基于Python构建机器学习Web应用

目录
一、内容介绍
1.Onnx模型
①skl2onnx库安装
2.Netron安装
二、模型构建
1.数据加载
2.划分可训练特征与预测标签
3.训练模型
①第三方库导入
②数据集划分
③SVC模型构建
④精度评价
二、模型转换及可视化
1.参数配置
2.Onnx模型生成
3.可视化模型
四、构建Web应用程序
1.构建HTML文件
2.构建JavaScript代码
3.测试Web程序
六、总结
本文相关数据资源免费下载
在本文中,你将学到:
0 如何构建模型并将其保存为Onnx模型
1 如何使用Netron可视化模型
2 如何在Web应用中使用模型进行预测
📈 机器学习最有用的实际用途之一是构建推荐系统,今天我们可以朝着这个方向迈出第一步!
一、内容介绍
在系列8的文章中,我们构建了一个基于UFO目击事件的回归模型,对其使用pickle库进行封装打包,并基于Flask库构建了Web应用,虽然这个打包方法简单易用,但是对于大多数Web应用,其构建环境是基于JavaScript语言的,因此使用一个JavaScript打包并使用模型更容易拓展和广泛应用。
1.Onnx模型
构建机器学习模型应用是AI业务系统中的重要组成部分。通过使用Onnx,我们可以在各种Web应用程序中使用模型。Python的第三方库skl2onnx可以帮我们把Scikit-learn模型转换为Onnx模型。
ONNX(Open Neural Network Exchange),开放神经网络交换,是用于在各种深度学习训练和推理框架转换的一个中间表示格式。在实际业务中,可以使用Pytorch或者TensorFlow训练模型,导出成ONNX格式,然后在转换成目标设备上支撑的模型格式,比如TensorRT Engine、NCNN、MNN等格式。ONNX定义了一组和环境,平台均无关的标准格式,来增强各种AI模型的可交互性,开放性较强。
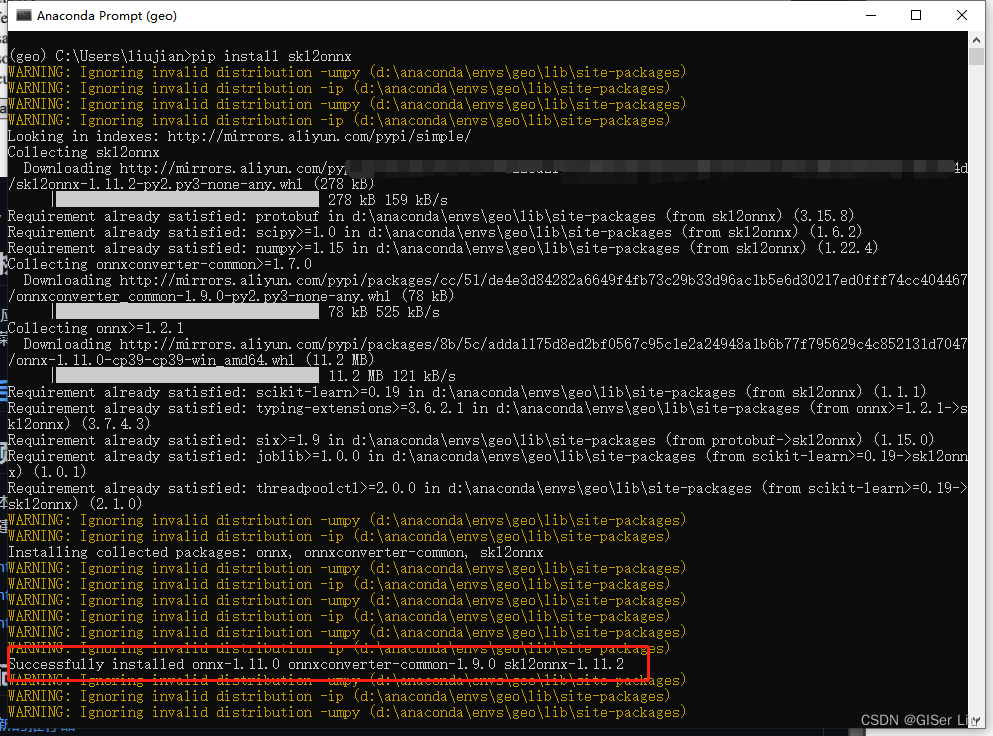
①skl2onnx库安装
pip install -i https://mirrors.aliyun.com/pypi/simple/ skl2onnx看到下图信息代表安装成功:
2.Netron安装
Netron是一个深度学习模型可视化库,其支持以下格式的模型存储文件:
ONNX (.onnx, .pb)
Keras (.h5, .keras)
CoreML (.mlmodel)
TensorFlow Lite (.tflite)
netron并不支持pytorch通过torch.save方法导出的模型文件,因此在pytorch保存模型的时候,需要将其导出为onnx格式的模型文件,可以利用torch.onnx模块实现这一目标。
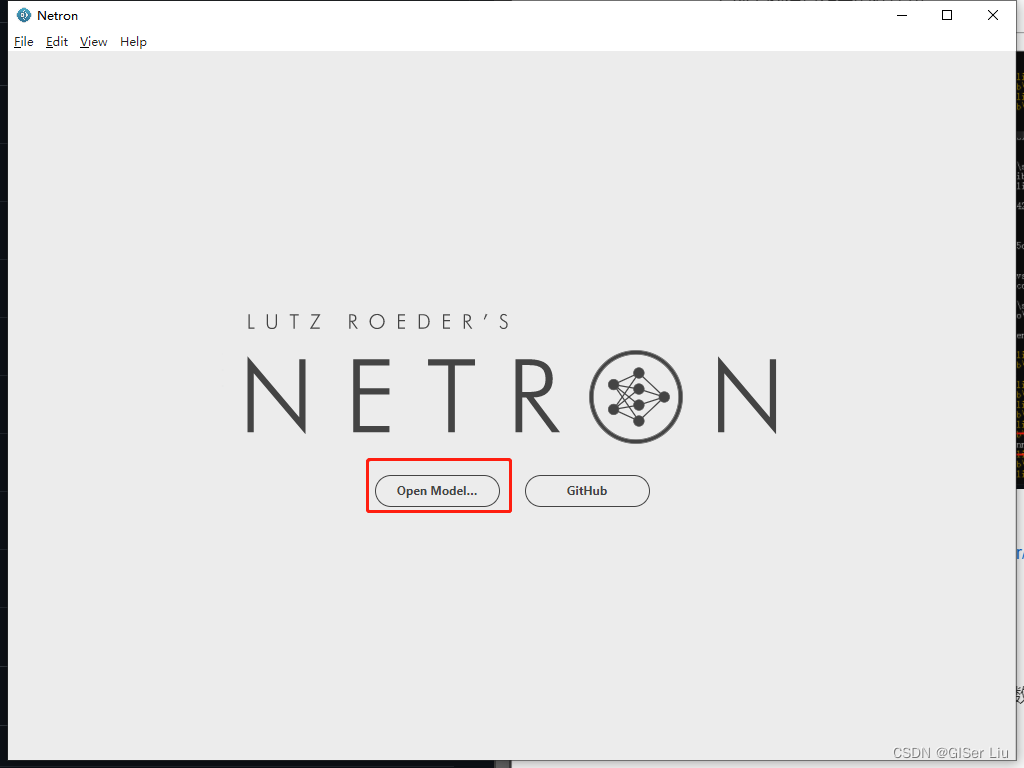
Netron安装链接
安装好以后,双击即可运行,选中我们模型进行可视化查看。
二、模型构建
首先,使用我们之前已清理的亚洲美食数据集训练SVC线性分类模型。
1.数据加载
导入第三方库并调用查看之前处理好的亚洲美食数据集。
import pandas as pd
data = pd.read_csv('cleaned_cuisines.csv')
data.head()
2.划分可训练特征与预测标签
删去不需要的两列数据,并将剩余数据赋值给X,同理将标签另存为Y:
X = data.iloc[:,2:]#X为可训练特征
Y = data['cuisine']#Y为预测标签3.训练模型
①第三方库导入
从Scikit-learn库中导入需要的函数:
from sklearn.model_selection import train_test_split#用于数据集的划分
from sklearn.svm import SVC#SVC模型
from sklearn.model_selection import cross_val_score#
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report#调用精度评价函数②数据集划分
将数据集以7:3的比例划分为训练集与测试集:
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,test_size=0.3)③SVC模型构建
构建一个SVC模型,核函数为“linear”。使用划分好的训练集数据进行模型训练。
model = SVC(kernel='linear', C=10, probability=True,random_state=0)
model.fit(X_train,Y_train.values.ravel())④精度评价
用训练好的模型预测出预测标签Y_pred,并打印出精度评价表。
Y_pred = model.predict(X_test)
print(classification_report(Y_test,Y_pred))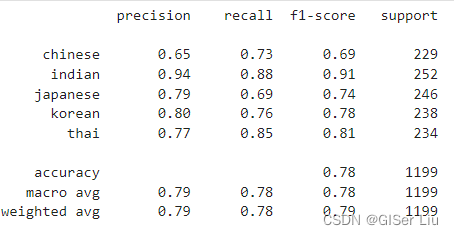
二、模型转换及可视化
在前文中,我们以及训练好了SVC模型,其精度达到了79%。现在我们需要将模型转换为Onnx格式。
确保使用正确的张量数进行转换,此数据集中有380个特征,因此我们需要在FloatTensorType函数中设定好特征数量。
1.参数配置
配置好Onnx模型参数,如数据类型为Float,数据类型为[1,380]的张量。
from skl2onnx import convert_sklearn
from skl2onnx.commmon.data_types import FloatTensorType
initial_type = [('float_input',FloatTensorType([None, 380]))]
options = {id(model):{'nocl': True, 'zipmap': False}}2.Onnx模型生成
基于以上参数生成Onnx模型并保存在model.onnx文件中:
onx = convert_sklearn(model, initial_types=initial_type, options=options)
with open("model.onnx", "wb") as f:
f.write(onx.SerializeToString())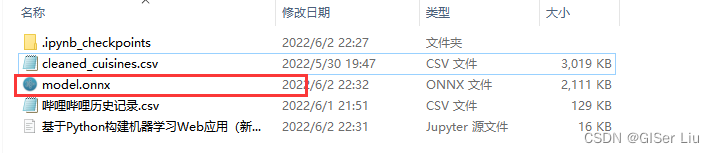
现在,我们可以在文件夹中看到Onnx模型。

3.可视化模型
Onnx模型结构在代码中看起来并不是很明显,我们Netron软件来可视化模型。打开Netron软件,点击Open model,加载模型,选择我们刚刚生成的model.onnx文件。
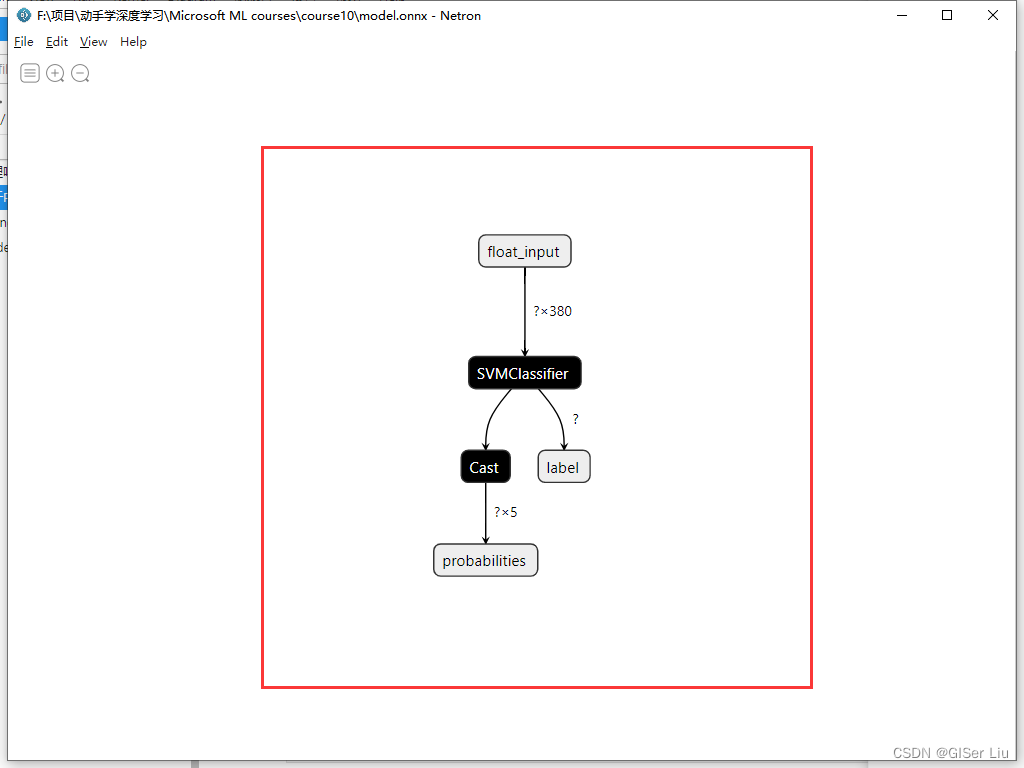
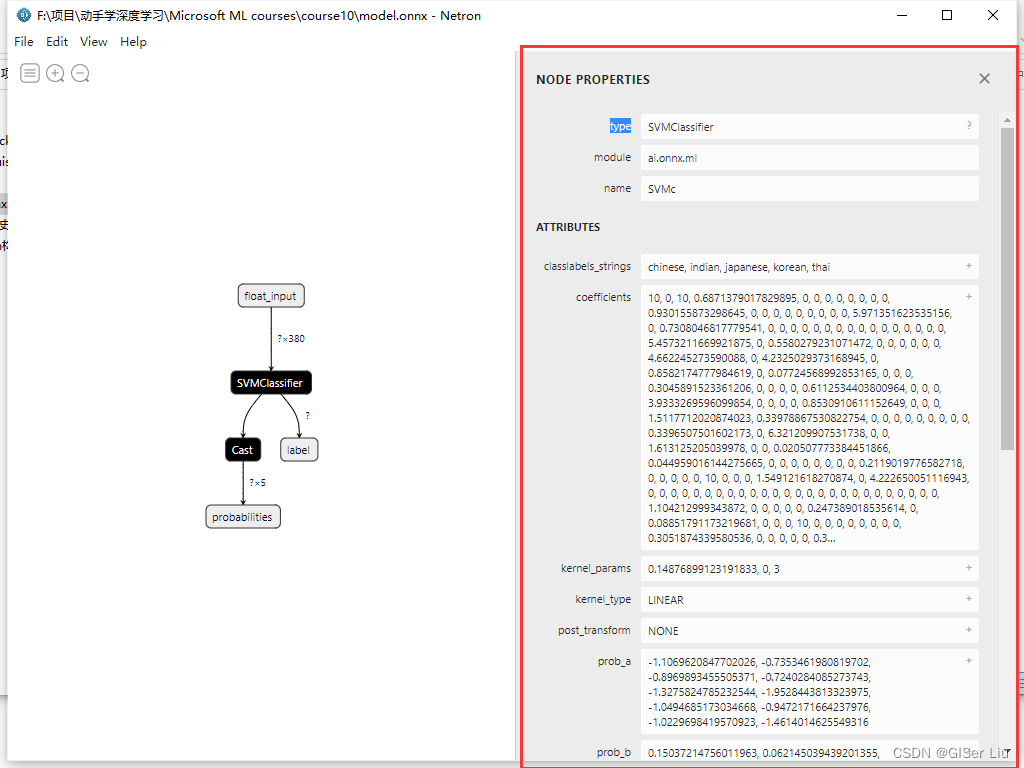
可以看到,模型的结构已被可视化,其中列出了380个特征输入与所用的分类器。我们可以点击不同的部分查看其数据类型,输出结果类型以及参数配置。
四、构建Web应用程序
现在,我们已经准备在Web应用程序上使用此模型,首先,我们先构建一个Web应用程序。
1.构建HTML文件
在文件夹下新建index.html,加入以下代码:(简单的Web代码,有点前端基础应该都能看懂)
<div class="boxCont">
<input type="checkbox" value="247" class="checkbox">
<label>pear</label>
</div>
<div class="boxCont">
<input type="checkbox" value="77" class="checkbox">
<label>cherry</label>
</div>
<div class="boxCont">
<input type="checkbox" value="126" class="checkbox">
<label>fenugreek</label>
</div>
<div class="boxCont">
<input type="checkbox" value="302" class="checkbox">
<label>sake</label>
</div>
<div class="boxCont">
<input type="checkbox" value="327" class="checkbox">
<label>soy sauce</label>
</div>
<div class="boxCont">
<input type="checkbox" value="112" class="checkbox">
<label>cumin</label>
</div>
</div>
<div style="padding-top:10px">
<button onClick="startInference()">预测</button>
</div>
</body>
tip:我们可以看到每个复选框都有一个值value,这个值是食材特征在模型张量中对应的索引。
2.构建JavaScript代码
在标签下方继续构建JavaScript脚本。
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.9.0/dist/ort.min.js"></script>
<script>
//创建一个380的向量,并全部赋值为0
const ingredients = Array(380).fill(0);
//定义全局检查变量,用于获取复选框值
const checks = [...document.querySelectorAll('.checkbox')];
//foreach语句是for语句特殊情况下的增强版本,简化了编程,提高了代码的可读性和安全性。
checks.forEach(check => {
check.addEventListener('change', function() {
// toggle the state of the ingredient
// based on the checkbox's value (1 or 0)
ingredients[check.value] = check.checked ? 1 : 0;
});
});
//定义函数,检查check列表中是否有复选框被勾选,有则返回Ture,否则False
function testCheckboxes() {
return checks.some(check => check.checked);
}
//构建异步加载函数
async function startInference() {
let atLeastOneChecked = testCheckboxes()
if (!atLeastOneChecked) {
alert('请至少勾选一个复选框.');
return;
}
try {
// 创建一个新的 sessio加载模型.
const session = await ort.InferenceSession.create('model.onnx');
alert('模型加载成功!')
//创建一个[1,380]的张量对象
const input = new ort.Tensor(new Float32Array(ingredients), [1, 380]);
const feeds = { float_input: input };
alert('参数输入成功!')
//输入模型session并开始预测,将结果赋值给results
const results = await session.run(feeds);
//读取results的值并以弹出框的形式展示结果
alert('你可以享受' + results.label.data[0] + ' 的美味!')
} catch (e) {
console.log(`模型加载失败!`);
console.error(e);
}
}
</script>代码解析:
0 我们首先创建了一个包含380个值的数组,值默认全为0,这些值需要设置好后输入到模型进行预测,我们可以通过是否勾选复选框来更改某些参数。
1 我们创建了一个复选框数组,当我们选中该复选框时,数组中对应位置的值则会发生变化,变为1。默认为0。
2 我们创建了一个函数testCheckboxes,用于检查是否选中复选框。
3 当按下按钮时,该函数被调用,如果存在被选中的复选框,则加载模型,开始预测结果。
3.测试Web程序
在文件夹中选中双击我们建立的index.html软件,稍等片刻可以看到,界面已经加载出来。输入参数即可运行。
部分读者可能运行后没有效果,因为引入的js代码网站有墙。禁止访问,导致引入超时。读者可自行下载相关JavaScript代码,进行本地调用。
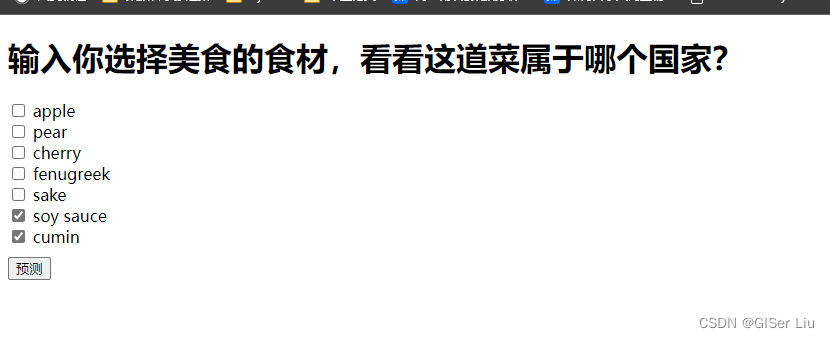
🏆🏆至此,我们的Web应用测试成功!你可以将其部署到你的服务器上或者硬件上😁。
六、总结
在本文中,我们基于之前的亚洲美食数据集构建了SVC模型,并介绍了模型可视化工具Netron与Onnx模型格式的使用。与之前基于Python的pkl格式模型相比,Onnx格式的模型适用性更好,可以在多个平台使用。且OnnxRuntime拥有各种语言的API,💻我们可以在各个环境中部署机器学习模型应用!

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!
“本站所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_45590504/category_11752103.html?spm=1001.2014.3001.5482百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。”
系列文章
机器学习系列0 机器学习思想_GISer Liu的博客-CSDN博客
机器学习系列1 机器学习历史_GISer Liu的博客-CSDN博客
机器学习系列2 机器学习的公平性_GISer Liu的博客-CSDN博客_公平机器学习
机器学习系列3 机器学习的流程_GISer Liu的博客-CSDN博客
机器学习系列4 使用Python创建Scikit-Learn回归模型_GISer Liu的博客-CSDN博客
机器学习系列5 利用Scikit-learn构建回归模型:准备和可视化数据(保姆级教程)_GISer Liu的博客-CSDN博客
机器学习系列6 使用Scikit-learn构建回归模型:简单线性回归、多项式回归与多元线性回归_GISer Liu的博客-CSDN博客_多元多项式回归机器学习系列7 基于Python的Scikit-learn库构建逻辑回归模型_GISer Liu的博客-CSDN博客机器学习系列8 基于Python构建Web应用以使用机器学习模型_GISer Liu的博客-CSDN博客
一文读懂机器学习分类全流程_GISer Liu的博客-CSDN博客
相关文章:
python - 密码加密与解密
Python之密码加密与解密 - 对称算法一、对称加密1.1 安装第三方库 - PyCrypto1.2 加密实现二、非对称加密三、摘要算法3.1 md5加密3.2 sha1加密3.3 sha256加密3.4 sha384加密3.5 sha512加密3.6 “加盐”加密由于计算机软件的非法复制,通信的泄密、数据安全受到威胁。…...
百度飞桨PaddleSpeech的简单使用
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型,一些典型的应用示例如下:语音识别、语音翻译 (英译中)、语音合成、标点恢复等。…...
Python数据标准化
目录 一.数据标准化方式 1.实现中心化和正态分布的Z-Score 2.实现归一化的Max-Min 3.用于稀疏数据的MaxAbs 4.针对离群点的RobustScaler 二.Python针对以上几种标准化方法处理数据 三.总结 一.数据标准化方式 1.实现中心化和正态分布的Z-Score Z-Score标准化是基于原…...
Pycharm无法下载汉化包,一招教你搞定
Pycharm无法下载汉化包,一招教你搞定Pycharm直接导入汉化包Pycharm 无法采用自带的插件安装汉化包Pycharm直接导入汉化包 Pycharm 是可以直接导入汉化包的,这为很多初学者省区了不少麻烦。具体就是: 1:点击pycharm界面右上角的设…...

python成功实现“高配版”王者小游戏?【赠源码】
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 本游戏完整源码、素材: 点击此处跳转文末名片获取 咳咳,又是一款新的小游戏,就是大家熟悉的王者~ 来看我用python来实现高(di)配版的王者 是一款拿到代码运行后,…...
【项目实战】Python实现多元线性回归模型(statsmodels OLS算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 回归问题是一类预测连续值的问题,而能满足这样要求的数学模型称作回归模型,本项…...
graphviz安装教程(2022最新版)初学者适用
1、首先在官网下载graphviz 下载网址:https://www.graphviz.org/download/ 2、安装。 打开第一步已经下载好的软件。点击下一步,在安装路径选择时可将安装路径修改为 D:\graphviz 接着一直点下一步,即可安装完成。 3、配置环境变量 右键…...

【Windows】搭建Pytorch环境(GPU版本,含CUDA、cuDNN),并在Pycharm上使用(零基础小白向)
文章目录前言一、安装CUDA1、检查电脑是否支持CUDA2、下载并安装CUDA3、下载并安装cuDNN二、安装Pytorch1、安装Anaconda2、切换清华镜像源3、创建环境并激活4、输入Pytorch安装命令5、测试三、在Pycharm上使用搭建好的环境参考文章前言 本人纯python小白,第一次使用…...

Tensorflow与CUDA、cudnn版本对应关系
不同版本的Tensorflow需对应不同的CUDA和cudnn版本,否者容易安装失败。可按下图所示,根据想要安装的Tensorflow版本,选择对应版本的CUDA和cudnn。 其中CUDA的下载链接为: CUDA Toolkit Archive | NVIDIA Developer cudnn下载链…...
ImportError: cannot import name ‘Literal‘ from ‘typing‘ (D:\Anaconda\envs\tensorflow\lib\typing.py)
报错背景: 因为安装tensorflow-gpu版本需要,我把原来的新建的anaconda环境(我的名为tensorflow)中的python3.8降为了3.7。 在导入seaborn包时,出现了以下错误: ImportError: cannot import name Literal …...

100天精通Python(数据分析篇)——第67天:Pandas数据连接、合并、加入、添加、重构函数(merge、concat、join、append、stack、unstack)
文章目录 一、数据连接(pd.merge)1. left、right2. how3. on4. left_on、right_on5. sort6. suffixes7. left_index、right_index二、数据合并(pd.concat)1. index 没有重复的情况2. index 有重复的情况3. DataFrame合并时同时查看行索引和列索引有无重复三、数据加入(pd.…...
yolov5 优化系列(三):修改损失函数
1.使用 Focal loss 在util/loss.py中,computeloss类用于计算损失函数 # Focal lossg h[fl_gamma] # focal loss gammaif g > 0:BCEcls, BCEobj FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)其中这一段就是开启Focal loss的关键!!&…...
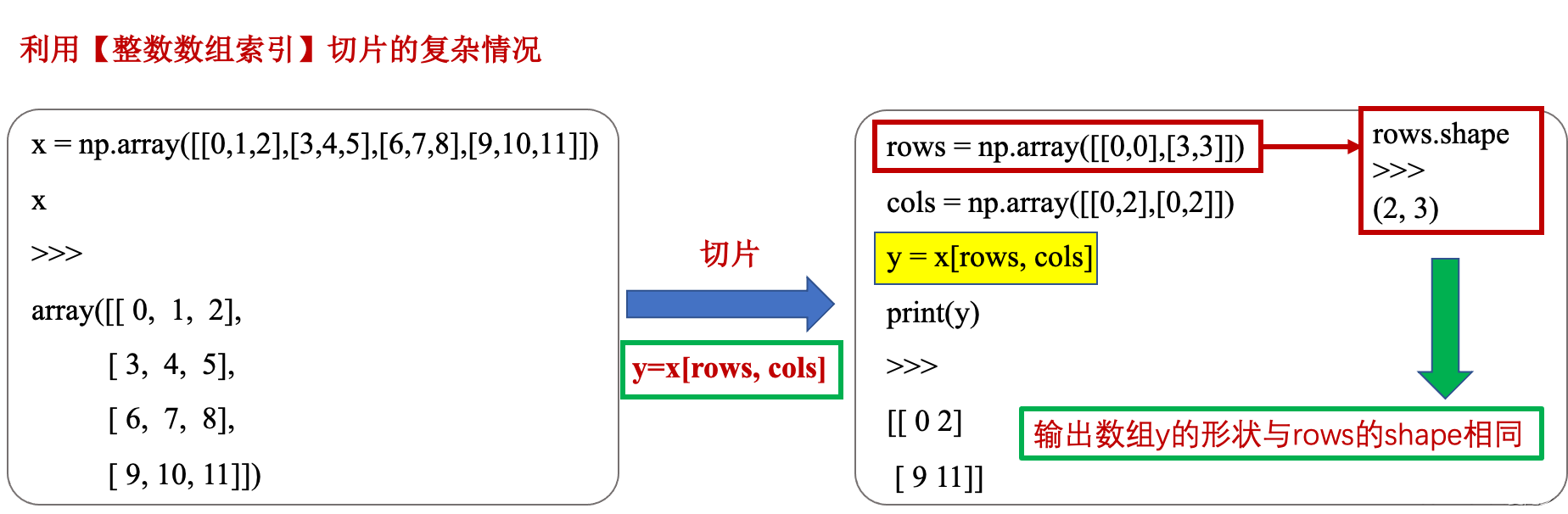
Python中数组切片的用法详解
Python中数组切片的用法详解一、python中“::-1”代表什么?二、python中“:”的用法三、python中数组切片三、numpy中的整数数组索引四、numpy中借助【切片 : 或 …与索引数组】组合进行复杂切片五、布尔索引六、花式索引一、python中“::-1”代表什么? …...
python 安装whl文件
前言 WHL文件是以Wheel格式保存的Python安装包,Wheel是Python发行版的标准内置包格式。在本质上是一个压缩包,WHL文件中包含了Python安装的py文件和元数据,以及经过编译的pyd文件,这样就使得它可以在不具备编译环境的条件下&#…...
Pycharm中安装pytorch
配置虚拟环境 为什么要安装虚拟环境?虚拟环境:把一部分内容独立出来,称之为容器。在容器中,安装我们自己想要的东西,比如不容版本的依赖包。各容器之间相互独立,互不影响。比如下载完 Anaconda 之后&#…...
Package | 解决 module ‘cv2‘ has no attribute ‘gapi_wip_gst_GStreamerPipeline‘
. 问题背景 由于这个问题出现了两回,决定记录一下。实验背景是使用opencv python库进行数据预处理,遇到报错信息如下: “ import cv2 File “/opt/conda/lib/python3.8/site-packages/cv2/init.py”, line 181, in bootstrap() File “/op…...
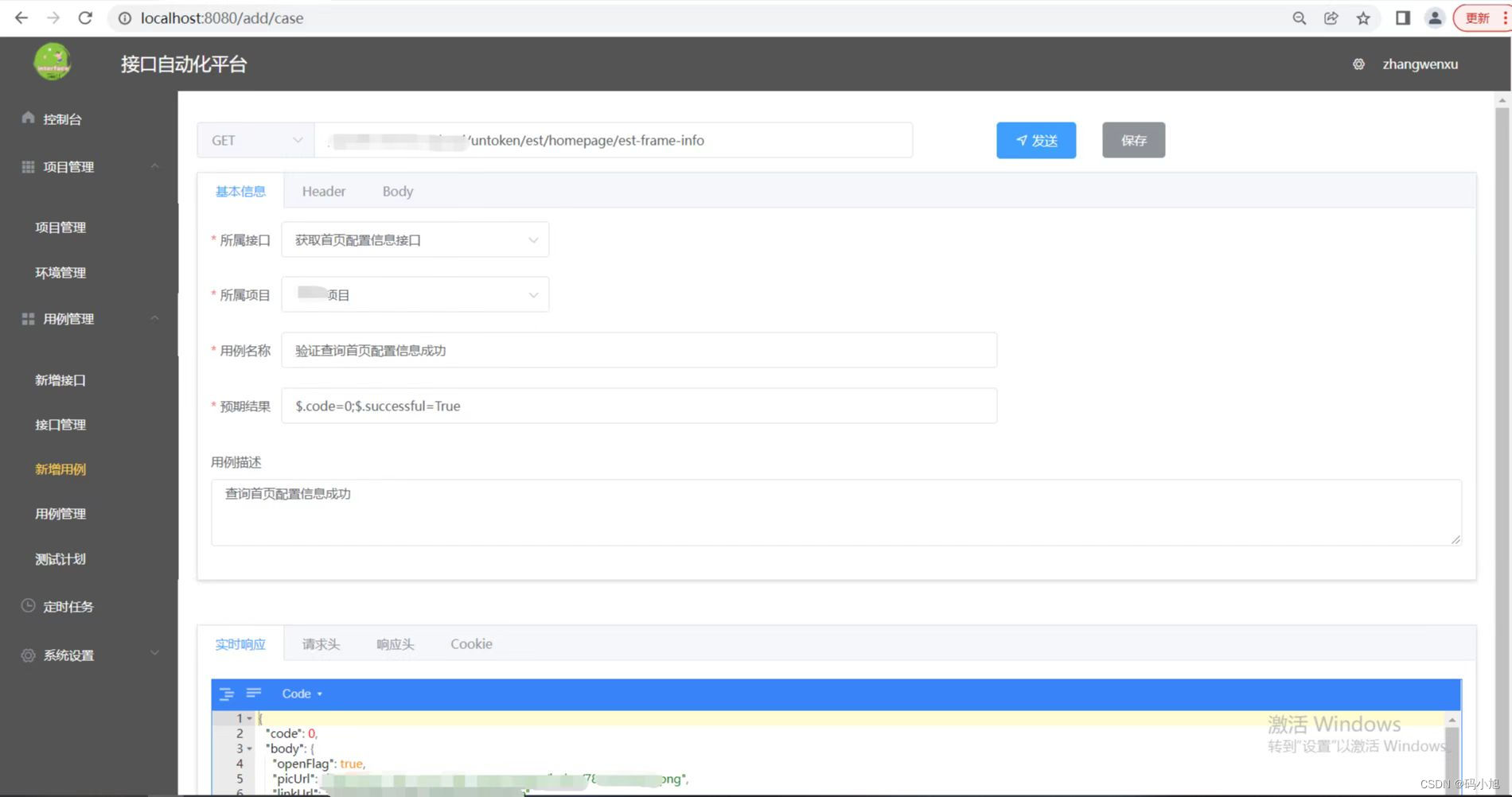
如何在项目中搭建python接口自动化框架?
文章目录前言一、框架目录介绍1、common模块读取Excel代码读取yaml代码(支持场景关联)jsonpath断言封装代码requests二次封装(get、post)configparser读取配置文件递归遍历字典常用方法log日志封装2、conf模块3、data模块4、case模…...
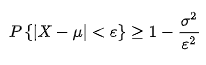
应用统计432考研复试复试提问总结精简版【一】
一、区间估计与假设检验的联系与区别 联系:二者利用样本进行推断,都属于推断统计区别: 原理: 前者是基于大概率,后者基于小概率;统计量:前者是构造枢轴量(不含未知参数,…...
Pytorch模型量化
在深度学习中,量化指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的bit来完成原本以浮点数完成的计算。这么做的好处主要有如下几点: 更少的模型体积,接近4倍的减少;可以更快的计算,由于…...

已解决Encountered error while trying to install package.> lxml
已解决(pip安装第三方模块lxml模块报错)Building wheels for collected packages: lxml Building wheel for lxml (setup.py) … error error: subprocess-exited-with-error python setup.py bdist_wheel did not run successfully. note: This error o…...

距离度量 —— 闵可夫斯基距离(Minkowski Distance)
Python学习系列文章:👉 目录 👈 文章目录一、概述二、计算公式1. 闵氏距离公式2. 闵氏距离的参数 p3. 闵氏距离的缺点一、概述 闵可夫斯基距离 (Minkowski Distance),也被称为 闵氏距离。它不仅仅是一种距离,而是将多…...
python(模块)xlwt
目录一、xlwt简介二、xlwt语法1、模块安装2、模块导入3、向xls文件中写入内容4、设置写入文件的格式4.1 字体设置(font)4.2 背景颜色设置(pattern)4.3 边框设置(borders)4.4 对齐方式设置(align…...

Pytorch中torch.unsqueeze()和torch.squeeze()函数解析
一. torch.squeeze()函数解析 1. 官网链接 torch.squeeze(),如下图所示: 2. torch.squeeze()函数解析 torch.squeeze(input, dimNone, outNone) squeeze()函数的功能是维度压缩。返回一个tensor(张量),其中 input…...
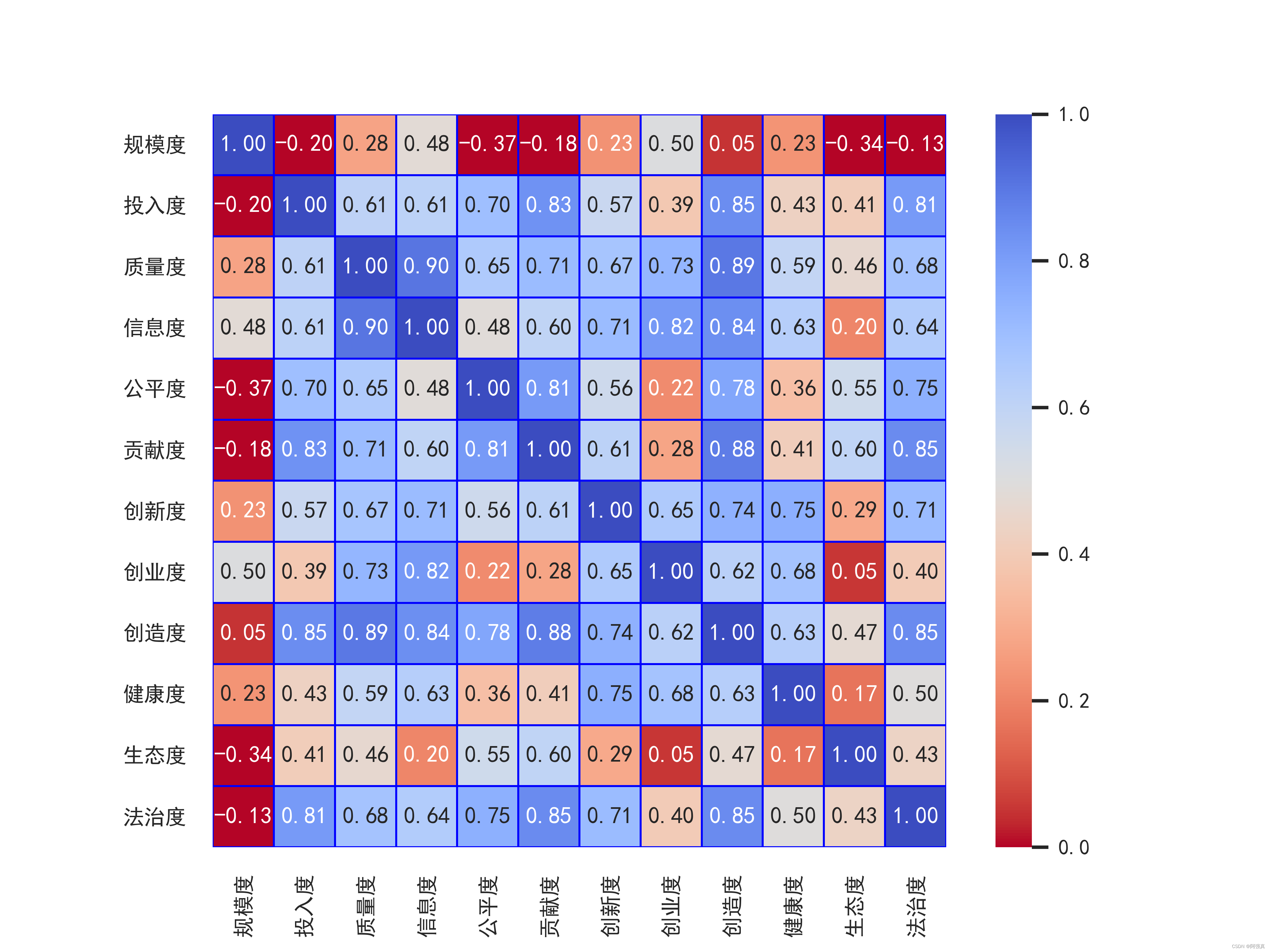
python绘制相关系数热力图
python绘制相关系数热力图一.数据说明和需要安装的库二.准备绘图三.设置配色,画出多幅图全部代码:本文讲述如何利用python绘制如上的相关系数热力图一.数据说明和需要安装的库 数据是31个省市有关教育的12个指标,如下所示。,在文…...
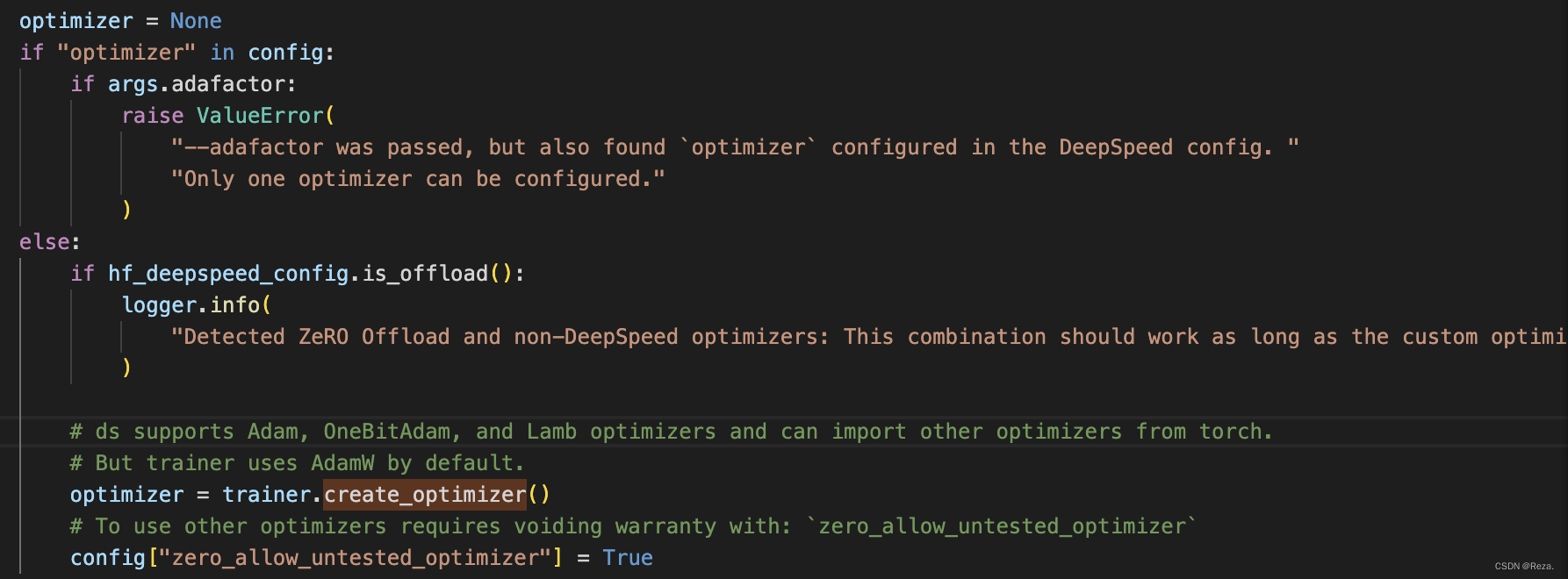
DeepSpeed使用指南(简略版)
现在的模型越来越大,动辄几B甚至几百B。但是显卡显存大小根本无法支撑训练推理。例如,一块RTX2090的10G显存,光把模型加载上去,就会OOM,更别提后面的训练优化。 作为传统pytorch Dataparallel的一种替代,D…...
【Python】tqdm 介绍与使用
文章目录一、tqdm 简介二、tqdm 使用1. 基于迭代对象运行: tqdm(iterator)2. tqdm(list)3. trange(i)4. 手动更新参考链接一、tqdm 简介 tqdm 是一个快速,可扩展的 Python 进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装…...
Pytorch机器学习(十)—— 目标检测中k-means聚类方法生成锚框anchor
Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 目录 Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 前言 一、K-means聚类 k-means代码 k-means算法 二、YOLO中使用k-means聚类生成anchor 读取VO…...
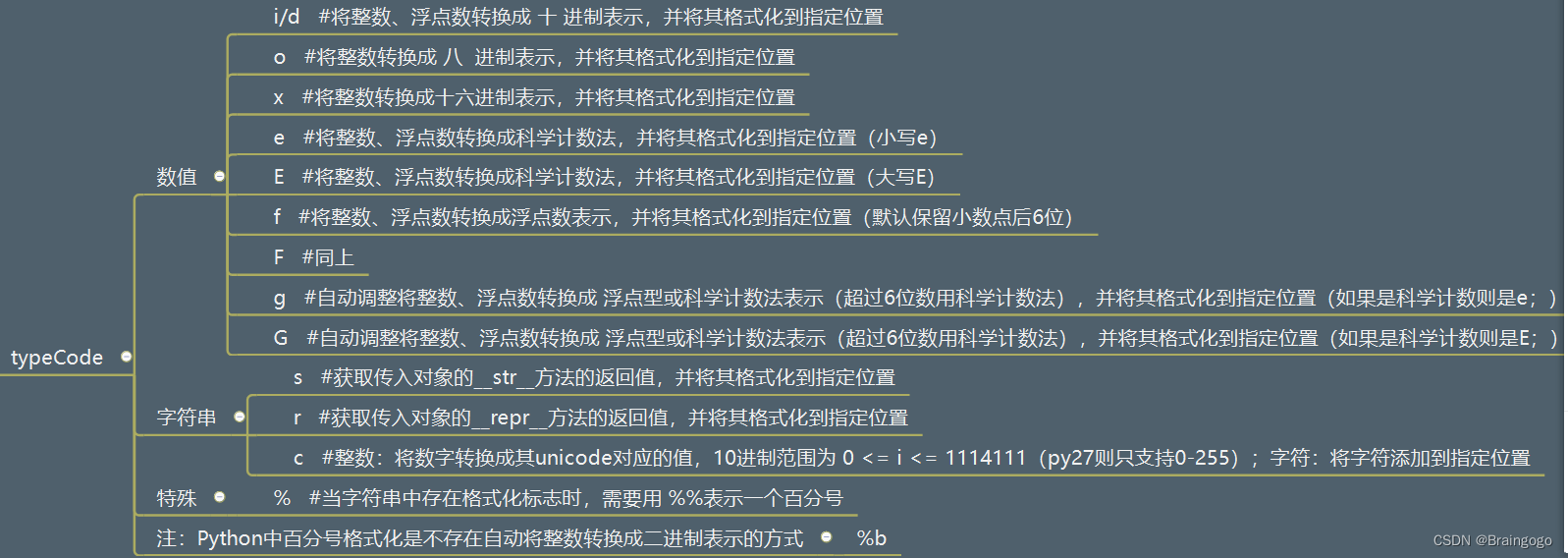
Python的占位格式符
对于print函数里的语句 print("我的名字是%s, 年龄是%d"%(name, age)) 中的%s和%d叫做占位符,它们的完整形态是 %[(name)][flags][width][.precision]typecode 其中带有[]的前缀都是可以省略的。 [(name)]: (name)表示, 根据, 制定的名称(…...
关于sklearn库的安装
对于安装sklearn真的是什么问题都被我遇到了 例如pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(hostfiles.pythonhosted.org, port443): Read timed out.遇到了 这种也遇到了Requirement already satisfied: numpy in c:\users\yjq\appdata\roamin…...
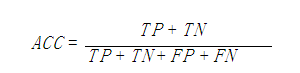
accuracy_score函数
1.acc计算原理 sklearn中accuracy_score函数计算了准确率。 在二分类或者多分类中,预测得到的label,跟真实label比较,计算准确率。 在multilabel(多标签问题)分类中,该函数会返回子集的准确率。如果对于一…...
怎么成为稚晖君?
如何成为IT大佬稚晖君——电子系统设计应具备的基本技能和方法论 快速提高电子技术的必经之路_一些老生常谈的道理 嵌入式AI入坑经历 稚晖君软件硬件开发环境总结 首先,机器学习深度学习这些和硬件是两个领域的内容,个人不建议一起学,注意力…...

Pandas库
Pandas是python第三方库,提供高性能易用数据类型和分析工具。Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用。pandas库引用: import pandas as pd 包括两个数据类型:Series(相当于一维数据类型)&…...

通过两道一年级数学题反思自己
背景 做完这两道题我开始反思自己,到底是什么限制了我?是我自己?是曾经教导我的老师?还是我的父母? 是考试吗?还是什么? 提目 1、正方体个数问题 2、相碰可能性 过程 静态思维: …...
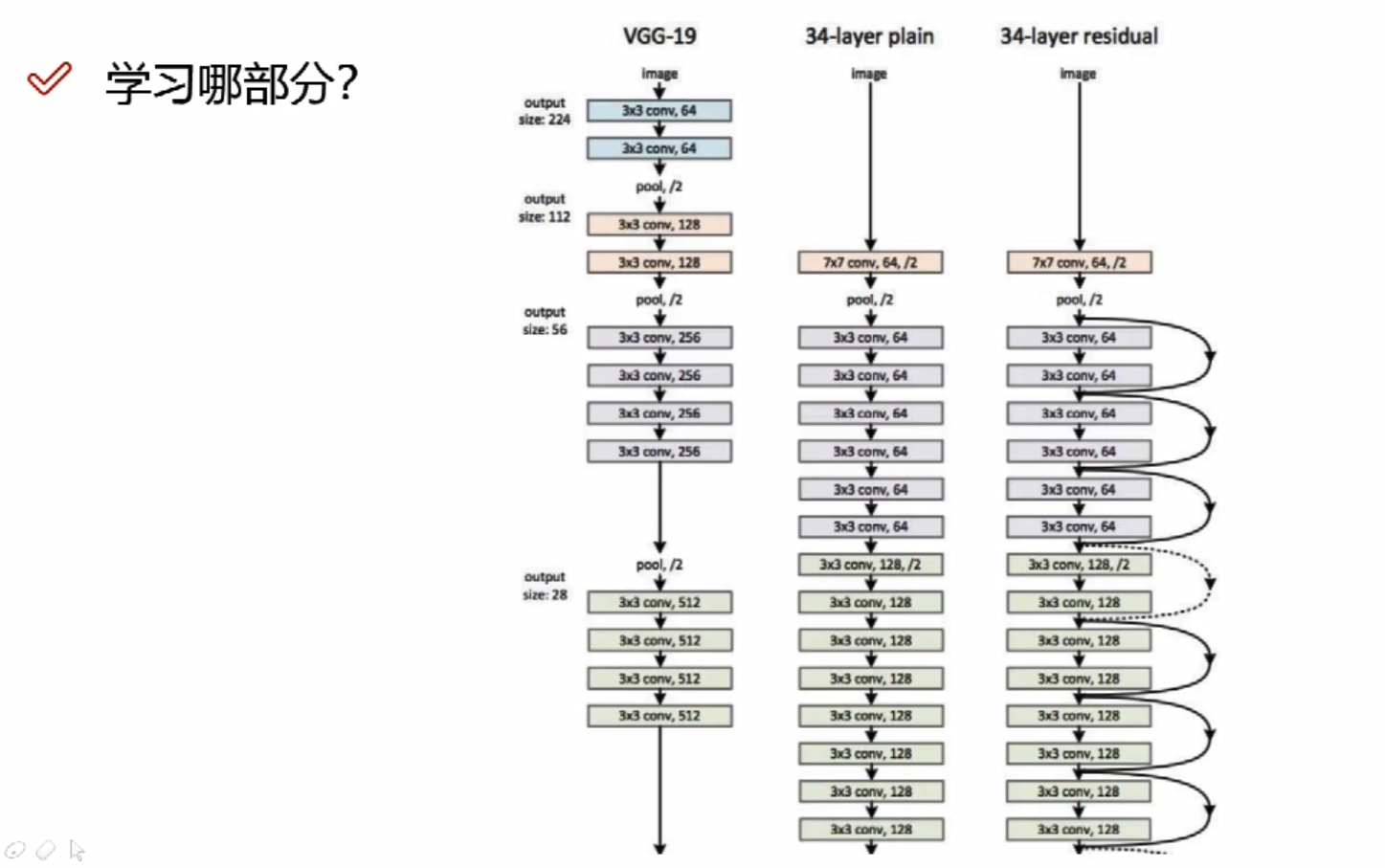
深度学习—卷积神经网络(CNN)全笔记,附代码
本文内容为哔站学习笔记【卷积神经网络-CNN】深度学习(唐宇迪带你学AI):卷积神经网络理论详解与项目实战,计算机视觉,图像识别模块实战_哔哩哔哩_bilibili 目录 深度学习基础 什么是深度学习? 机器学习流…...
Building wheel for mmcv-full (setup.py) ... error解决办法!
mmdetection 安装后,根据官方给的程序安装mmcv时,出现:Building wheel for mmcv-full (setup.py) … error 环境:CUDA11.3, Pytorch1.11 安装根据官网给的安装程序:pip install mmcv-full -f https://download.openmm…...
联邦学习开山之作代码解读与收获
参考:联邦学习代码解读,超详细_一只揪的博客-CSDN博客_联邦学习代码 参考文献:[1602.05629] Communication-Efficient Learning of Deep Networks from Decentralized Data (arxiv.org) 参考代码:GitHub - AshwinRJ/Federated-L…...
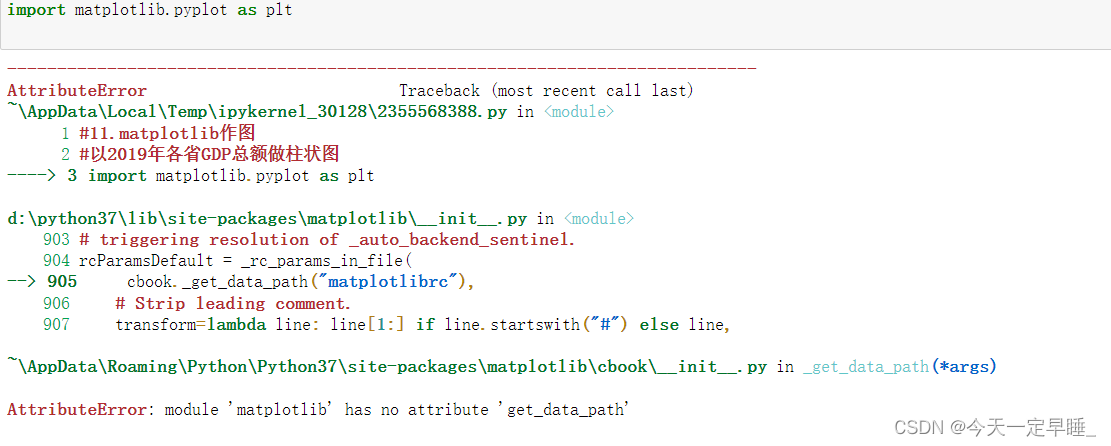
Python安装第三方库常用方法 超详细~
Python安装第三方库常用方法前言安装方法1. 通过pychram安装2. pip安装大法3. 下载whl文件到本地离线安装3.1 补充4.其他方法4.1 Python官方的Pypi菜单4.2 国内镜像源解决pip安装过慢的问题小结前言 在pyhton的学习中,相信大家通常都会碰到第三方库的安装问题&…...
Python--找出字符串中出现次数最多的字符及其出现的次数
方法一: 1、循环遍历列表或字符串,如果字符在字典中则值加1,如果不在则创建(key,value) 2、找到字典中,最大的value值 3、根据最大的value值,找对应的key值,打印出出现次数最多的字符 str &qu…...

滤波笔记一:卡尔曼滤波(Kalman Filtering)详解
本笔记是总结了B站DR_CAN的卡尔曼滤波器的课程,他的B站主页为:DR_CAN的个人空间_哔哩哔哩_bilibili PS:虽然我不是学自控的,但是老师真的讲的很好! 目录 Lesson1 递归算法 Lesson2 数学基础_数据融合_协方差矩阵_状态空间方程…...
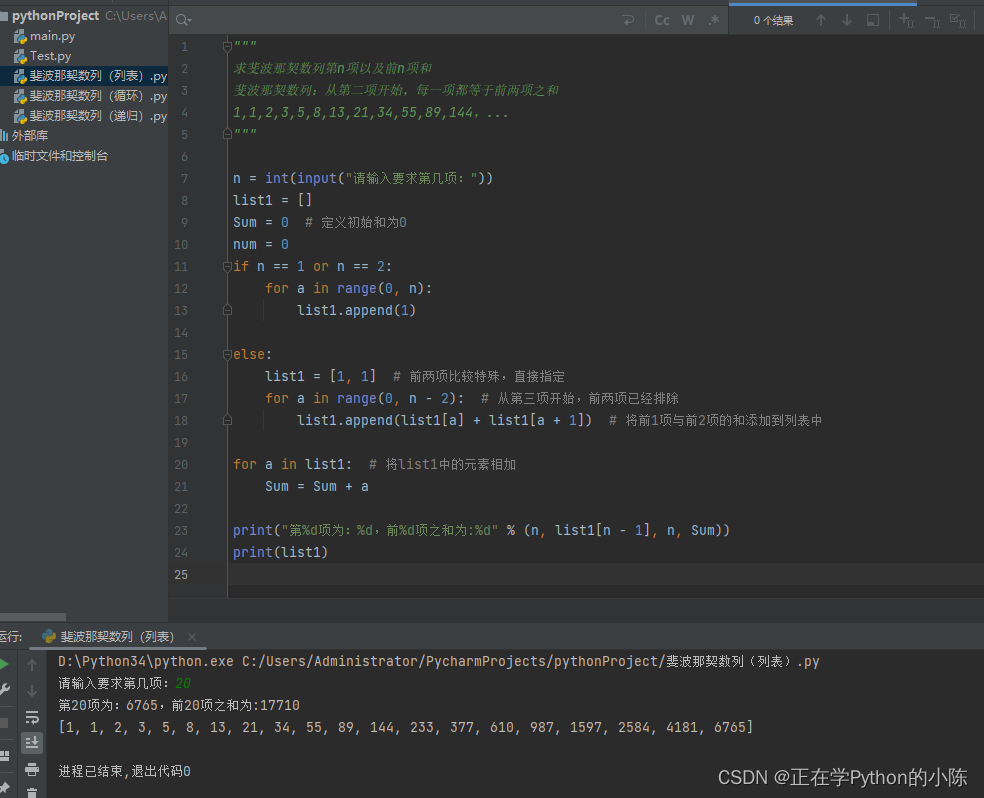
利用Python求斐波那契数列的第N项以及前N项和(循环、递归、集合)
著名的斐波那契数列,即从第三项开始,每一项都等于前两项之和。 之前写过利用Java语言来编写,由于最近正在学Python,所以将自己的想法记录在此,有需要的朋友可以参考一下。 写在前面:这里的三个方法其实思…...
一文速学(十八)-数据分析之Pandas处理文本数据(str/object)各类操作+代码一文详解(三)
目录 前言 一、子串提取 提取匹配首位子串 提取所有匹配项(extractall)...
Python数据分析-数据预处理
数据预处理 文章目录数据预处理1.前言2.数据探索2.1缺失值分析2.2 异常值分析2.2.1 简单统计量分析2.2.2 3$\sigma$原则2.2.3 箱线图分析2.3 一致性分析2.4 相关性分析3.数据预处理3.1 数据清洗3.1.1 缺失值处理3.1.2 异常值处理3.2 数据集成3.2.1 实体识别3.2.2 冗余属性识别3…...
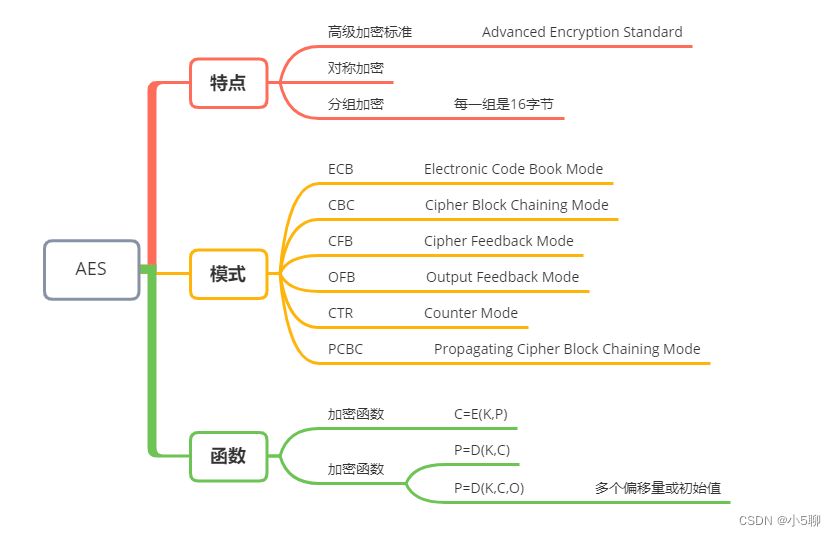
【Python】AES加解密代码,文章还有加密串等你来解密,等你来挑战
🍦🍦写这篇AES文章也是有件趣事,有位小伙伴发了段密文,看看谁解密速度快,学过Python的小伙伴一下子就解开来了,内容也挺有趣的。 🍟🍟原来加解密也可以这么有趣,虽然看起…...
朴素贝叶斯模型及案例(Python)
目录 1 朴素贝叶斯的算法原理 2 一维特征变量下的贝叶斯模型 3 二维特征变量下的贝叶斯模型 4 n维特征变量下的贝叶斯模型 5 朴素贝叶斯模型的sklearn实现 6 案例:肿瘤预测模型 6.1 读取数据与划分 6.1.1 读取数据 6.1.2 划分特征变量和目标变量 6.2 模型…...
python之Tkinter详解
Python之Tkinter详解 文章目录Python之Tkinter详解1、Tkinter是什么2、Tkinter创建窗口①导入 tkinter的库 ,创建并显示窗口②修改窗口属性③创建按钮④窗口内的组件布局3、Tkinter布局用法①基本界面、label(标签)和button(按钮)用法②entry(输入)和text(文本)用法…...

【python】python进行debug操作
文章目录前言一、debug环境介绍二、debug按钮介绍2.1、step into:单步执行(遇到函数也是单步)2.2、step over:单步执行(遇到函数,全部运行)2.3、step into my code:(直接跳到下一个断点)2.4、st…...

Python安装tensorflow过程中出现“No matching distribution found for tensorflow”的解决办法
在Pycharm中使用pip install tensorflow安装tensorflow时报错: ERROR: Could not find a version that satisfies the requirement tensorflow(from versions: none) ERROR: No matching distribution found for tensorflow搜了好多帖子有的说可能是网络的问题&…...

pandas中的read_csv参数详解
1.官网语法 pandas.read_csv(filepath_or_buffer, sepNoDefault.no_default**,** delimiterNone**,** headerinfer’, namesNoDefault.no_default**,** index_colNone**,** usecolsNone**,** squeezeFalse**,** prefixNoDefault.no_default**,** mangle_dupe_colsTrue**,** dty…...
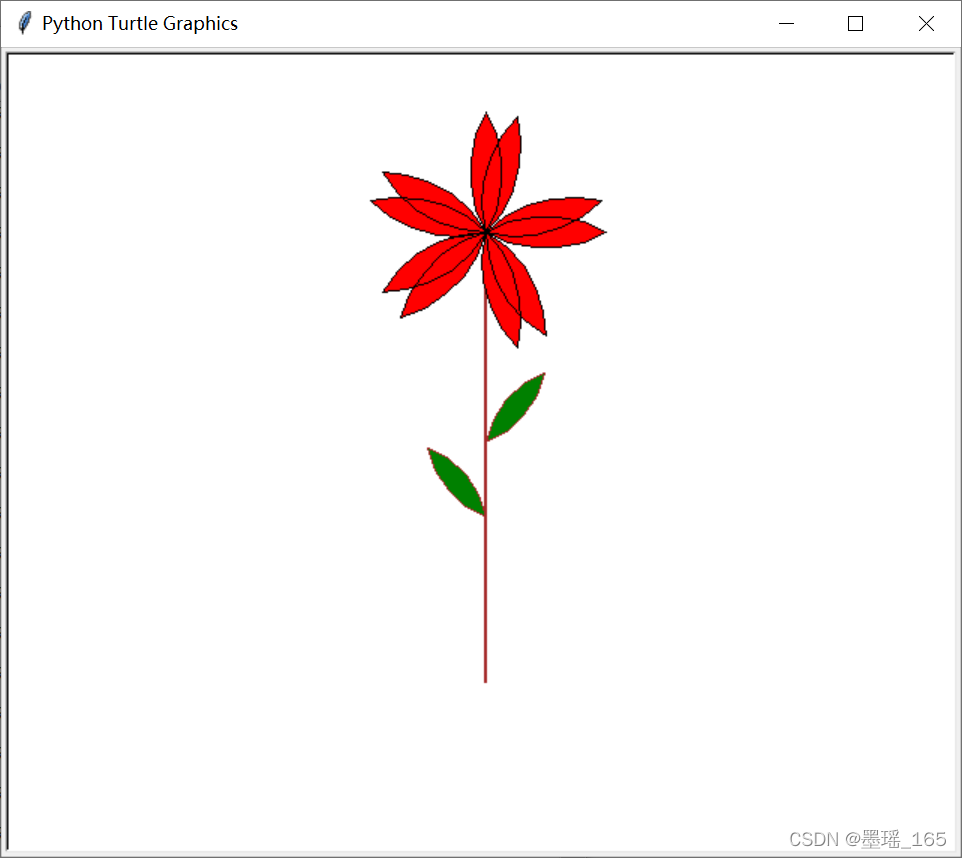
Python — — turtle 常用代码
目录 一、设置画布 二、画笔 1、画笔属性 2、绘图命令 (1) 画笔运动命令 (2) 画笔控制命令 (3) 全局控制命令 (4) 其他命令 3. 命令详解 三、文字显示为一个圆圈 四、画朵小花 一、设置画布 turtle为我们展开用于绘图区域,我们可以设置它的…...

【我是土堆 - PyTorch教程】学习随手记(已更新 | 已完结 | 10w字超详细版)
目录 1. Pytorch环境的配置及安装 如何管理项目环境? 如何看自己电脑cuda版本? 安装Pytorch 2. Python编辑器的选择、安装及配置 PyCharm PyCharm神器 Jupyter(可交互) 3. Python学习中的两大法宝函数 说明 实战操…...