Python数据分析案例07——二手车估价(机器学习全流程,数据清洗、特征工程、模型选择、交叉验证、网格搜参、预测储存)
案例背景
本次案例来自2021年matchcop大数据竞赛A题数据集。要预测二手车的价格。训练集3万条数据,测试集5千条。官方给了二手车的很多特征,有的是已知的,有的是匿名的。要求就是做模型去预测测试集的二手车的价格。价格是一个连续变量,所以这是一个回归问题。(需要数据集可以留言)
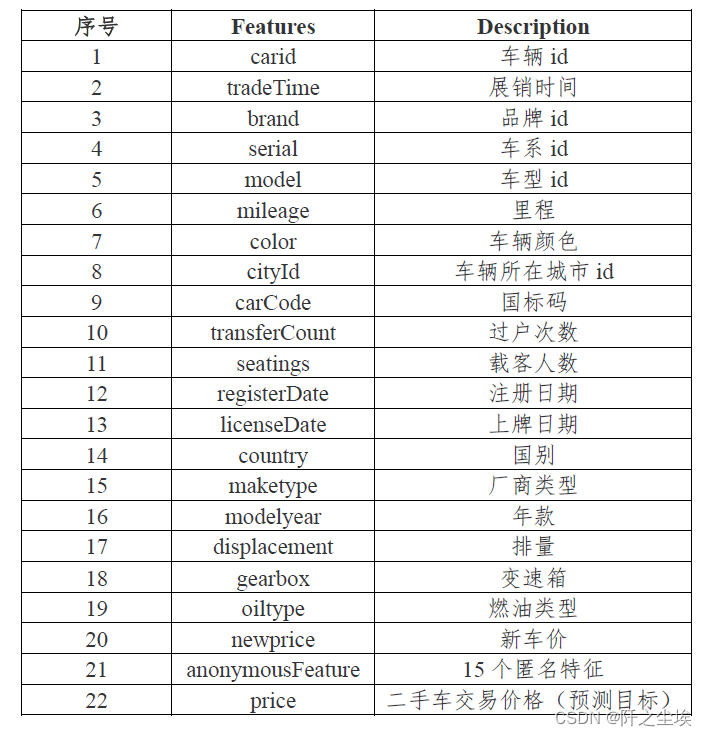
特征和数据集如下:
特征名称和含义
数据集:
说实话有点复杂,给的是txt文件,而且各种花样缺失数据.....要是新手估计读取数据这一步就直接劝退了。下面我们从读取数据开始,一点点完成这个案例。
读取数据
做数据科学项目,第一件事就是导包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #负号由于txt文件里面没有列名称,所以读取数据的时候要给个名称,名称按顺序用列表装好,用pandas读取的时候传入header。
我们用data来装训练集,data2来装测试集。
columns=['carid', 'tradeTime', 'brand', 'serial', 'model', 'mileage', 'color','cityid', 'carCode', 'transferCount','seatings',
'registerDate', 'licenseDate', 'country', 'maketype', 'modelyear', 'displacement','gearbox','oiltype', 'newprice',
'AF1', 'AF2', 'AF3', 'AF4', 'AF5','AF6', 'AF7', 'AF8', 'AF9', 'AF10', 'AF11','AF12', 'AF13', 'AF14','AF15', 'price']
data=pd.read_csv('附件1:估价训练数据.txt',sep='\t',header=None,names=columns)
data2=pd.read_csv('附件2:估价验证数据.txt',sep='\t',header=None,names=columns[:-1])
data.head()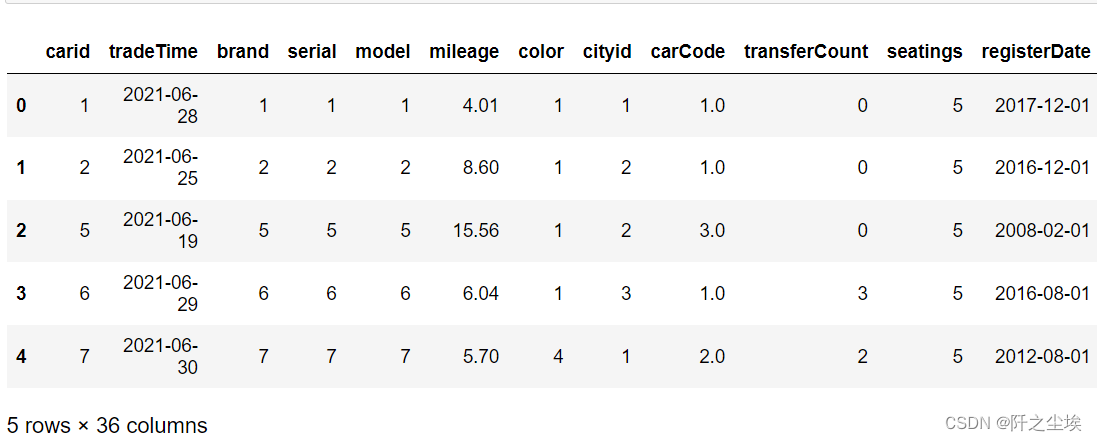
展示数据前五行,没什么问题
然后自动推断数据类型,再查看数据的信息
data.infer_objects()
data2.infer_objects()
data.info() ,data2.info()#查看数据基础信息
可以看到每个数据的类型,还有非空的个数。测试集也是一样,只是少了一列数据‘price’,这是响应变量,是我们要预测的,测试集当然没有。
数据清洗
首先要看数据的缺失量
#观察缺失值
import missingno as msno
msno.matrix(data)
这个图黑色的位置表示有数据,白色的表示缺失值。可以看到AF15,AF7,AF4等缺失值都较多,测试集也差不多
msno.matrix(data2) 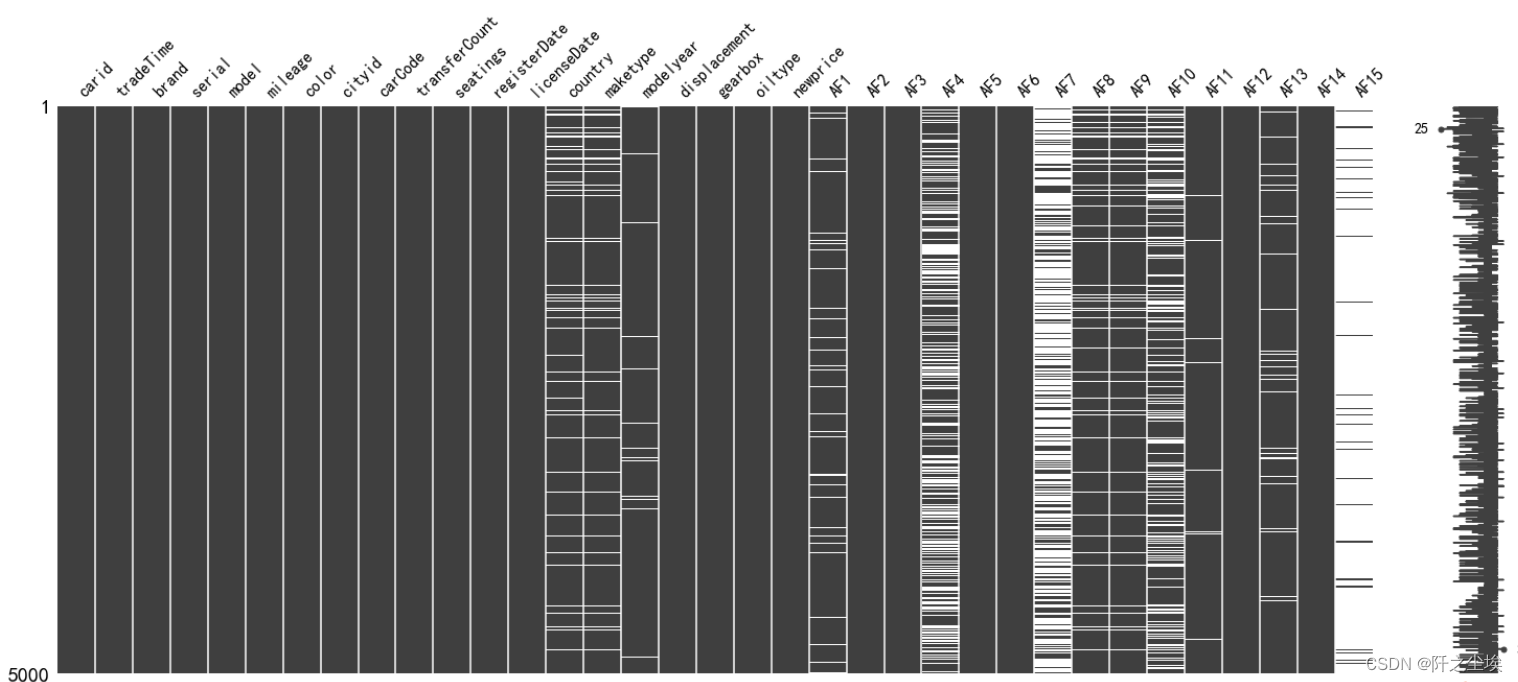
首先要处理第一列,ID列,这一列是每个车都有的独一无二的的标号,对预测没什么帮助。训练集就直接删了,测试集的id号要留一下,因为后面预测的时候要把ID号和你预测的车的价格要对应起来,才能提交。
#删除id序号
data.drop('carid',axis=1,inplace=True)
ID=data2['carid']然后再对其他行列进行处理,首先若是一行全为空值就删除
#若是有一行全为空值就删除
data.dropna(how='all',inplace=True)
data2.dropna(how='all',inplace=True)再对列进列进行处理。如果有一列的值全部一样,也就是取值唯一的特征变量就可以删除了,因为每个样本没啥区别,对模型就没啥用
#取值唯一的变量删除
for col in data.columns:
if len(data[col].value_counts())==1:
print(col)
data.drop(col,axis=1,inplace=True)缺失量达到一定程度就给他删了,缺失太多不如不要这个特征。我这里的比例是15%
#缺失到一定比例就删除
miss_ratio=0.15
for col in data.columns:
if data[col].isnull().sum()>data.shape[0]*miss_ratio:
print(col)
data.drop(col,axis=1,inplace=True)
可以看到上面这四个特征的缺失比例都高于15%,所以都删掉了。
然后需要对数据进一步细化处理,要把数据分为数值型和其他类型来看。
首先查看数值型数据
#查看数值型数据,
pd.set_option('display.max_columns', 30)
data.select_dtypes(exclude=['object']).head()
可以看到虽然都是数值型,但是有的是分类数据,有的还是是年份、日期,,所以看情况需要处理一下。
我这里就年份型数据modelyear留着了,然后删除AF13,它是个日期,也不知道含义,没啥用
#删除不要数值变量,不知道含义
data.drop('AF13',axis=1,inplace=True)做机器学习当然需要特征越分散越好,因为这样就可以在X上更加有区分度,从而更好的分类。所以那些数据分布很集中的变量可以扔掉。我们用异众比例来衡量数据的分散程度,也可以用方差,但是由于数据的口径大小不一致,方差不好对比我这里就没有用。
#计算异众比例
variation_ratio_s=0.1
for col in data.select_dtypes(exclude=['object']).columns:
df_count=data[col].value_counts()
kind=df_count.index[0]
variation_ratio=1-(df_count.iloc[0]/len(data[col]))
if variation_ratio<variation_ratio_s:
print(f'{col} 最多的取值为{kind},异众比例为{round(variation_ratio,4)},太小了,没区分度删掉')
data.drop(col,axis=1,inplace=True)
又删了3个特征。
然后对非数值型变量处理
#查看非数值型数据
data.select_dtypes(exclude=['int64','float64']).head()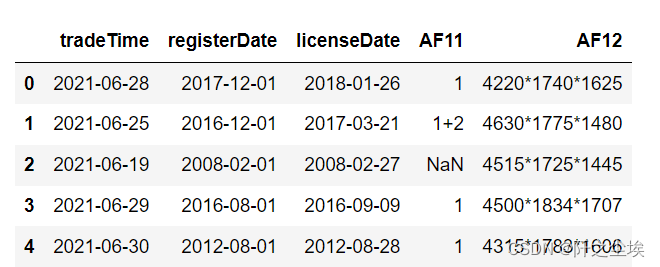
本次只有5个特征是非数值型数据,可以看到前三列是时间,AF11猜测是销售方式,AF12猜测是什么编号之类的。
和数值型数据一样,不要的就扔掉,需要的等下特征工程去处理。#有用的等下构建特征去做特征,该独热独热,没用的才删除。
这里删掉AF12,因为也不知道是啥,还有licenseDate,上牌时间没啥用。剩下两个时间可以算车子的年龄,等下特征工程有用,所以留着。AF11可以独热变为新特征,也留着。
#删除不要的字符变量
data.drop(['licenseDate','AF12'],axis=1,inplace=True)然后把选出来的特征总结看一下,并筛选给测试集。
#总结一下现在的变量,并给测试集也筛一下
columns=data.columns
print(columns)
data2=data2[columns[:-1]] #y值不要填充缺失值
缺失值有很多填充方式,可以用中位数,均值,众数。
也可以就采用那一行前面一个或者后面一个有效值去填充空的。
#均值填充,中位数填充,众数填充
#前填充,后填充
data.fillna(data.median(),inplace=True) #mode,mean
data.fillna(method='ffill',inplace=True) #pad,bfill/backfill
data2.fillna(data2.median(),inplace=True)
data2.fillna(method='ffill',inplace=True)特征工程
取出y,让data里面只装x
#首先对训练集取出y
y=data['price']
data.drop(['price'],axis=1,inplace=True) #对前面的说要处理的变量单独处理,
#时间类型变量的处理,得出二手车年龄,天数
#对前面的要处理的变量单独处理,
#时间类型变量的处理,得出二手车年龄,天数
data['age']=(pd.to_datetime(data['tradeTime'])-pd.to_datetime(data['registerDate'])).map(lambda x:x.days)
#测试集也一样变化
data2['age']=(pd.to_datetime(data2['tradeTime'])-pd.to_datetime(data2['registerDate'])).map(lambda x:x.days)构建了新特征后,原来的特征不要的就删除
#然后删除原来的不需要的特征变量
data.drop(['tradeTime','registerDate'],axis=1,inplace=True)
data2.drop(['tradeTime','registerDate'],axis=1,inplace=True)要独立热编码的取独热,生成虚拟变量。对AF11处理
#剩下的变量独热处理
data=pd.get_dummies(data)
data2=pd.get_dummies(data2)其实也可以映射,用map把分类的文本转化为数值(这里没运行,只是说明有这种做法)
#可以映射
# d1={'male':0,'female':1}
# data['Sex']=data['Sex'].map(d1)
# data2['Sex']=data2['Sex'].map(d1)
#还可以因子化
#codes,uniques=pd.factorize(data['Sex'])有时候训练集和测试集的特征变量独热出来数量可能不一样,要处理一下。
#独热多出来的特征处理
for col in data.columns:
if col not in data2.columns:
data2[col]=0查看一下现在的数据形状和信息
print(data.shape,data2.shape,y.shape) 
特征个数都是28,一样。
#查看处理完的数据信息
data.info(),data2.info()
可以看到没有空值,特征个数也一样了。但是特征工程还没结束。
我们还要画图查看每个X的分布
数据画图探索
训练集的箱线图
#查看特征变量的箱线图分布
columns = data.columns.tolist() # 列表头
dis_cols = 7 #一行几个
dis_rows = len(columns)
plt.figure(figsize=(4 * dis_cols, 4 * dis_rows))
for i in range(len(columns)):
plt.subplot(dis_rows,dis_cols,i+1)
sns.boxplot(data=data[columns[i]], orient="v",width=0.5)
plt.xlabel(columns[i],fontsize = 20)
plt.tight_layout()
#plt.savefig('特征变量箱线图',formate='png',dpi=500)
plt.show()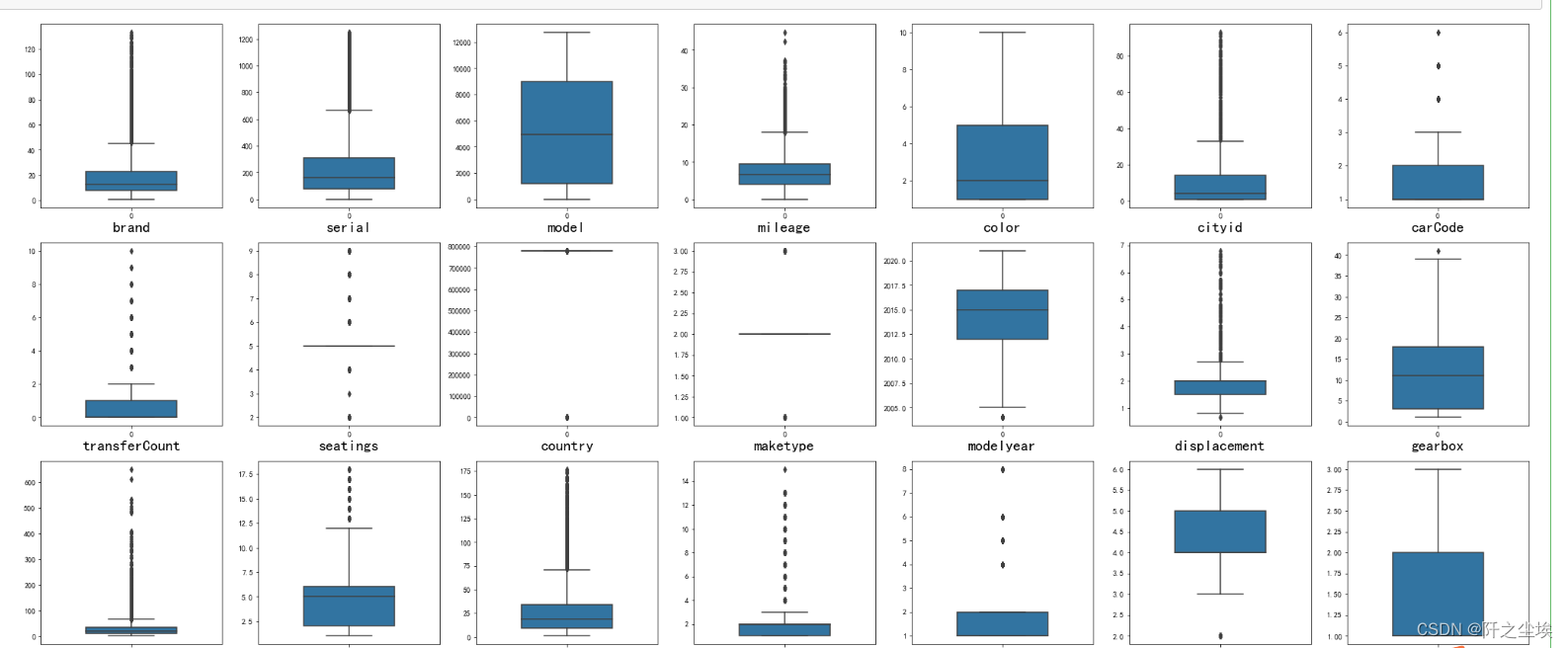
这里没图截完,可以看到有的变量异常值,极端值还是很多的。
画训练集和测试集的核密度图对比
#画密度图,训练集和测试集对比
dis_cols = 5 #一行几个
dis_rows = len(columns)
plt.figure(figsize=(4 * dis_cols, 4 * dis_rows))
for i in range(len(columns)):
ax = plt.subplot(dis_rows, dis_cols, i+1)
ax = sns.kdeplot(data[columns[i]], color="Red" ,shade=True)
ax = sns.kdeplot(data2[columns[i]], color="Blue",warn_singular=False,shade=True)
ax.set_xlabel(columns[i],fontsize = 20)
ax.set_ylabel("Frequency",fontsize = 18)
ax = ax.legend(["train", "test"])
plt.tight_layout()
#plt.savefig('训练测试特征变量核密度图',formate='png',dpi=500)
plt.show()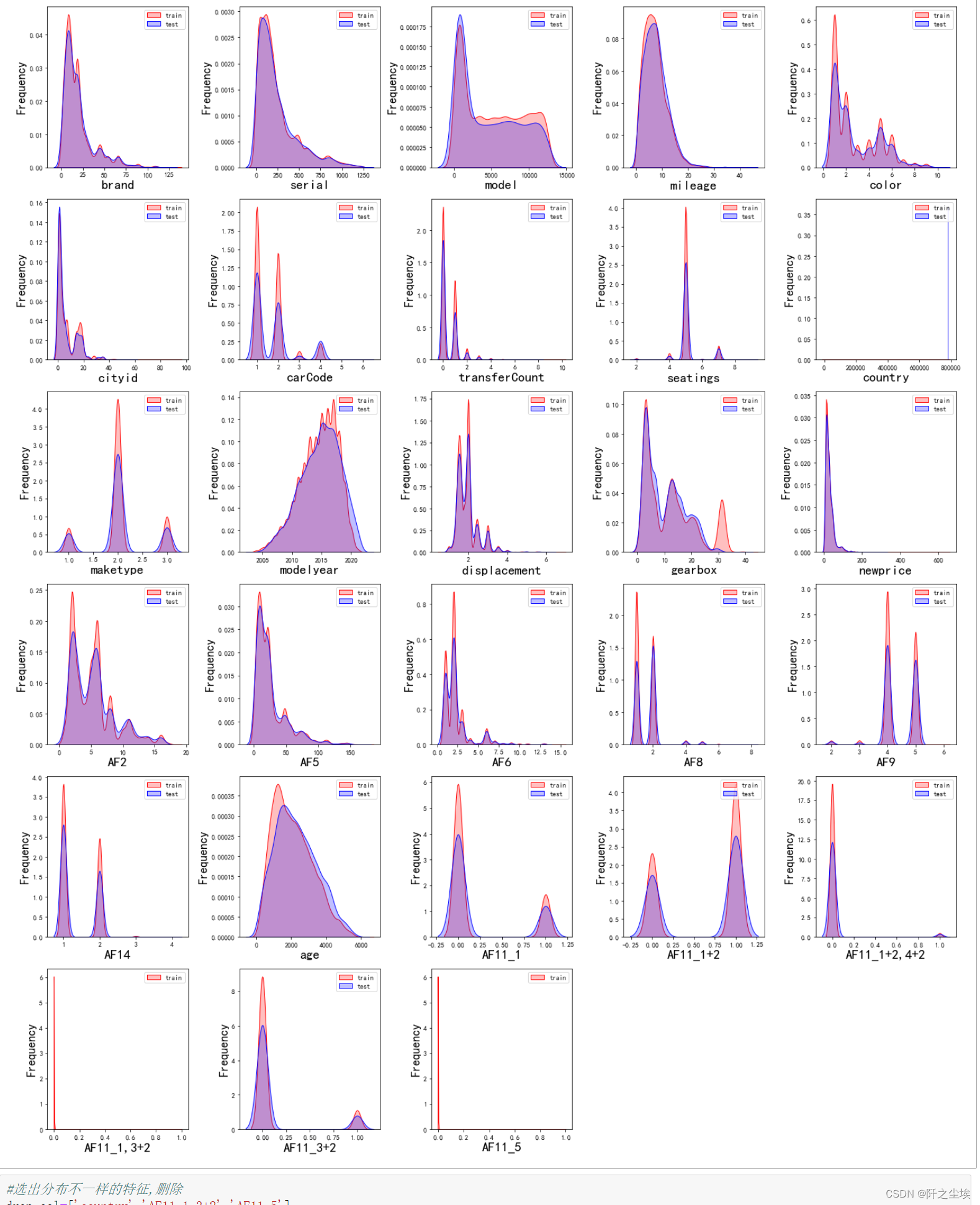
如果训练集和测试集的X数据分布是不一致的,差太远的话会影响模型的泛化能力,使用这样的变量要删除,这里'country','AF11_1,3+2','AF11_5'可以从图中看出分布不一致。要删除
#选出分布不一样的特征,删除
drop_col=['country','AF11_1,3+2','AF11_5']
data.drop(drop_col,axis=1,inplace=True)
data2.drop(drop_col,axis=1,inplace=True)然后还需要查看响应变量y的分布
# 查看y的分布
#回归问题
plt.figure(figsize=(6,2),dpi=128)
plt.subplot(1,3,1)
y.plot.box(title='响应变量箱线图')
plt.subplot(1,3,2)
y.plot.hist(title='响应变量直方图')
plt.subplot(1,3,3)
y.plot.kde(title='响应变量核密度图')
#sns.kdeplot(y, color='Red', shade=True)
#plt.savefig('响应变量.png')
plt.tight_layout()
plt.show()

可以看到有很严重的异常值,要筛掉
异常值处理
y异常值处理
我们将y大于200的样本都筛掉
#处理y的异常值
y=y[y <= 200]
plt.figure(figsize=(6,2),dpi=128)
plt.subplot(1,3,1)
y.plot.box(title='响应变量箱线图')
plt.subplot(1,3,2)
y.plot.hist(title='响应变量直方图')
plt.subplot(1,3,3)
y.plot.kde(title='响应变量核密度图')
#sns.kdeplot(y, color='Red', shade=True)
#plt.savefig('响应变量.png')
plt.tight_layout()
plt.show()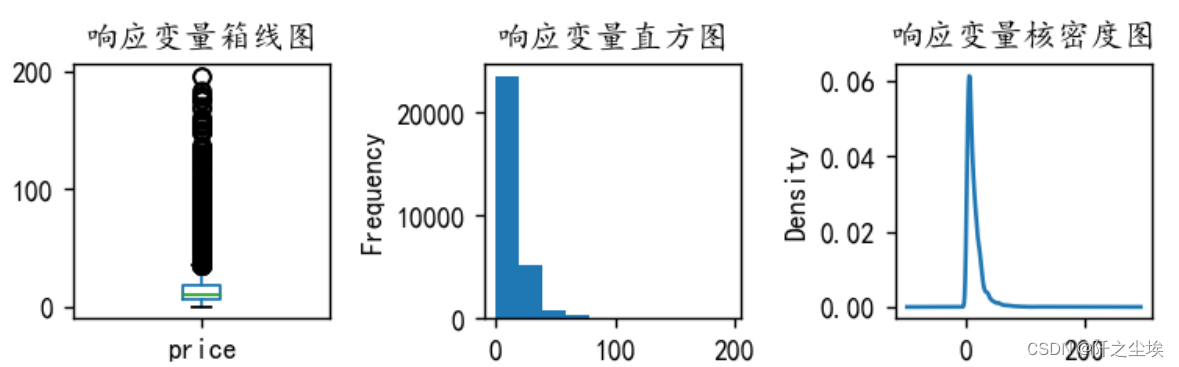
可以看到极端值情况好了一些
然后将筛出来的样本赋值给x
#筛选给x
data=data.iloc[y.index,:]
data.shape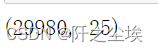
3万条数据变成了29980条
X异常值处理
#X异常值处理,先标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_s = scaler.fit_transform(data)
X2_s = scaler.fit_transform(data2)然后画图查看
plt.figure(figsize=(20,8))
plt.boxplot(x=X_s,labels=data.columns)
#plt.hlines([-10,10],0,len(columns))
plt.show()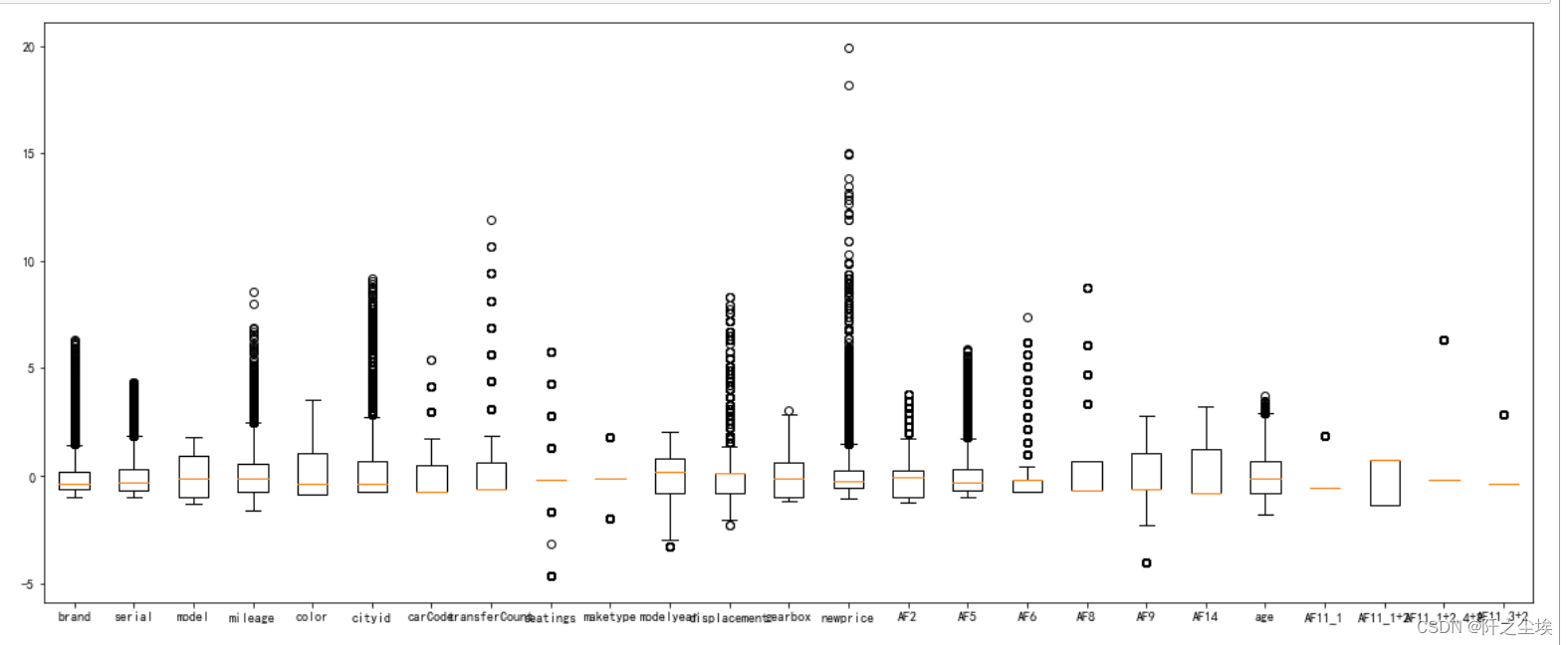
可以看到,newprice这个变量的异常点有点多,,, 后面要处理一下
测试集的箱线图,也差不多就不展示了
plt.figure(figsize=(20,8))
plt.boxplot(x=X2_s,labels=data2.columns)
#plt.hlines([-10,10],0,len(columns))
plt.show()然后这里自定义了一个函数,处理异常值的
#异常值多的列进行处理
def deal_outline(data,col,n): #数据,要处理的列名,几倍的方差
for c in col:
mean=data[c].mean()
std=data[c].std()
data=data[(data[c]>mean-n*std)&(data[c]<mean+n*std)]
#print(data.shape)
return data这个函数传入三个参数,要处理的数据框,异常值多的变量列名,还有筛掉几倍的方差。我下面选用的是10,也是就说如果一个样本数据大于整体10倍的标准差之外就筛掉。
然后将筛出来的样本赋值给y,查看形状
data=deal_outline(data,['newprice'],10)
y=y[data.index]
data.shape,y.shape
样本又变少了一点。
相关系数矩阵
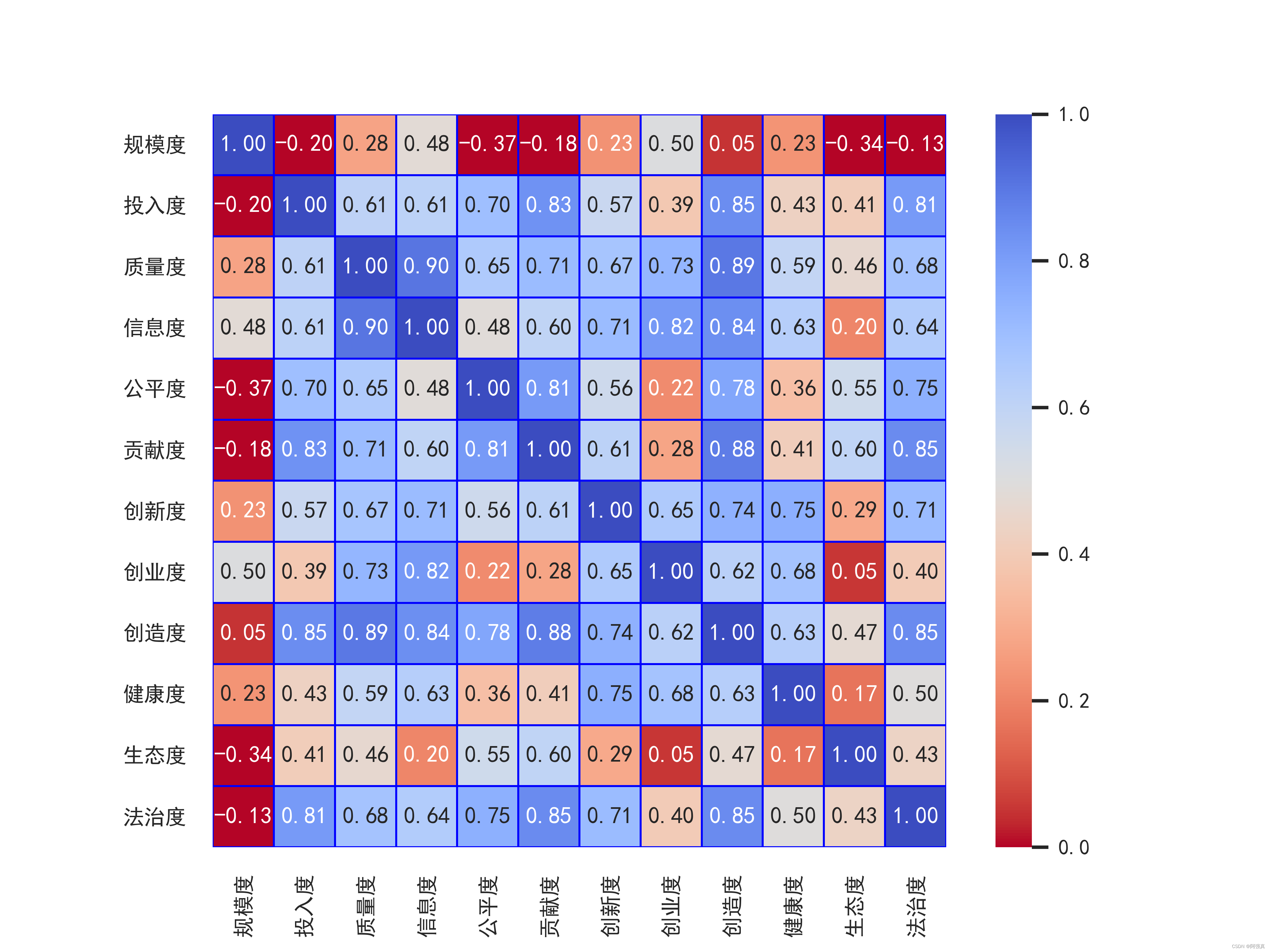
如果全是数值型变量就用皮尔逊相关系数。由于这里的X的分类变量有点多,我采用了斯皮尔曼相关系数计算,画出热力图。在训练集上带上了y
corr = plt.subplots(figsize = (18,16),dpi=128)
corr= sns.heatmap(data.assign(Y=y).corr(method='spearman'),annot=True,square=True)
从图中可以看出每个变量之间的相关性。最主要的看Y和谁的相关性高。我们这里的y,也就是二手车价格,和newprice,也就是新车的价格相关性最高。
测试集也差不多,不展示了
corr = plt.subplots(figsize = (18,16),dpi=128)
corr= sns.heatmap(data2.corr(method='spearman'),annot=True,square=True)特征工程差不多结束了
当然还可以进行降维等操作(PCA,RFE,LDA,正则化),但我这里特征目前才25个,不多,就不用降维 了
开始机器学习!
对前面的X也就是data,还有Y,也就是y,进行训练集和验证集的划分
#划分训练集和验证集
from sklearn.model_selection import train_test_split
X_train,X_val,y_train,y_val=train_test_split(data,y,test_size=0.2,random_state=0)然后将数据都标准化,再查看形状
#数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_s = scaler.transform(X_train)
X_val_s = scaler.transform(X_val)
X2_s=scaler.transform(data2)
print('训练数据形状:')
print(X_train_s.shape,y_train.shape)
print('验证测试数据形状:')
(X_val_s.shape,y_val.shape,X2_s.shape)
模型选择
学过李航的书应该都了解常见的回归算法,我这里选择了十种算法模型,企业对比他们在验证集的精度,再来进一步选择模型。
#采用十种模型,对比验证集精度
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import ElasticNet
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from xgboost.sklearn import XGBRegressor
from lightgbm import LGBMRegressor
from sklearn.svm import SVR
from sklearn.neural_network import MLPRegressor#线性回归
model1 = LinearRegression()
#弹性网回归
model2 = ElasticNet(alpha=0.05, l1_ratio=0.5)
#K近邻
model3 = KNeighborsRegressor(n_neighbors=10)
#决策树
model4 = DecisionTreeRegressor(random_state=77)
#随机森林
model5= RandomForestRegressor(n_estimators=500, max_features=int(X_train.shape[1]/3) , random_state=0)
#梯度提升
model6 = GradientBoostingRegressor(n_estimators=500,random_state=123)
#极端梯度提升
model7 = XGBRegressor(objective='reg:squarederror', n_estimators=1000, random_state=0)
#轻量梯度提升
model8 = LGBMRegressor(n_estimators=1000,objective='regression', # 默认是二分类
random_state=0)
#支持向量机
model9 = SVR(kernel="rbf")
#神经网络
model10 = MLPRegressor(hidden_layer_sizes=(16,8), random_state=77, max_iter=10000)
model_list=[model1,model2,model3,model4,model5,model6,model7,model8,model9,model10]
model_name=['线性回归','惩罚回归','K近邻','决策树','随机森林','梯度提升','极端梯度提升','轻量梯度提升','支持向量机','神经网络']拟合对比
for i in range(10):
model_C=model_list[i]
name=model_name[i]
model_C.fit(X_train_s, y_train)
s=model_C.score(X_val_s, y_val)
print(name+'方法在验证集的准确率为:'+str(s))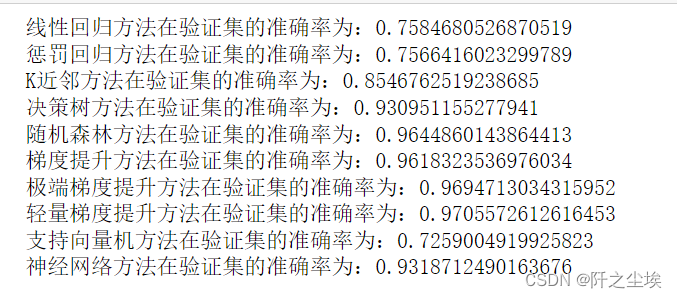
一般来说,对于这种表格数据,集成模型方法都是最好的,也就是XGB,LGBM,RF等。前人的经验也都是这样说的。使用后面交叉验证我们只选三个模型,随机森林,极端梯度提升,轻量梯度提升。
交叉验证
回归问题交叉验证,可以使用拟合优度,mae, rmse, mape 作为评价标准
交叉验证也可以直接使用sklearn库的cross_val_score,但是这个不能自定义评价准则,所以我这里手动循环去进行K折交叉验证。采用R2,mae,rmse,mape 四个指标作为评价标准。然后使用不同的随机数种子多次K折交叉验证,将每次K折交叉验证的结果均值和方差记录下来。再和每个模型都进行对比。
导入包和自定义函数
#回归问题交叉验证,使用拟合优度,mae,rmse,mape 作为评价标准
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error,r2_score
from sklearn.model_selection import KFold
def evaluation(y_test, y_predict):
mae = mean_absolute_error(y_test, y_predict)
mse = mean_squared_error(y_test, y_predict)
rmse = np.sqrt(mean_squared_error(y_test, y_predict))
mape=(abs(y_predict -y_test)/ y_test).mean()
r_2=r2_score(y_test, y_predict)
return mae, rmse, mape
def evaluation2(lis):
array=np.array(lis)
return array.mean() , array.std()自定义交叉验证函数
def cross_val(model=None,X=None,Y=None,K=5,repeated=1):
df_mean=pd.DataFrame(columns=['R2','MAE','RMSE','MAPE'])
df_std=pd.DataFrame(columns=['R2','MAE','RMSE','MAPE'])
for n in range(repeated):
print(f'正在进行第{n+1}次重复K折.....随机数种子为{n}\n')
kf = KFold(n_splits=K, shuffle=True, random_state=n)
R2=[]
MAE=[]
RMSE=[]
MAPE=[]
print(f" 开始本次在{K}折数据上的交叉验证.......\n")
i=1
for train_index, test_index in kf.split(X):
print(f' 正在进行第{i}折的计算')
X_train=X.values[train_index]
y_train=y.values[train_index]
X_test=X.values[test_index]
y_test=y.values[test_index]
model.fit(X_train,y_train)
score=model.score(X_test,y_test)
R2.append(score)
pred=model.predict(X_test)
mae, rmse, mape=evaluation(y_test, pred)
MAE.append(mae)
RMSE.append(rmse)
MAPE.append(mape)
print(f' 第{i}折的拟合优度为:{round(score,4)},MAE为{round(mae,4)},RMSE为{round(rmse,4)},MAPE为{round(mape,4)}')
i+=1
print(f' ———————————————完成本次的{K}折交叉验证———————————————————\n')
R2_mean,R2_std=evaluation2(R2)
MAE_mean,MAE_std=evaluation2(MAE)
RMSE_mean,RMSE_std=evaluation2(RMSE)
MAPE_mean,MAPE_std=evaluation2(MAPE)
print(f'第{n+1}次重复K折,本次{K}折交叉验证的总体拟合优度均值为{R2_mean},方差为{R2_std}')
print(f' 总体MAE均值为{MAE_mean},方差为{MAE_std}')
print(f' 总体RMSE均值为{RMSE_mean},方差为{RMSE_std}')
print(f' 总体MAPE均值为{MAPE_mean},方差为{MAPE_std}')
print("\n====================================================================================================================\n")
df1=pd.DataFrame(dict(zip(['R2','MAE','RMSE','MAPE'],[R2_mean,MAE_mean,RMSE_mean,MAPE_mean])),index=[n])
df_mean=pd.concat([df_mean,df1])
df2=pd.DataFrame(dict(zip(['R2','MAE','RMSE','MAPE'],[R2_std,MAE_std,RMSE_std,MAPE_std])),index=[n])
df_std=pd.concat([df_std,df2])
return df_mean,df_std对LGBM使用,进行5次k折交叉验证,每次3折。
model = LGBMRegressor(n_estimators=1000,objective='regression',random_state=0)
lgb_crosseval,lgb_crosseval2=cross_val(model=model,X=data,Y=y,K=3,repeated=5)
这里就不展示完了。总之会返回两个表,记录每次K折的四个平均指标。一个返回均值,一个返回标准差。
查看lgb的均值表
lgb_crosseval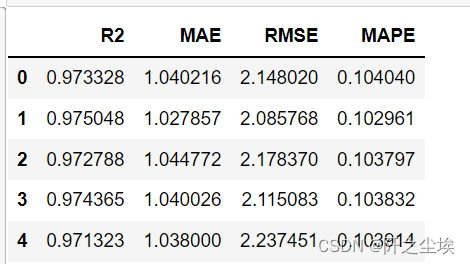
5次重复K折,每次的结果的均值都记录下来了。
然后我们对xgb和rf都进行重复的K折交叉验证。记录表
model = XGBRegressor(n_estimators=1000,objective='reg:squarederror',random_state=0)
xgb_crosseval,xgb_crosseval2=cross_val(model=model,X=data,Y=y,K=3,repeated=5)model = RandomForestRegressor(n_estimators=500, max_features=int(X_train.shape[1]/3) , random_state=0)
rf_crosseval,rf_crosseval2=cross_val(model=model,X=data,Y=y,K=3,repeated=5)然后我们就可以画图对比模型了,首先画四个评价指标的均值图
plt.subplots(1,4,figsize=(16,3))
for i,col in enumerate(lgb_crosseval.columns):
n=int(str('14')+str(i+1))
plt.subplot(n)
plt.plot(lgb_crosseval[col], 'k', label='LGB')
plt.plot(xgb_crosseval[col], 'b-.', label='XGB')
plt.plot(rf_crosseval[col], 'r-^', label='RF')
plt.title(f'不同模型的{col}对比')
plt.xlabel('重复交叉验证次数')
plt.ylabel(col,fontsize=16)
plt.legend()
plt.tight_layout()
plt.show()
黑色是LGB,很明显我们可以看到在拟合优度上LGB明显好于其他两个模型,其他三个误差指标上看,lgb都是最小的。四个指标都说明LGB最好。
再来画方差图
plt.subplots(1,4,figsize=(16,3))
for i,col in enumerate(lgb_crosseval2.columns):
n=int(str('14')+str(i+1))
plt.subplot(n)
plt.plot(lgb_crosseval2[col], 'k', label='LGB')
plt.plot(xgb_crosseval2[col], 'b-.', label='XGB')
plt.plot(rf_crosseval2[col], 'r-^', label='RF')
plt.title(f'不同模型的{col}方差对比')
plt.xlabel('重复交叉验证次数')
plt.ylabel(col,fontsize=16)
plt.legend()
plt.tight_layout()
plt.show()
方差代表稳定性,可以看到三个模型的方差都差不多,稳定性都差不多。
并且在运行的时候,LGBM的时间是小于XGB小于随机森林的。
所以综合他们的表现效果、稳定性、运行时间来看——LGBM优于XGB优于RF。
搜超参数
sklearn库的超参数搜索有两种,一种是网格化搜参,也是暴力搜索,遍历每一种可能性。一种是随机搜索,在超参数的解空间随机选。
网格化出来的一定是最优解,而随机搜索出来的可能是局部最优。但是为什么我们还是会用随机搜索,因为网格搜索花费时间太多了,超参数很多情况下,遍历每一种可能是不现实的,只能随机搜索,找个还可以的超参数用用。
LGBM的调参思路一般都是先对决策树的参数进行调整,然后再去调整学习率和估计器个数。
我们先采用随机搜索去寻找最优的决策树参数。
#利用K折交叉验证搜索最优超参数
from sklearn.model_selection import KFold, StratifiedKFold
from sklearn.model_selection import GridSearchCV,RandomizedSearchCV# Choose best hyperparameters by RandomizedSearchCV
#随机搜索决策树的参数
param_distributions = {'max_depth': range(4, 10), 'subsample':np.linspace(0.5,1,5 ),'num_leaves': [15, 31, 63, 127],
'colsample_bytree': [0.6, 0.7, 0.8, 1.0]}
# 'min_child_weight':np.linspace(0,0.1,2 ),
kfold = KFold(n_splits=3, shuffle=True, random_state=1)
model =RandomizedSearchCV(estimator= LGBMRegressor(objective='regression',random_state=0),
param_distributions=param_distributions, n_iter=200)
model.fit(X_train_s, y_train)这里的n_iter=200表示搜索200次,200次就花费了我三分多钟。。
查看最优参数
model.best_params_
最优参数赋值给模型,然后拟合评价
model = model.best_estimator_
model.score(X_val_s, y_val)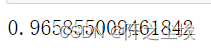
然后我们使用网格化搜索学习率和估计器个数
#网格化搜索学习率和估计器个数
param_grid={'learning_rate': np.linspace(0.05,0.3,6 ), 'n_estimators':[100,500,1000,1500, 2000]}
model =GridSearchCV(estimator= LGBMRegressor(objective='regression',random_state=0), param_grid=param_grid, cv=3)
model.fit(X_train_s, y_train)最优参数
model.best_params_
最优参数赋值给模型,然后拟合评价
model = model.best_estimator_
model.score(X_val_s, y_val)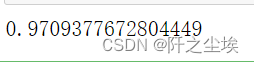
然后将寻找到的最优参数传入模型,再次进行拟合评价
#利用找出来的最优超参数在所有的训练集上训练,然后预测
model=LGBMRegressor(objective='regression',subsample=0.875,learning_rate= 0.05,n_estimators= 2500,num_leaves=127,
max_depth= 9,colsample_bytree=0.8,random_state=0)
model.fit(X_train_s, y_train)
model.score(X_val_s, y_val)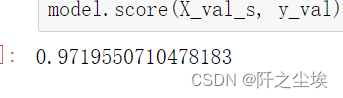
可以看到拟合优度上升了一点点。
当然有时间有算力可以继续搜索,还可以使用优化算法,启发式智能算法去搜索更好的超参数。
变量重要性排序图
用前面的最优模型在全部训练集数据上训练
model=LGBMRegressor(objective='regression',subsample=0.875,learning_rate= 0.05,n_estimators= 2500,num_leaves=127,
max_depth= 9,colsample_bytree=0.8,random_state=0)
model.fit(data.to_numpy(),y.to_numpy())
model.score(data.to_numpy(), y.to_numpy())![]()
自己训练测试自己,拟合优度当然高。。
画出变量重要性排序图
sorted_index = model.feature_importances_.argsort()
plt.barh(range(data.shape[1]), model.feature_importances_[sorted_index])
plt.yticks(np.arange(data.shape[1]), data.columns[sorted_index])
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.title('Gradient Boosting')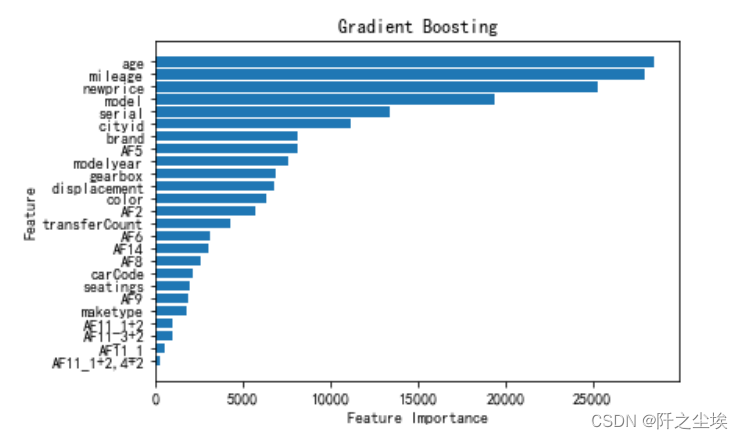
可以看到对二手车价格影响最大的变量是车龄age,车跑的里程数mileage,还有同款新车的价格newprice。
预测储存
对测试集进行预测,然后和车的编号id放一起存起来。就可以提交了
pred = model.predict(data2)
df=pd.DataFrame(ID)
df['price']=pred
df.to_csv('全部数据预测结果.csv',index=False)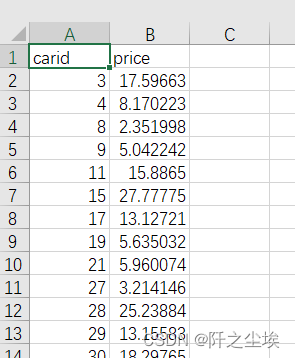 储存的效果。
储存的效果。
相关文章:
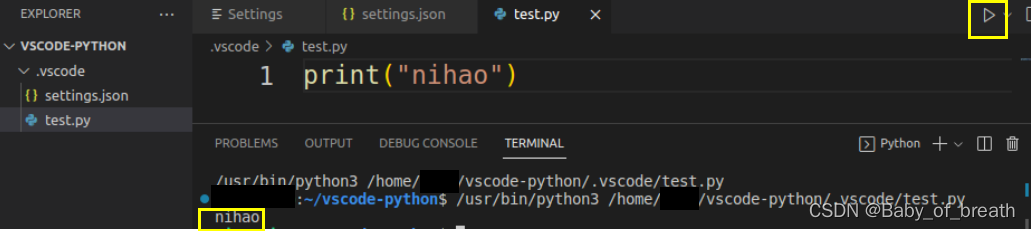
vscode运行python程序
系统:Ubuntu18.04 一、安装python插件 打开vscode,找到最右侧的Extensions,在上方搜索栏搜索python如大红框所圈,点击Install,安装即可。 二、创建python项目(.py存放的文件夹) 笔者习惯存放…...
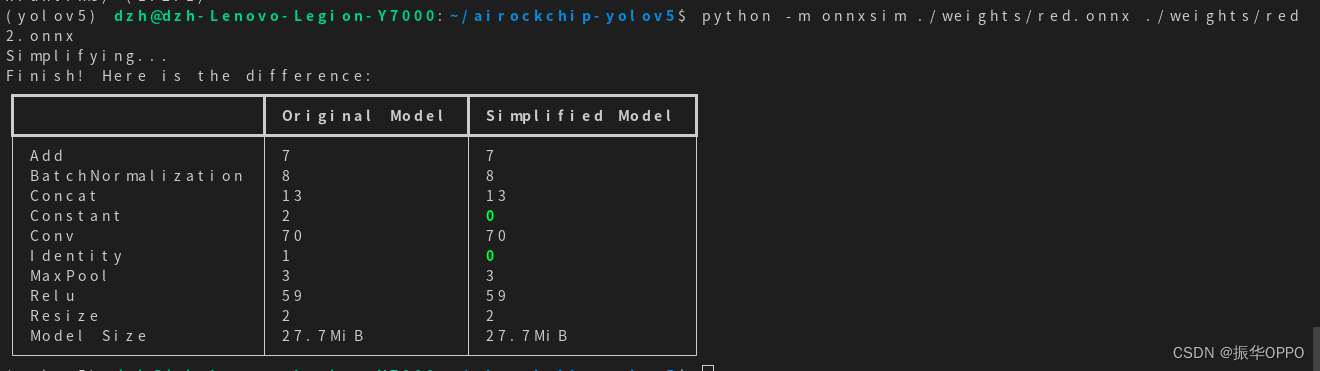
【yolov5】pytorch模型导出为onnx模型
博主想拿官网的yolov5训练好pt模型,然后转换成rknn模型,然后在瑞芯微开发板上调用模型检测。但是官网的版本对npu不友好,所以采用改进结构的版本: 将Focus层改成Conv层将Swish激活函数改成Relu激活函数 自带的预训练模型是预测80类…...
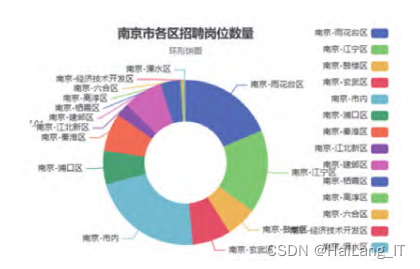
毕业设计-基于大数据招聘岗位可视化系统-python
目录 前言 课题背景和意义 实现技术思路 实现效果图样例 前言 📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科…...
No module named ‘cv2‘ 解决办法 (No module named ‘numpy‘ 等所有报错均可解决)
实在不行可以私信我解决! 1.关于离线pip install 库爆winErro[10061]的问题原因 使用了局域网,没有链接到网络 1.1 解决方法: 1.链接网络 2.假如离线安装 pip install imgaug.whl 库,但是imgaug依赖 shapely库。因此要安装imgaug库之前&…...
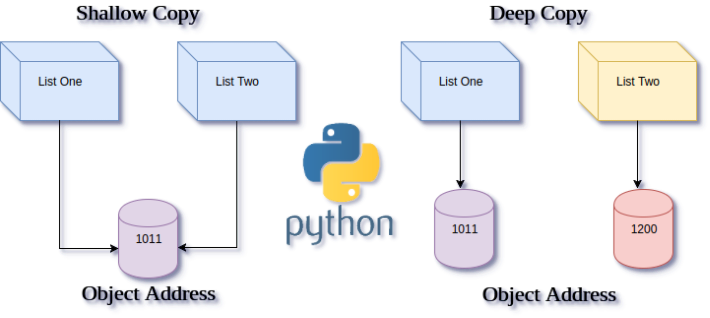
详细分析Python中深浅拷贝的区别
简而言之: 深浅拷贝的区别关键在于拷贝的对象类型是否可变。 我们可以总结出以下三条规则: 对于可变对象来说,深拷贝和浅拷贝都会开辟新地址,完成对象的拷贝而对于不可变对象来说,深浅拷贝都不会开辟新地址ÿ…...
django+drf_haystack+elasticsearch+ik+高亮显示
0.前提准备 环境 1. 准备好django2.2 2. 创建一个app 3.elasticsearch7.5启动 4.可视化工具(实在没有,也没啥) models.py from django.db import models# Create your models here.class Article(models.Model):title models.CharField(verbose_name文章标题, max_length22…...

头歌Python数据框、序列定义及数据处理应用实验闯关
粘贴答案不是目的 把Python学会这才叫做意义 童年的纸飞机 现在终于飞回我手里~~ 文章目录第1关:序列和数据框第2关:外部数据文件读取第3关:逻辑索引、切片方法,groupby 分组计算函数应用第4关:数据框关联操作第5关…...

使用pip下载时提示“You are using pip version 8.1.1, however version 22.1 is available.“
在使用pip install下载其他包时,报了错,如图: 提示:“You are using pip version 8.1.1, however version 22.1 is available. You should consider upgrading via the ‘pip install --upgrade pip’ command.” 根据提示&#…...

YOLOV8-gradcam 热力图可视化 即插即用 不需要对源码做任何修改!
YOLOV8 GradCam 热力图可视化. 本文给大家带来yolov8-gradcam热力图可视化,这个可视化是即插即用,不需要对源码做任何修改喔!给您剩下的不少麻烦! 代码链接:yolo-gradcam 里面还有yolov5和v7的热力图可视化代码&#…...
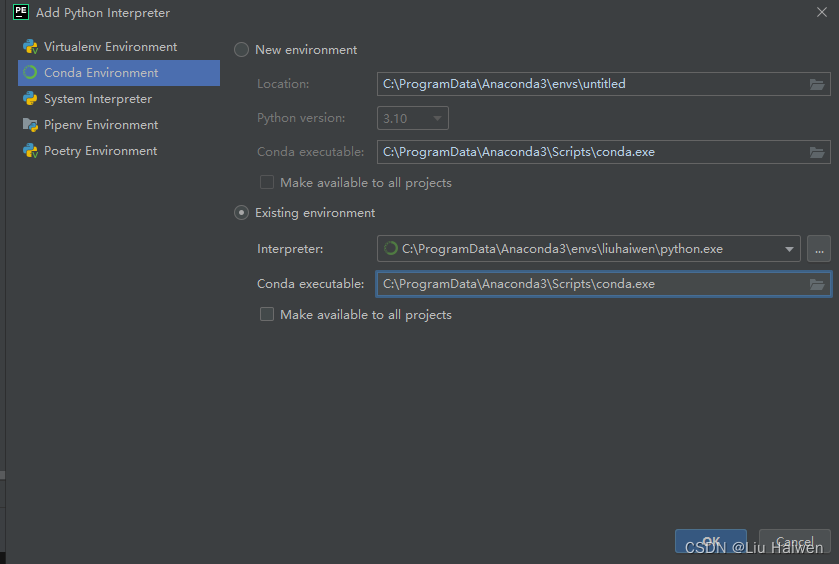
Anaconda创建虚拟环境并在Pycharm中使用创建好的环境
Anaconda创建虚拟环境并在Pycharm中使用创建好的环境1.Anaconda创建虚拟环境2.Pycharm中使用创建好的环境3.2022.12.8更新Anaconda的优势在于可以很方便地管理自己的工具包、开发环境和Python版本,同时还能使用不同的虚拟环境隔离不同要求的项目。假如你已经安装好了…...

python二级题库(百分之九十原题) 刷题软件推荐 第二套
目录 一、选择题 二、基本操作 三、简单应用 四、综合应用 刷题软件(模拟python二级考试): 公众h:露露IT 回复:python二级 一、选择题 1、下列叙述中正确的是()。 A.在栈中,栈…...

【模拟 简易银行系统~python】
目录~python面向对象编程之模拟银行系统相关程序代码如下:运行效果如下:pandas 每日一练:运行结果为:66、绘制sku_cost_prc的密度曲线运行效果为:67、计算后一天与前一天sku_cost_prc的差值运行结果为:68、…...
【YOLOv7/YOLOv5系列改进NO.52】融入YOLOv8中的C2f模块
文章目录 前言一、解决问题二、基本原理三、YOLOv5添加方法四、YOLOv7添加方法五、总结前言 作为当前先进的深度学习目标检测算法YOLOv7,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点…...

PyTorch 单机多GPU 训练方法与原理整理
PyTorch 单机多GPU 训练方法与原理整理 这里整理一些PyTorch单机多核训练的方法和简单原理,目的是既能在写代码时知道怎么用,又能从原理上知道大致是怎么回事儿。 就目前来说,并行训练的方法可以根据的不同的并行对象分为——模型并行和数据…...
anaconda创建、删除虚拟环境指令
使用conda创建、删除虚拟环境指令{\color{Red}使用conda创建、删除虚拟环境指令}使用conda创建、删除虚拟环境指令 使用conda创建、删除虚拟环境指令{\color{Red}使用conda创建、删除虚拟环境指令}使用conda创建、删除虚拟环境指令 一、创建虚拟环境 二、查看虚拟环境 三、激活…...
NCDC气象数据的提取与处理(二):python批量转换isd-lite数据为xlsx
目录 1.完整代码(部分代码参考https://zhuanlan.zhihu.com/p/556150264) 2.工作过程 2.1输入 2.2过程 3.实际效果 本例使用的相关数据及代码可见 链接:https://pan.baidu.com/s/1EYE0U7RrHSGGk3vptZyNVg 提取码:6666 书接上…...
MD5密码实验——Python实现(完整解析版)
文章目录更新:前言实验环境实验内容实验操作步骤1.初始化四个缓冲区2.设置常数表、位移位数等参数3.增加填充4.分组处理5.输出处理实验结果实验心得实验代码MD5-Python.py更新: 感谢评论区的大佬指出错误,现已改进代码 之前的错误在于没有考…...
如何在vscode中下载python第三方库(jieba和wordcloud为例)
本文由来 本来我并不想写文章的,但是我发现,对于一个0基础的小白vscode用户而言,想完整的下载一个第三方库还是存在一定的问题,并且我在搜索文章的时候发现,完全没有小白教程,太难了,所以说我就…...
python安装使用pip安装numpy
相信大家最近都在忙,因为到开学和上班的时候了,我最近也很忙,忙的快要流泪,这不是要考计算机三级了吗!买了好厚一本书,备战过程中,最近洗头一次掉了100根不止的头发,有点恐惧&#x…...
yolov5ds-断点训练、继续训练、先终止训练并调整最终epoch(yolov5同样适用)
目录参考链接1. 训练过程中中断了,继续训练如果觉得数值差不多稳定了,但是距离最终设置的epoch还很远,所以想要停止训练但是又得到yolov5在运行完指定最大epoch后生成的一系列map、混淆矩阵等图2. 训练完原有epoch,但还继续训练&a…...

openCV第一篇
文章目录 前言:计算机眼中的图片 1. 图片的读取与显示 1.1 图片的读取 1.2 显示的图片 1.2.1 显示原始图片 1.2.2 灰度图 1.3 BGR转换成灰度图、RGB 2. 保存图片 3. 视频的读取与显示 4. 截取图像部分 5. 颜色通道提取 6. 边界填充 7. 数值计算 8.…...

基于Python构建机器学习Web应用
目录 一、内容介绍 1.Onnx模型 ①skl2onnx库安装 2.Netron安装 二、模型构建 1.数据加载 2.划分可训练特征与预测标签 3.训练模型 ①第三方库导入 ②数据集划分 ③SVC模型构建 ④精度评价 二、模型转换及可视化 1.参数配置 2.Onnx模型生成 3.可视化模型 四、构…...
python - 密码加密与解密
Python之密码加密与解密 - 对称算法一、对称加密1.1 安装第三方库 - PyCrypto1.2 加密实现二、非对称加密三、摘要算法3.1 md5加密3.2 sha1加密3.3 sha256加密3.4 sha384加密3.5 sha512加密3.6 “加盐”加密由于计算机软件的非法复制,通信的泄密、数据安全受到威胁。…...
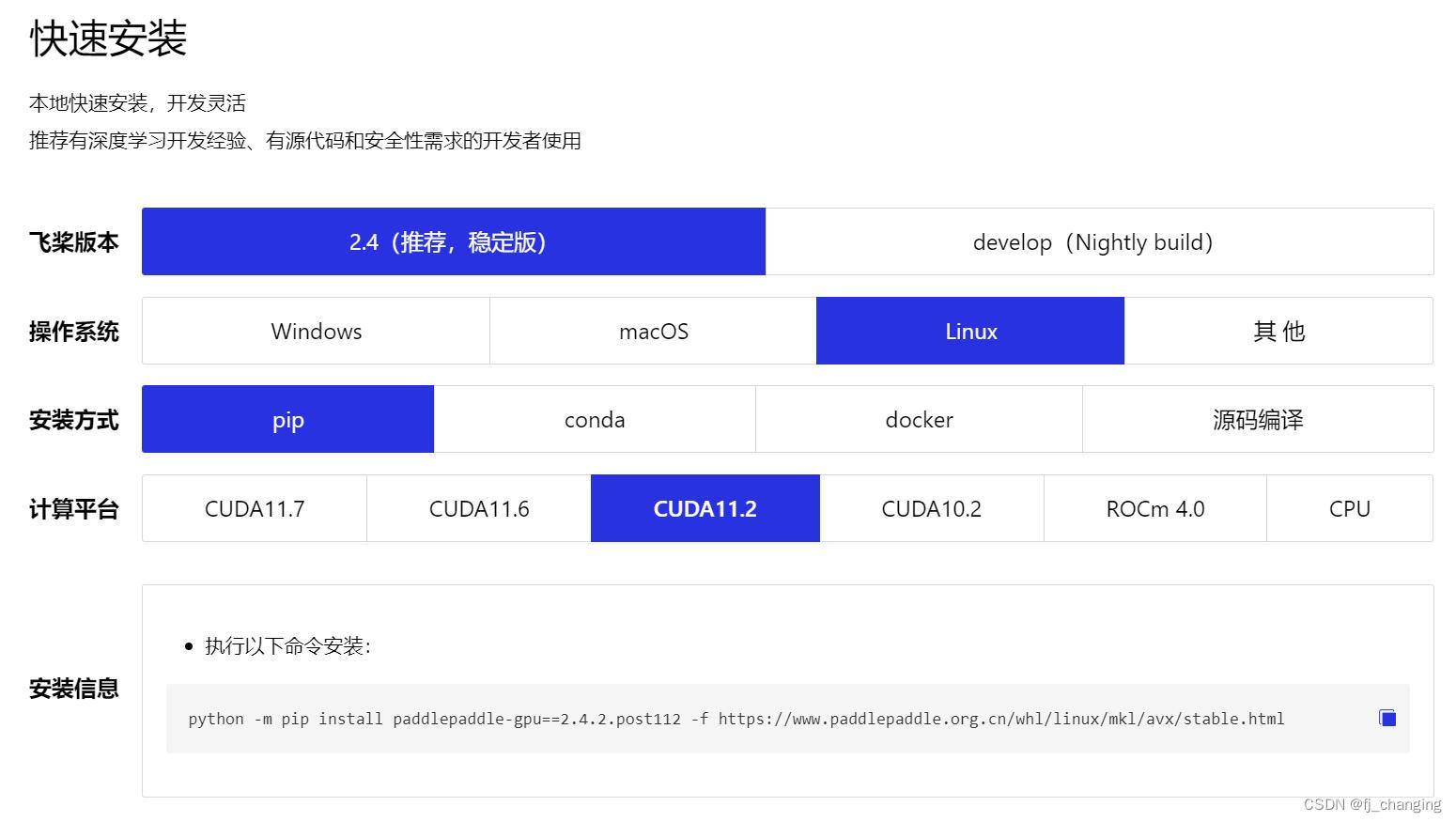
百度飞桨PaddleSpeech的简单使用
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型,一些典型的应用示例如下:语音识别、语音翻译 (英译中)、语音合成、标点恢复等。…...
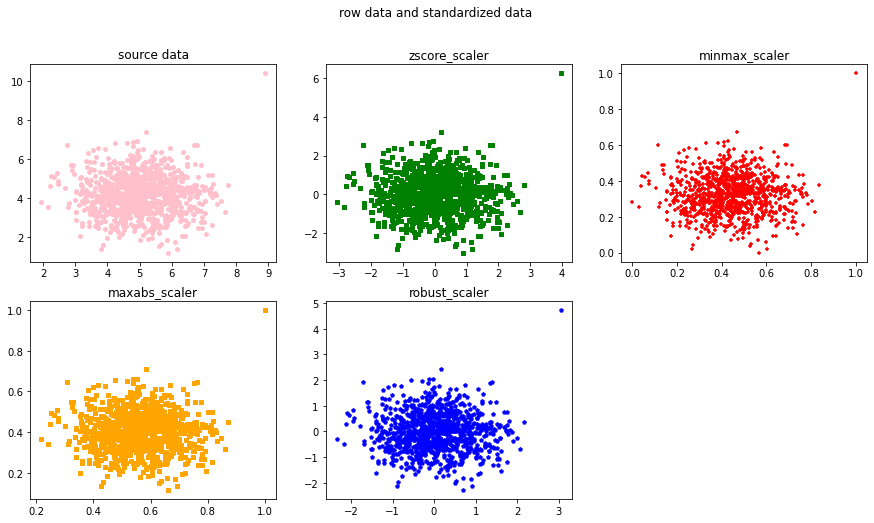
Python数据标准化
目录 一.数据标准化方式 1.实现中心化和正态分布的Z-Score 2.实现归一化的Max-Min 3.用于稀疏数据的MaxAbs 4.针对离群点的RobustScaler 二.Python针对以上几种标准化方法处理数据 三.总结 一.数据标准化方式 1.实现中心化和正态分布的Z-Score Z-Score标准化是基于原…...
Pycharm无法下载汉化包,一招教你搞定
Pycharm无法下载汉化包,一招教你搞定Pycharm直接导入汉化包Pycharm 无法采用自带的插件安装汉化包Pycharm直接导入汉化包 Pycharm 是可以直接导入汉化包的,这为很多初学者省区了不少麻烦。具体就是: 1:点击pycharm界面右上角的设…...

python成功实现“高配版”王者小游戏?【赠源码】
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 本游戏完整源码、素材: 点击此处跳转文末名片获取 咳咳,又是一款新的小游戏,就是大家熟悉的王者~ 来看我用python来实现高(di)配版的王者 是一款拿到代码运行后,…...
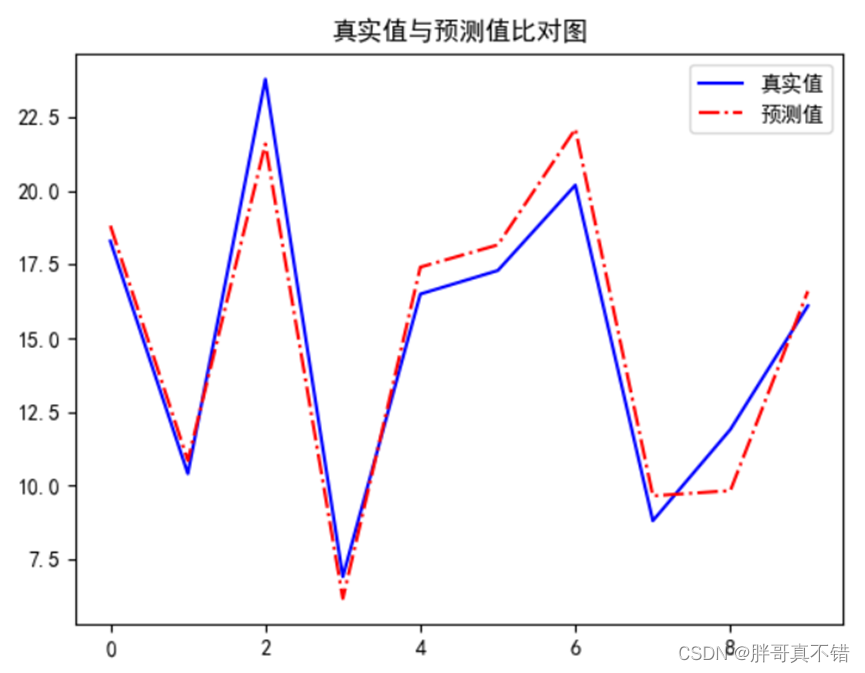
【项目实战】Python实现多元线性回归模型(statsmodels OLS算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 回归问题是一类预测连续值的问题,而能满足这样要求的数学模型称作回归模型,本项…...
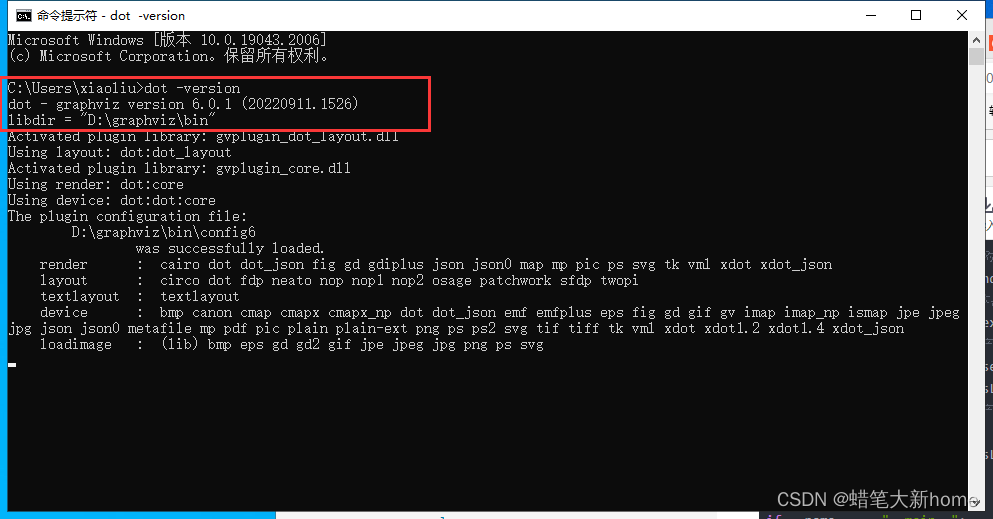
graphviz安装教程(2022最新版)初学者适用
1、首先在官网下载graphviz 下载网址:https://www.graphviz.org/download/ 2、安装。 打开第一步已经下载好的软件。点击下一步,在安装路径选择时可将安装路径修改为 D:\graphviz 接着一直点下一步,即可安装完成。 3、配置环境变量 右键…...

【Windows】搭建Pytorch环境(GPU版本,含CUDA、cuDNN),并在Pycharm上使用(零基础小白向)
文章目录前言一、安装CUDA1、检查电脑是否支持CUDA2、下载并安装CUDA3、下载并安装cuDNN二、安装Pytorch1、安装Anaconda2、切换清华镜像源3、创建环境并激活4、输入Pytorch安装命令5、测试三、在Pycharm上使用搭建好的环境参考文章前言 本人纯python小白,第一次使用…...
Tensorflow与CUDA、cudnn版本对应关系
不同版本的Tensorflow需对应不同的CUDA和cudnn版本,否者容易安装失败。可按下图所示,根据想要安装的Tensorflow版本,选择对应版本的CUDA和cudnn。 其中CUDA的下载链接为: CUDA Toolkit Archive | NVIDIA Developer cudnn下载链…...
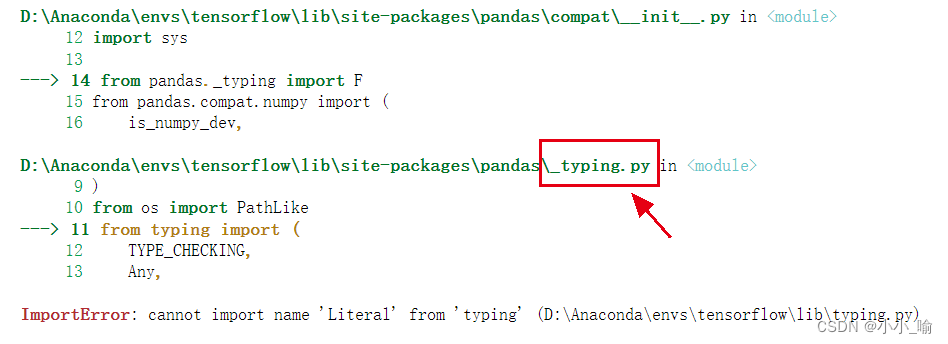
ImportError: cannot import name ‘Literal‘ from ‘typing‘ (D:\Anaconda\envs\tensorflow\lib\typing.py)
报错背景: 因为安装tensorflow-gpu版本需要,我把原来的新建的anaconda环境(我的名为tensorflow)中的python3.8降为了3.7。 在导入seaborn包时,出现了以下错误: ImportError: cannot import name Literal …...

100天精通Python(数据分析篇)——第67天:Pandas数据连接、合并、加入、添加、重构函数(merge、concat、join、append、stack、unstack)
文章目录 一、数据连接(pd.merge)1. left、right2. how3. on4. left_on、right_on5. sort6. suffixes7. left_index、right_index二、数据合并(pd.concat)1. index 没有重复的情况2. index 有重复的情况3. DataFrame合并时同时查看行索引和列索引有无重复三、数据加入(pd.…...
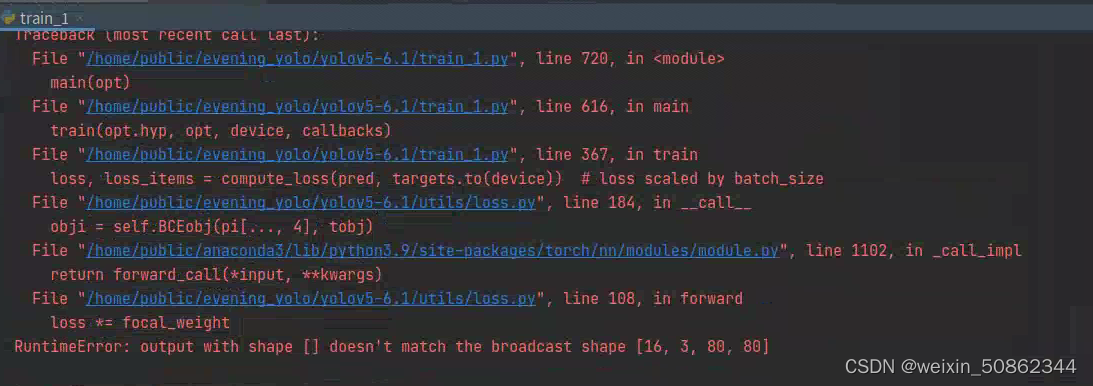
yolov5 优化系列(三):修改损失函数
1.使用 Focal loss 在util/loss.py中,computeloss类用于计算损失函数 # Focal lossg h[fl_gamma] # focal loss gammaif g > 0:BCEcls, BCEobj FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)其中这一段就是开启Focal loss的关键!!&…...
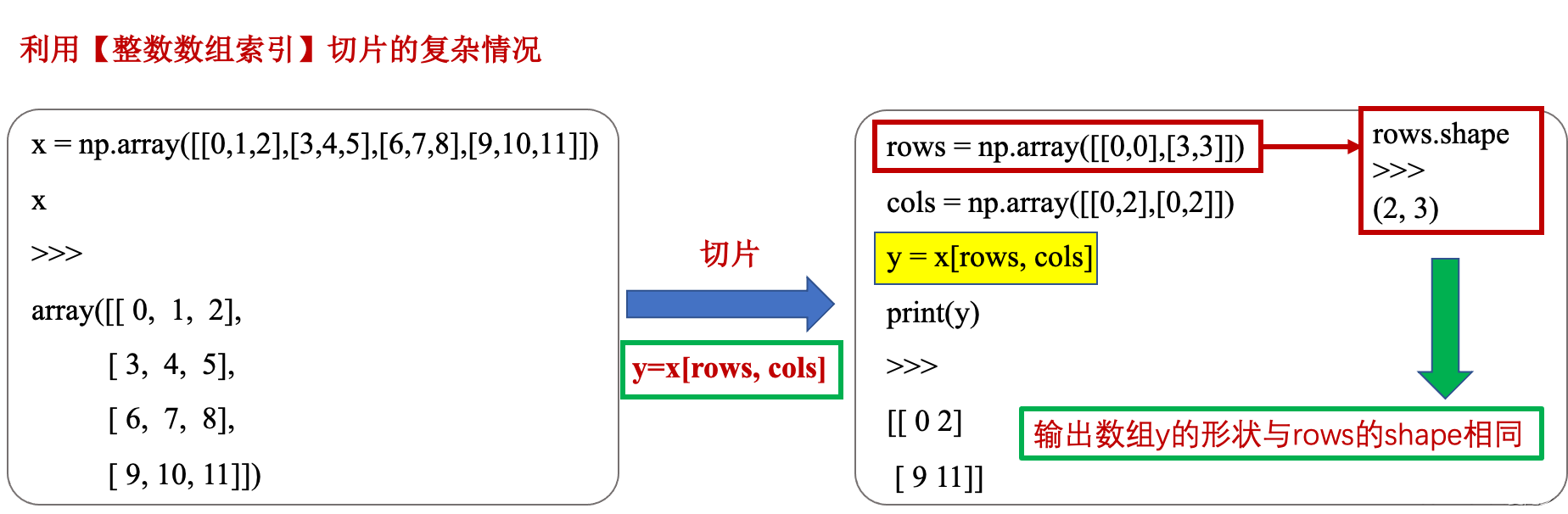
Python中数组切片的用法详解
Python中数组切片的用法详解一、python中“::-1”代表什么?二、python中“:”的用法三、python中数组切片三、numpy中的整数数组索引四、numpy中借助【切片 : 或 …与索引数组】组合进行复杂切片五、布尔索引六、花式索引一、python中“::-1”代表什么? …...
python 安装whl文件
前言 WHL文件是以Wheel格式保存的Python安装包,Wheel是Python发行版的标准内置包格式。在本质上是一个压缩包,WHL文件中包含了Python安装的py文件和元数据,以及经过编译的pyd文件,这样就使得它可以在不具备编译环境的条件下&#…...
Pycharm中安装pytorch
配置虚拟环境 为什么要安装虚拟环境?虚拟环境:把一部分内容独立出来,称之为容器。在容器中,安装我们自己想要的东西,比如不容版本的依赖包。各容器之间相互独立,互不影响。比如下载完 Anaconda 之后&#…...
Package | 解决 module ‘cv2‘ has no attribute ‘gapi_wip_gst_GStreamerPipeline‘
. 问题背景 由于这个问题出现了两回,决定记录一下。实验背景是使用opencv python库进行数据预处理,遇到报错信息如下: “ import cv2 File “/opt/conda/lib/python3.8/site-packages/cv2/init.py”, line 181, in bootstrap() File “/op…...
如何在项目中搭建python接口自动化框架?
文章目录前言一、框架目录介绍1、common模块读取Excel代码读取yaml代码(支持场景关联)jsonpath断言封装代码requests二次封装(get、post)configparser读取配置文件递归遍历字典常用方法log日志封装2、conf模块3、data模块4、case模…...
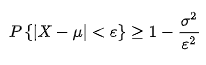
应用统计432考研复试复试提问总结精简版【一】
一、区间估计与假设检验的联系与区别 联系:二者利用样本进行推断,都属于推断统计区别: 原理: 前者是基于大概率,后者基于小概率;统计量:前者是构造枢轴量(不含未知参数,…...
Pytorch模型量化
在深度学习中,量化指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的bit来完成原本以浮点数完成的计算。这么做的好处主要有如下几点: 更少的模型体积,接近4倍的减少;可以更快的计算,由于…...

已解决Encountered error while trying to install package.> lxml
已解决(pip安装第三方模块lxml模块报错)Building wheels for collected packages: lxml Building wheel for lxml (setup.py) … error error: subprocess-exited-with-error python setup.py bdist_wheel did not run successfully. note: This error o…...

距离度量 —— 闵可夫斯基距离(Minkowski Distance)
Python学习系列文章:👉 目录 👈 文章目录一、概述二、计算公式1. 闵氏距离公式2. 闵氏距离的参数 p3. 闵氏距离的缺点一、概述 闵可夫斯基距离 (Minkowski Distance),也被称为 闵氏距离。它不仅仅是一种距离,而是将多…...
python(模块)xlwt
目录一、xlwt简介二、xlwt语法1、模块安装2、模块导入3、向xls文件中写入内容4、设置写入文件的格式4.1 字体设置(font)4.2 背景颜色设置(pattern)4.3 边框设置(borders)4.4 对齐方式设置(align…...

Pytorch中torch.unsqueeze()和torch.squeeze()函数解析
一. torch.squeeze()函数解析 1. 官网链接 torch.squeeze(),如下图所示: 2. torch.squeeze()函数解析 torch.squeeze(input, dimNone, outNone) squeeze()函数的功能是维度压缩。返回一个tensor(张量),其中 input…...
python绘制相关系数热力图
python绘制相关系数热力图一.数据说明和需要安装的库二.准备绘图三.设置配色,画出多幅图全部代码:本文讲述如何利用python绘制如上的相关系数热力图一.数据说明和需要安装的库 数据是31个省市有关教育的12个指标,如下所示。,在文…...
DeepSpeed使用指南(简略版)
现在的模型越来越大,动辄几B甚至几百B。但是显卡显存大小根本无法支撑训练推理。例如,一块RTX2090的10G显存,光把模型加载上去,就会OOM,更别提后面的训练优化。 作为传统pytorch Dataparallel的一种替代,D…...
【Python】tqdm 介绍与使用
文章目录一、tqdm 简介二、tqdm 使用1. 基于迭代对象运行: tqdm(iterator)2. tqdm(list)3. trange(i)4. 手动更新参考链接一、tqdm 简介 tqdm 是一个快速,可扩展的 Python 进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装…...
Pytorch机器学习(十)—— 目标检测中k-means聚类方法生成锚框anchor
Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 目录 Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 前言 一、K-means聚类 k-means代码 k-means算法 二、YOLO中使用k-means聚类生成anchor 读取VO…...
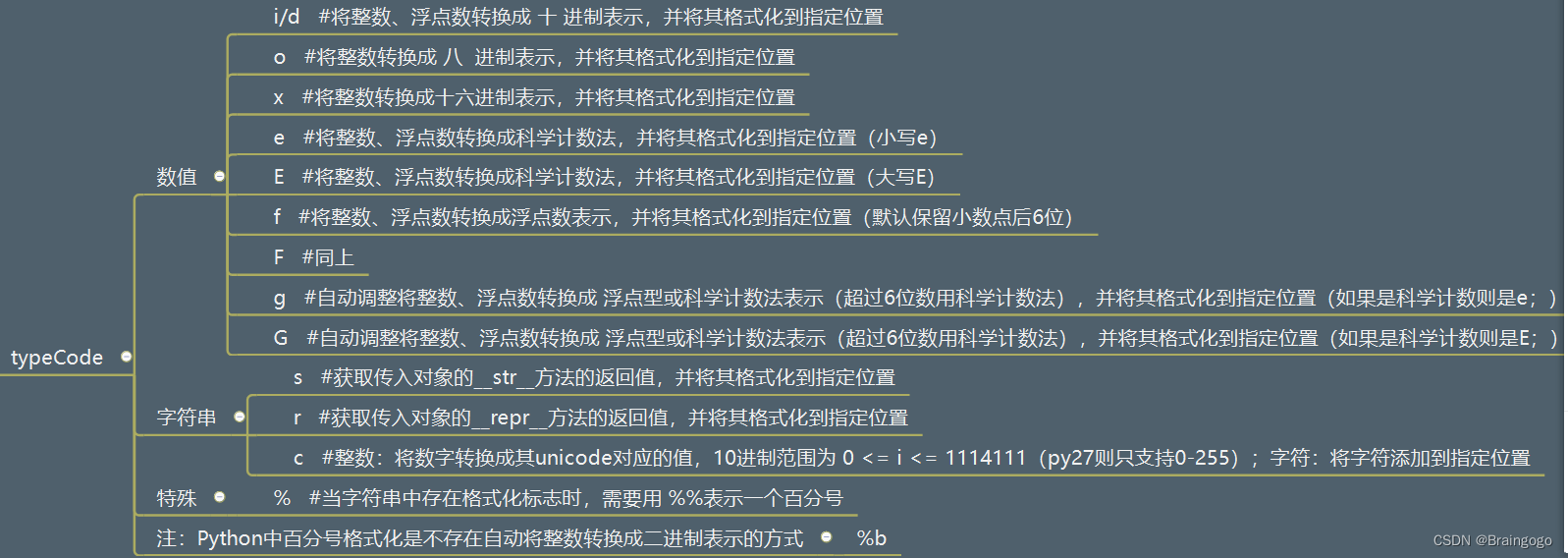
Python的占位格式符
对于print函数里的语句 print("我的名字是%s, 年龄是%d"%(name, age)) 中的%s和%d叫做占位符,它们的完整形态是 %[(name)][flags][width][.precision]typecode 其中带有[]的前缀都是可以省略的。 [(name)]: (name)表示, 根据, 制定的名称(…...