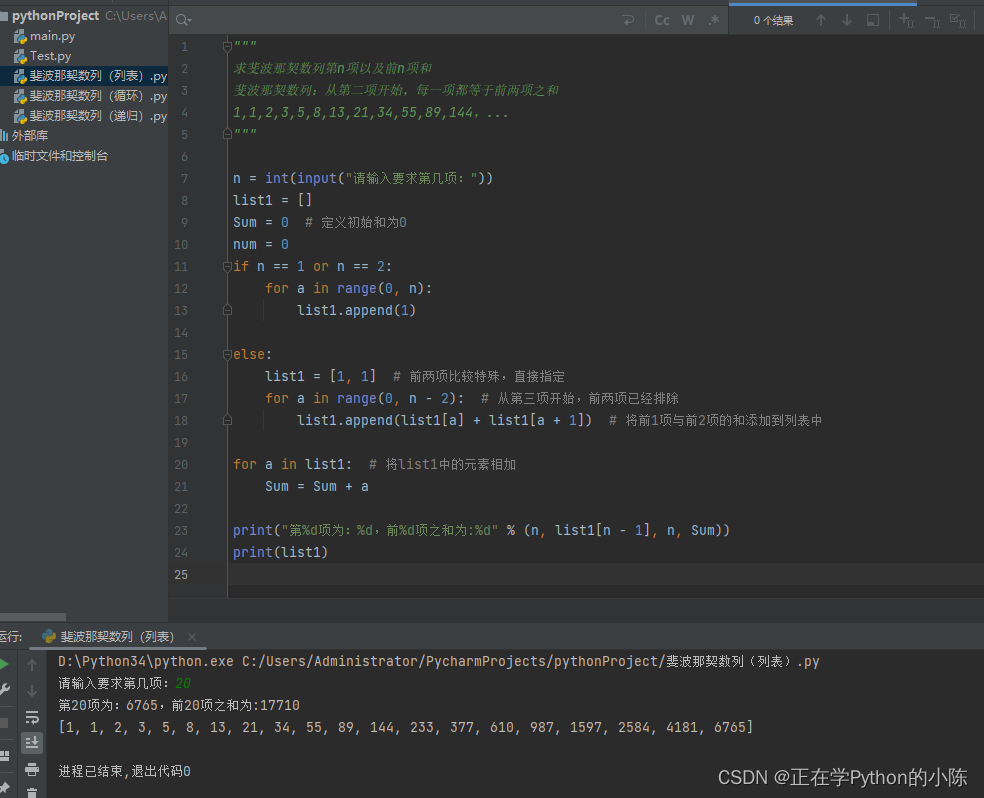
利用Python求斐波那契数列的第N项以及前N项和(循环、递归、集合)
著名的斐波那契数列,即从第三项开始,每一项都等于前两项之和。 之前写过利用Java语言来编写,由于最近正在学Python,所以将自己的想法记录在此,有需要的朋友可以参考一下。 写在前面:这里的三个方法其实思…...
一文速学(十八)-数据分析之Pandas处理文本数据(str/object)各类操作+代码一文详解(三)
目录 前言 一、子串提取 提取匹配首位子串 提取所有匹配项(extractall)...
Python数据分析-数据预处理
数据预处理 文章目录数据预处理1.前言2.数据探索2.1缺失值分析2.2 异常值分析2.2.1 简单统计量分析2.2.2 3$\sigma$原则2.2.3 箱线图分析2.3 一致性分析2.4 相关性分析3.数据预处理3.1 数据清洗3.1.1 缺失值处理3.1.2 异常值处理3.2 数据集成3.2.1 实体识别3.2.2 冗余属性识别3…...
【Python】AES加解密代码,文章还有加密串等你来解密,等你来挑战
🍦🍦写这篇AES文章也是有件趣事,有位小伙伴发了段密文,看看谁解密速度快,学过Python的小伙伴一下子就解开来了,内容也挺有趣的。 🍟🍟原来加解密也可以这么有趣,虽然看起…...
朴素贝叶斯模型及案例(Python)
目录 1 朴素贝叶斯的算法原理 2 一维特征变量下的贝叶斯模型 3 二维特征变量下的贝叶斯模型 4 n维特征变量下的贝叶斯模型 5 朴素贝叶斯模型的sklearn实现 6 案例:肿瘤预测模型 6.1 读取数据与划分 6.1.1 读取数据 6.1.2 划分特征变量和目标变量 6.2 模型…...
python之Tkinter详解
Python之Tkinter详解 文章目录Python之Tkinter详解1、Tkinter是什么2、Tkinter创建窗口①导入 tkinter的库 ,创建并显示窗口②修改窗口属性③创建按钮④窗口内的组件布局3、Tkinter布局用法①基本界面、label(标签)和button(按钮)用法②entry(输入)和text(文本)用法…...

【python】python进行debug操作
文章目录前言一、debug环境介绍二、debug按钮介绍2.1、step into:单步执行(遇到函数也是单步)2.2、step over:单步执行(遇到函数,全部运行)2.3、step into my code:(直接跳到下一个断点)2.4、st…...

Python安装tensorflow过程中出现“No matching distribution found for tensorflow”的解决办法
在Pycharm中使用pip install tensorflow安装tensorflow时报错: ERROR: Could not find a version that satisfies the requirement tensorflow(from versions: none) ERROR: No matching distribution found for tensorflow搜了好多帖子有的说可能是网络的问题&…...

pandas中的read_csv参数详解
1.官网语法 pandas.read_csv(filepath_or_buffer, sepNoDefault.no_default**,** delimiterNone**,** headerinfer’, namesNoDefault.no_default**,** index_colNone**,** usecolsNone**,** squeezeFalse**,** prefixNoDefault.no_default**,** mangle_dupe_colsTrue**,** dty…...
Python — — turtle 常用代码
目录 一、设置画布 二、画笔 1、画笔属性 2、绘图命令 (1) 画笔运动命令 (2) 画笔控制命令 (3) 全局控制命令 (4) 其他命令 3. 命令详解 三、文字显示为一个圆圈 四、画朵小花 一、设置画布 turtle为我们展开用于绘图区域,我们可以设置它的…...

【我是土堆 - PyTorch教程】学习随手记(已更新 | 已完结 | 10w字超详细版)
目录 1. Pytorch环境的配置及安装 如何管理项目环境? 如何看自己电脑cuda版本? 安装Pytorch 2. Python编辑器的选择、安装及配置 PyCharm PyCharm神器 Jupyter(可交互) 3. Python学习中的两大法宝函数 说明 实战操…...
“OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.”解决方法总结
一、问题描述 跑了点神经网络的代码,想画几个激活函数的图像,代码如下: 运行后报了以下错误: 翻译如下: OMP:错误 #15:正在初始化 libiomp5md.dll,但发现 libiomp5md.dll 已经初…...
python3.11.2安装 + pycharm安装
下载 :https://www.python.org/ 2.双击下载的软件: 3.进入安装界面 下一步,点击 是 上一步点击后就看到如下: 安装成功了,接下来检测一下:cmd 安装pycharm PyCharm是一种Python IDE(Integr…...