【模拟 简易银行系统~python】
目录~python
- 面向对象编程之模拟银行系统
- 相关程序代码如下:
- 运行效果如下:
- pandas 每日一练:
- 运行结果为:
- 66、绘制sku_cost_prc的密度曲线
- 运行效果为:
- 67、计算后一天与前一天sku_cost_prc的差值
- 运行结果为:
- 68、计算后一天与前一天sku_cost_prc变化率
- 运行结果为:
- 69、设置日期为索引
- 运行结果为:
- 70、以9个数据作为一个数据滑动窗口,在这5个数据上取均值(`sku_cost_prc`)
- 运行结果为:
- 每日一言:
- 持续更新中...
个人昵称:lxw-pro
个人主页:欢迎关注 我的主页
个人感悟: “失败乃成功之母”,这是不变的道理,在失败中总结,在失败中成长,才能成为IT界的一代宗师。
面向对象编程之模拟银行系统
现在呀,虽说已经大面积的使用微信支付、支付宝支付等,可要想微信、支付宝等留有余额,还是离不开我们的存款,存款的话也得有现金,当然,自动取款机还是依旧那么方便 ,“自己动手,丰衣足食”,那么,我们的自动取款机又是怎么知道你存了这么多,怎么清楚地知道你的余额的呢,下面我们来康康这所谓的简易模拟系统叭!
相关程序代码如下:
import datetime
class Bank(object):
account_log = []
def __init__(self, name):
self.name = name
def deposit(self, amount): # 存钱
user.balance += amount
self.write_log('存钱', amount)
def withdrawal(self, amount): # 取钱
if amount > user.balance:
print("余额不足")
else:
user.balance -= amount
self.write_log('取钱', amount)
def write_log(self, type, amount): # 写日志
now = datetime.datetime.now()
ct = now.strftime("%Y-%m-%d %H:%M:%S")
data = [self.name, user.name, ct, type, amount, f"{user.balance:.2f}"]
Bank.account_log.append(data)
class User(object):
def __init__(self, name, balance):
self.name = name
self.balance = balance
def print_log(self):
for item in Bank.account_log:
print(item)
def show_menu():
menu = '''
0: 退出
1: 存款
2: 取款
3: 打印交易信息
'''
print(menu)
bank = Bank("贵阳银行")
user = User('lxw-pro', 520)
while True:
show_menu()
num = int(input("请输入菜单编号:"))
if num == 0:
print("退出系统")
break
elif num == 1:
print("存款")
amount = float(input("请输入存款金额:"))
bank.deposit(amount)
print(f"当前金额是{user.balance:.2f}")
elif num == 2:
print("取款")
amount = float(input("请输入取款金额:"))
bank.withdrawal(amount)
print(f"当前金额是{user.balance:.2f}")
elif num == 3:
print("查看记录")
user.print_log()
else:
print("输入有误!")
运行效果如下:
看效果,有点长,故截成两张图
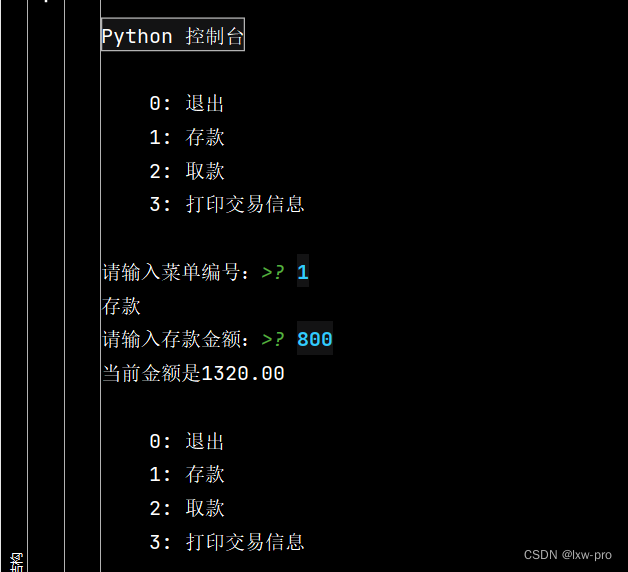
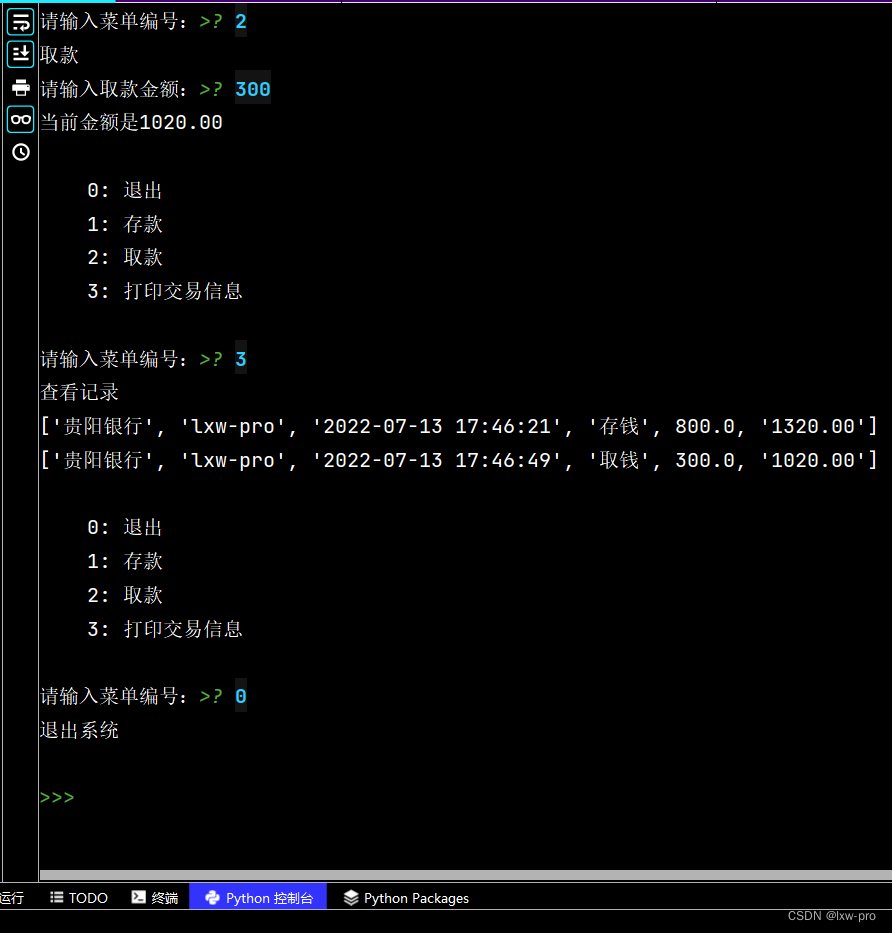
————————————————————————————————————————————
pandas 每日一练:
# -*- coding = utf-8 -*-
# @Time : 2022/7/29 15:15
# @Author : lxw_pro
# @File : pandas-11 练习.py
# @Software : PyCharm
import pandas as pd
import matplotlib.pyplot as plt
lxw = pd.read_excel("site.xlsx")
print(lxw)
运行结果为:
Unnamed: 0 Unnamed: 0.1 create_dt ... yye sku_cost_prc lrl
0 0 1 2016-11-30 ... 8.8 6.77 30.00%
1 1 2 2016-11-30 ... 7.5 5.77 30.00%
2 2 3 2016-11-30 ... 5.0 3.85 30.00%
3 3 4 2016-11-30 ... 19.6 7.54 30.00%
4 4 5 2016-12-02 ... 13.5 10.38 30.00%
.. ... ... ... ... ... ... ...
751 751 752 2016-12-31 ... 1.0 0.77 30.00%
752 752 753 2016-12-31 ... 2.0 1.54 30.00%
753 753 754 2016-12-31 ... 1.0 0.77 30.00%
754 754 755 2016-12-31 ... 7.6 2.92 30.00%
755 755 756 2016-12-31 ... 3.3 2.54 30.00%
[756 rows x 8 columns]
66、绘制sku_cost_prc的密度曲线
lxw['sku_cost_prc'].plot(kind='kde')
plt.show()
运行效果为:

67、计算后一天与前一天sku_cost_prc的差值
print(-lxw['sku_cost_prc'].diff())
运行结果为:
0 NaN
1 1.00
2 1.92
3 -3.69
4 -2.84
...
751 3.13
752 -0.77
753 0.77
754 -2.15
755 0.38
Name: sku_cost_prc, Length: 756, dtype: float64
68、计算后一天与前一天sku_cost_prc变化率
print(-lxw['sku_cost_prc'].pct_change())
运行结果为:
0 NaN
1 0.147710
2 0.332756
3 -0.958442
4 -0.376658
...
751 0.802564
752 -1.000000
753 0.500000
754 -2.792208
755 0.130137
Name: sku_cost_prc, Length: 756, dtype: float64
69、设置日期为索引
data = lxw.set_index('create_dt')
print(data)
运行结果为:
Unnamed: 0 Unnamed: 0.1 sku_cnt ... yye sku_cost_prc lrl
create_dt ...
2016-11-30 0 1 1.0 ... 8.8 6.77 30.00%
2016-11-30 1 2 1.0 ... 7.5 5.77 30.00%
2016-11-30 2 3 1.0 ... 5.0 3.85 30.00%
2016-11-30 3 4 2.0 ... 19.6 7.54 30.00%
2016-12-02 4 5 1.0 ... 13.5 10.38 30.00%
... ... ... ... ... ... ...
2016-12-31 751 752 1.0 ... 1.0 0.77 30.00%
2016-12-31 752 753 1.0 ... 2.0 1.54 30.00%
2016-12-31 753 754 1.0 ... 1.0 0.77 30.00%
2016-12-31 754 755 2.0 ... 7.6 2.92 30.00%
2016-12-31 755 756 1.0 ... 3.3 2.54 30.00%
[756 rows x 7 columns]
70、以9个数据作为一个数据滑动窗口,在这5个数据上取均值(sku_cost_prc)
jz = data['sku_cost_prc'].rolling(10).mean()
print(jz)
运行结果为:
create_dt
2016-11-30 NaN
2016-11-30 NaN
2016-11-30 NaN
2016-11-30 NaN
2016-12-02 NaN
...
2016-12-31 5.016
2016-12-31 4.185
2016-12-31 3.500
2016-12-31 2.802
2016-12-31 2.066
Name: sku_cost_prc, Length: 756, dtype: float64
每日一言:
自律的顶端就是享受孤独!这一年里,失去,释怀,成长,完结一半!!
持续更新中…
点赞,你的认可是我创作的
动力!
收藏,你的青睐是我努力的方向!
评论,你的意见是我进步的财富!
关注,你的喜欢是我长久的坚持!

欢迎关注微信公众号【程序人生6】,一起探讨学习哦!!!
相关文章:

【YOLOv7/YOLOv5系列改进NO.52】融入YOLOv8中的C2f模块
文章目录 前言一、解决问题二、基本原理三、YOLOv5添加方法四、YOLOv7添加方法五、总结前言 作为当前先进的深度学习目标检测算法YOLOv7,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点…...

PyTorch 单机多GPU 训练方法与原理整理
PyTorch 单机多GPU 训练方法与原理整理 这里整理一些PyTorch单机多核训练的方法和简单原理,目的是既能在写代码时知道怎么用,又能从原理上知道大致是怎么回事儿。 就目前来说,并行训练的方法可以根据的不同的并行对象分为——模型并行和数据…...
anaconda创建、删除虚拟环境指令
使用conda创建、删除虚拟环境指令{\color{Red}使用conda创建、删除虚拟环境指令}使用conda创建、删除虚拟环境指令 使用conda创建、删除虚拟环境指令{\color{Red}使用conda创建、删除虚拟环境指令}使用conda创建、删除虚拟环境指令 一、创建虚拟环境 二、查看虚拟环境 三、激活…...
NCDC气象数据的提取与处理(二):python批量转换isd-lite数据为xlsx
目录 1.完整代码(部分代码参考https://zhuanlan.zhihu.com/p/556150264) 2.工作过程 2.1输入 2.2过程 3.实际效果 本例使用的相关数据及代码可见 链接:https://pan.baidu.com/s/1EYE0U7RrHSGGk3vptZyNVg 提取码:6666 书接上…...
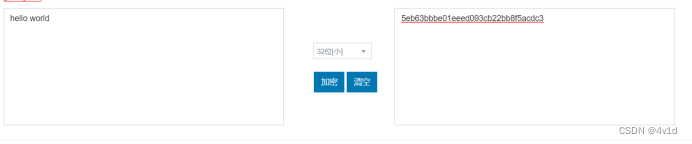
MD5密码实验——Python实现(完整解析版)
文章目录更新:前言实验环境实验内容实验操作步骤1.初始化四个缓冲区2.设置常数表、位移位数等参数3.增加填充4.分组处理5.输出处理实验结果实验心得实验代码MD5-Python.py更新: 感谢评论区的大佬指出错误,现已改进代码 之前的错误在于没有考…...
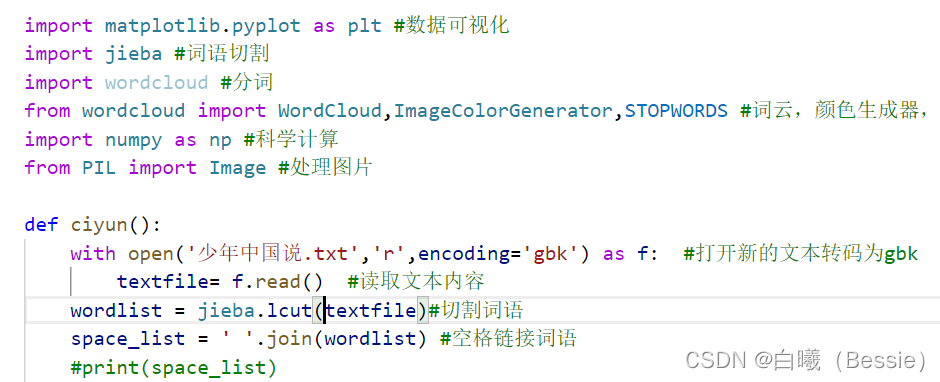
如何在vscode中下载python第三方库(jieba和wordcloud为例)
本文由来 本来我并不想写文章的,但是我发现,对于一个0基础的小白vscode用户而言,想完整的下载一个第三方库还是存在一定的问题,并且我在搜索文章的时候发现,完全没有小白教程,太难了,所以说我就…...
python安装使用pip安装numpy
相信大家最近都在忙,因为到开学和上班的时候了,我最近也很忙,忙的快要流泪,这不是要考计算机三级了吗!买了好厚一本书,备战过程中,最近洗头一次掉了100根不止的头发,有点恐惧&#x…...
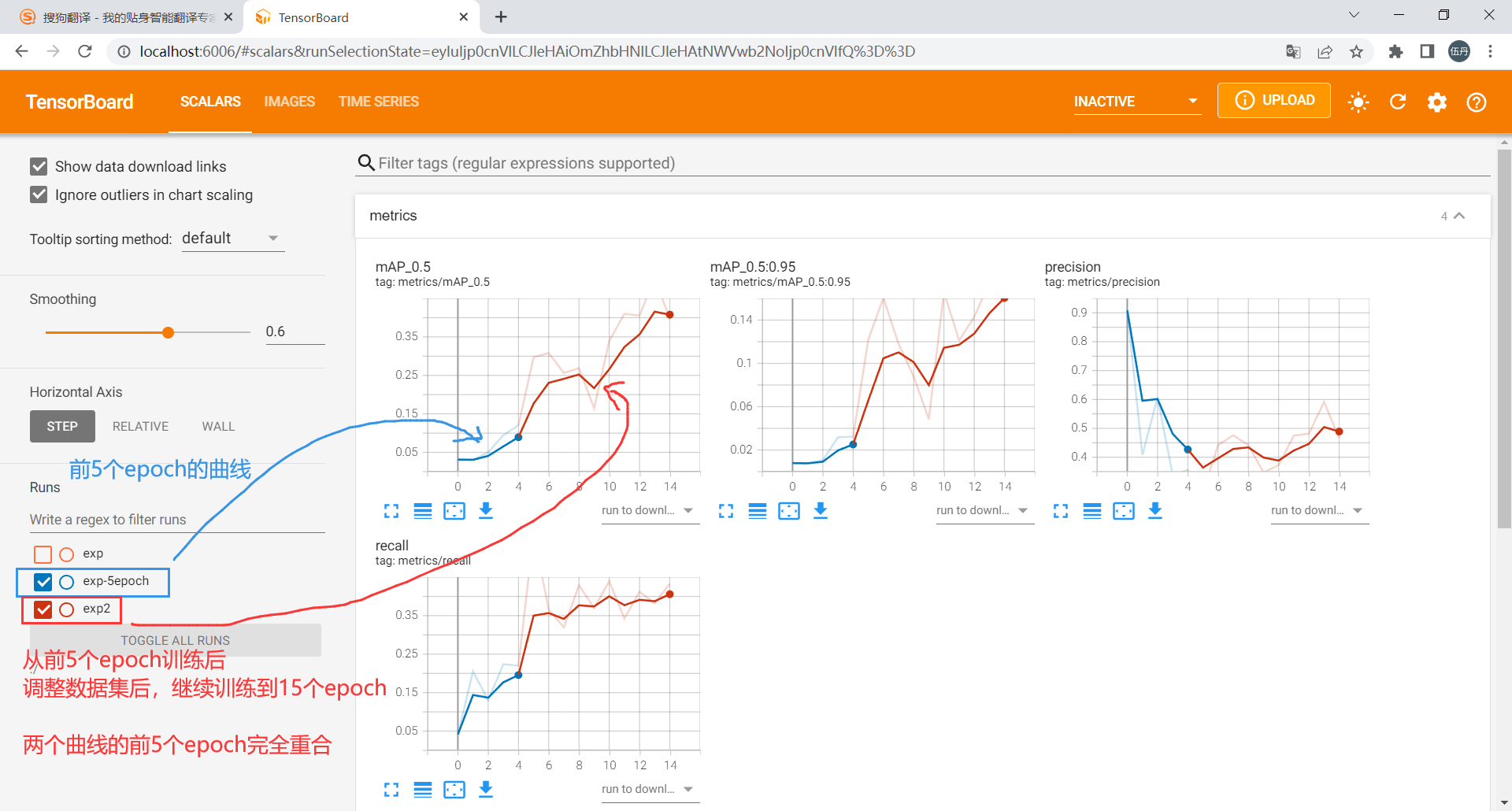
yolov5ds-断点训练、继续训练、先终止训练并调整最终epoch(yolov5同样适用)
目录参考链接1. 训练过程中中断了,继续训练如果觉得数值差不多稳定了,但是距离最终设置的epoch还很远,所以想要停止训练但是又得到yolov5在运行完指定最大epoch后生成的一系列map、混淆矩阵等图2. 训练完原有epoch,但还继续训练&a…...

openCV第一篇
文章目录 前言:计算机眼中的图片 1. 图片的读取与显示 1.1 图片的读取 1.2 显示的图片 1.2.1 显示原始图片 1.2.2 灰度图 1.3 BGR转换成灰度图、RGB 2. 保存图片 3. 视频的读取与显示 4. 截取图像部分 5. 颜色通道提取 6. 边界填充 7. 数值计算 8.…...

基于Python构建机器学习Web应用
目录 一、内容介绍 1.Onnx模型 ①skl2onnx库安装 2.Netron安装 二、模型构建 1.数据加载 2.划分可训练特征与预测标签 3.训练模型 ①第三方库导入 ②数据集划分 ③SVC模型构建 ④精度评价 二、模型转换及可视化 1.参数配置 2.Onnx模型生成 3.可视化模型 四、构…...
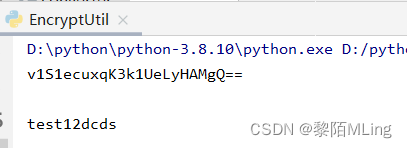
python - 密码加密与解密
Python之密码加密与解密 - 对称算法一、对称加密1.1 安装第三方库 - PyCrypto1.2 加密实现二、非对称加密三、摘要算法3.1 md5加密3.2 sha1加密3.3 sha256加密3.4 sha384加密3.5 sha512加密3.6 “加盐”加密由于计算机软件的非法复制,通信的泄密、数据安全受到威胁。…...
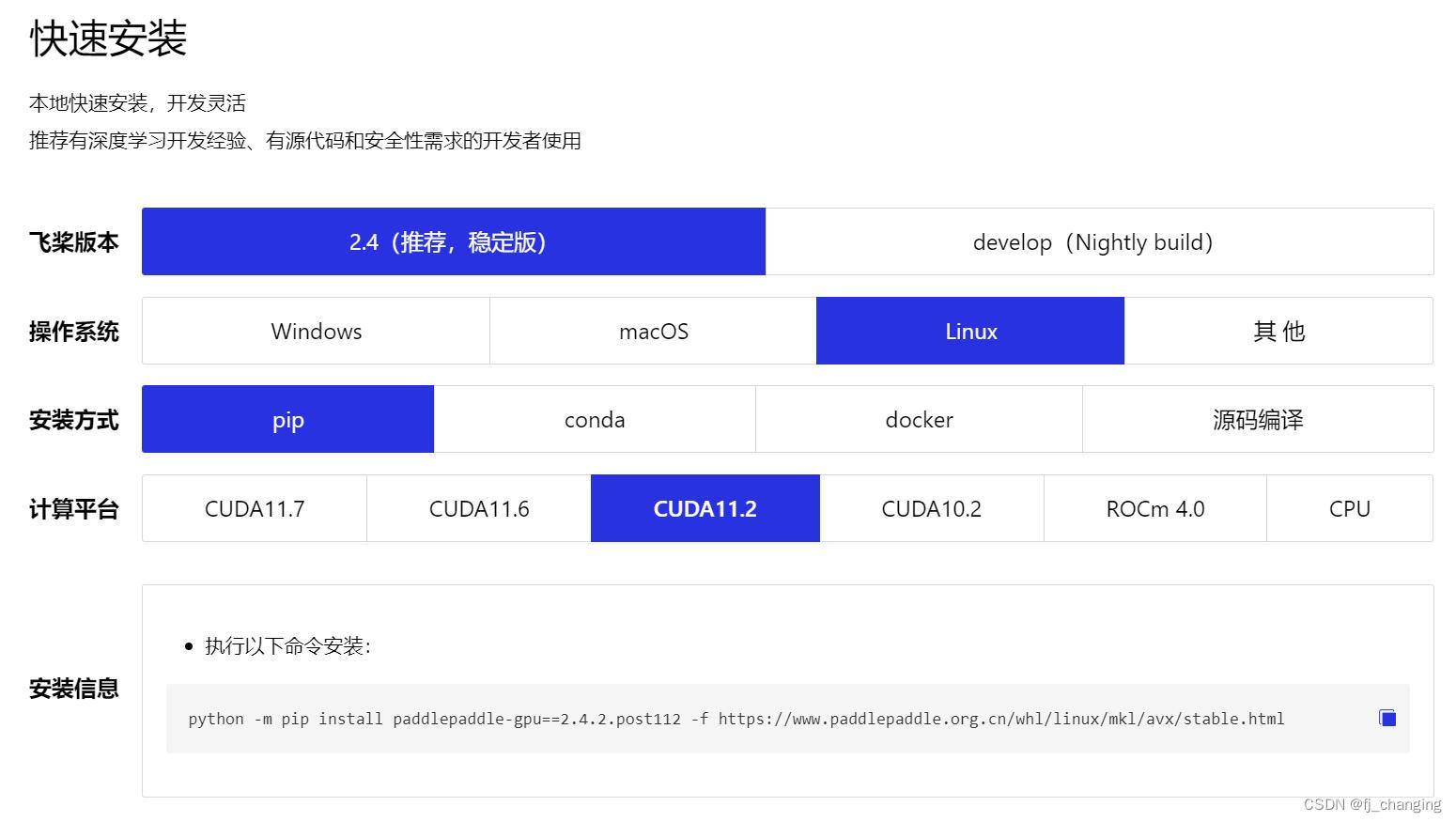
百度飞桨PaddleSpeech的简单使用
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型,一些典型的应用示例如下:语音识别、语音翻译 (英译中)、语音合成、标点恢复等。…...
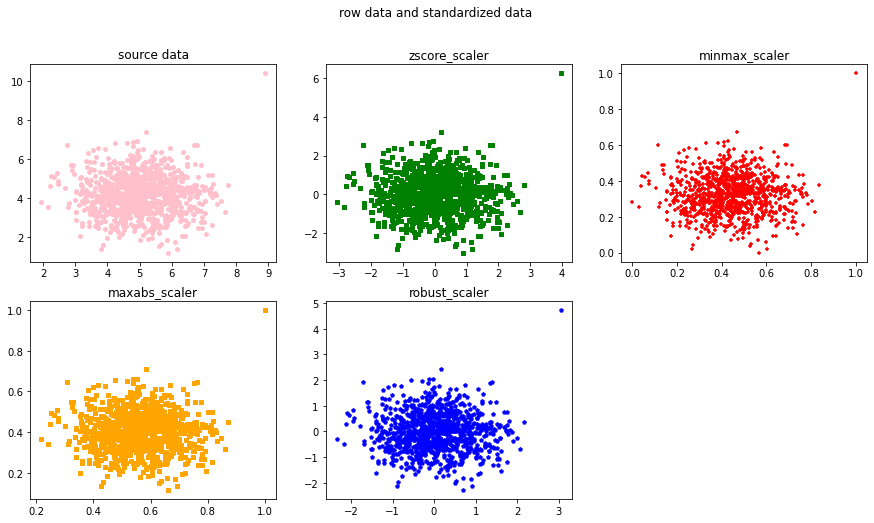
Python数据标准化
目录 一.数据标准化方式 1.实现中心化和正态分布的Z-Score 2.实现归一化的Max-Min 3.用于稀疏数据的MaxAbs 4.针对离群点的RobustScaler 二.Python针对以上几种标准化方法处理数据 三.总结 一.数据标准化方式 1.实现中心化和正态分布的Z-Score Z-Score标准化是基于原…...
Pycharm无法下载汉化包,一招教你搞定
Pycharm无法下载汉化包,一招教你搞定Pycharm直接导入汉化包Pycharm 无法采用自带的插件安装汉化包Pycharm直接导入汉化包 Pycharm 是可以直接导入汉化包的,这为很多初学者省区了不少麻烦。具体就是: 1:点击pycharm界面右上角的设…...

python成功实现“高配版”王者小游戏?【赠源码】
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 本游戏完整源码、素材: 点击此处跳转文末名片获取 咳咳,又是一款新的小游戏,就是大家熟悉的王者~ 来看我用python来实现高(di)配版的王者 是一款拿到代码运行后,…...
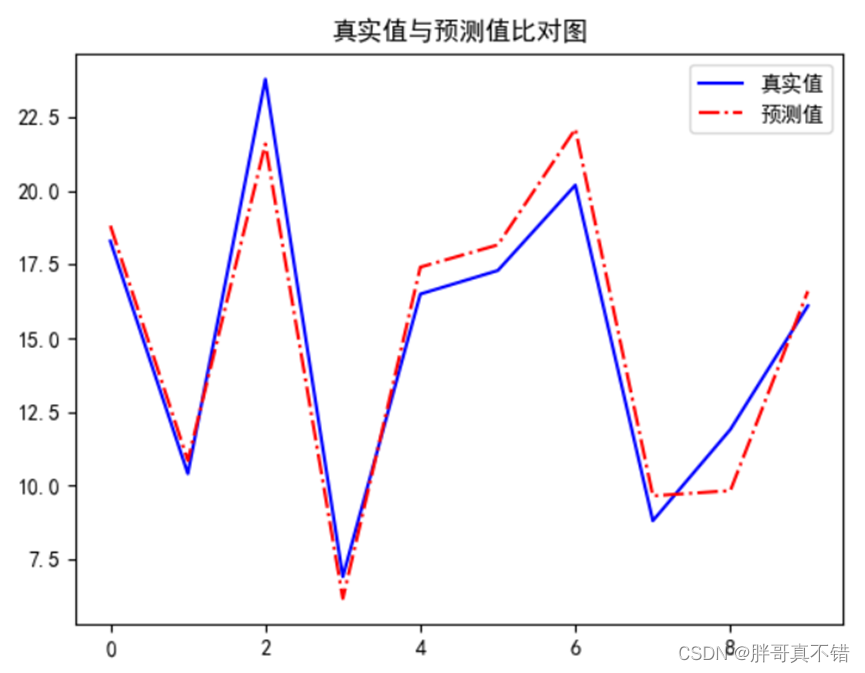
【项目实战】Python实现多元线性回归模型(statsmodels OLS算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 回归问题是一类预测连续值的问题,而能满足这样要求的数学模型称作回归模型,本项…...
graphviz安装教程(2022最新版)初学者适用
1、首先在官网下载graphviz 下载网址:https://www.graphviz.org/download/ 2、安装。 打开第一步已经下载好的软件。点击下一步,在安装路径选择时可将安装路径修改为 D:\graphviz 接着一直点下一步,即可安装完成。 3、配置环境变量 右键…...

【Windows】搭建Pytorch环境(GPU版本,含CUDA、cuDNN),并在Pycharm上使用(零基础小白向)
文章目录前言一、安装CUDA1、检查电脑是否支持CUDA2、下载并安装CUDA3、下载并安装cuDNN二、安装Pytorch1、安装Anaconda2、切换清华镜像源3、创建环境并激活4、输入Pytorch安装命令5、测试三、在Pycharm上使用搭建好的环境参考文章前言 本人纯python小白,第一次使用…...
Tensorflow与CUDA、cudnn版本对应关系
不同版本的Tensorflow需对应不同的CUDA和cudnn版本,否者容易安装失败。可按下图所示,根据想要安装的Tensorflow版本,选择对应版本的CUDA和cudnn。 其中CUDA的下载链接为: CUDA Toolkit Archive | NVIDIA Developer cudnn下载链…...
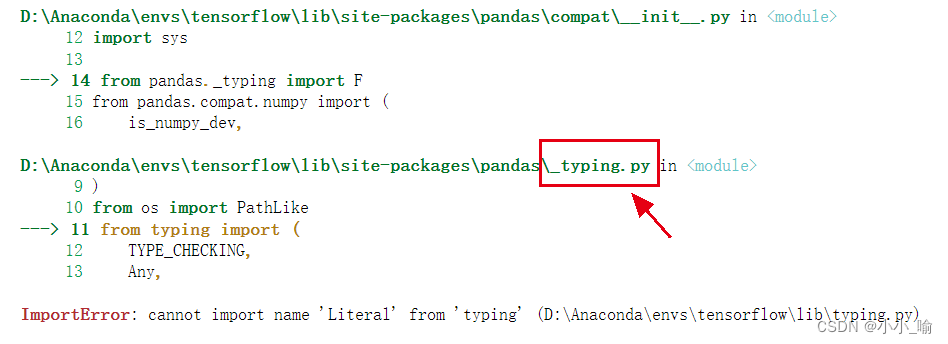
ImportError: cannot import name ‘Literal‘ from ‘typing‘ (D:\Anaconda\envs\tensorflow\lib\typing.py)
报错背景: 因为安装tensorflow-gpu版本需要,我把原来的新建的anaconda环境(我的名为tensorflow)中的python3.8降为了3.7。 在导入seaborn包时,出现了以下错误: ImportError: cannot import name Literal …...

100天精通Python(数据分析篇)——第67天:Pandas数据连接、合并、加入、添加、重构函数(merge、concat、join、append、stack、unstack)
文章目录 一、数据连接(pd.merge)1. left、right2. how3. on4. left_on、right_on5. sort6. suffixes7. left_index、right_index二、数据合并(pd.concat)1. index 没有重复的情况2. index 有重复的情况3. DataFrame合并时同时查看行索引和列索引有无重复三、数据加入(pd.…...
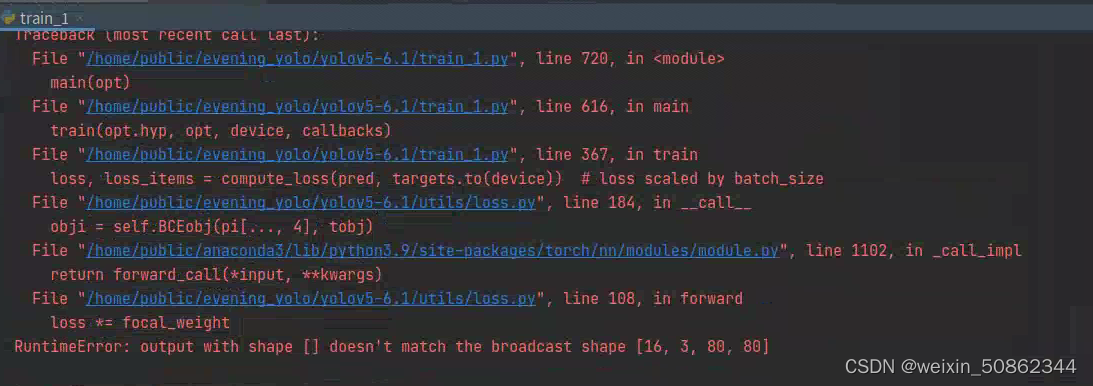
yolov5 优化系列(三):修改损失函数
1.使用 Focal loss 在util/loss.py中,computeloss类用于计算损失函数 # Focal lossg h[fl_gamma] # focal loss gammaif g > 0:BCEcls, BCEobj FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)其中这一段就是开启Focal loss的关键!!&…...
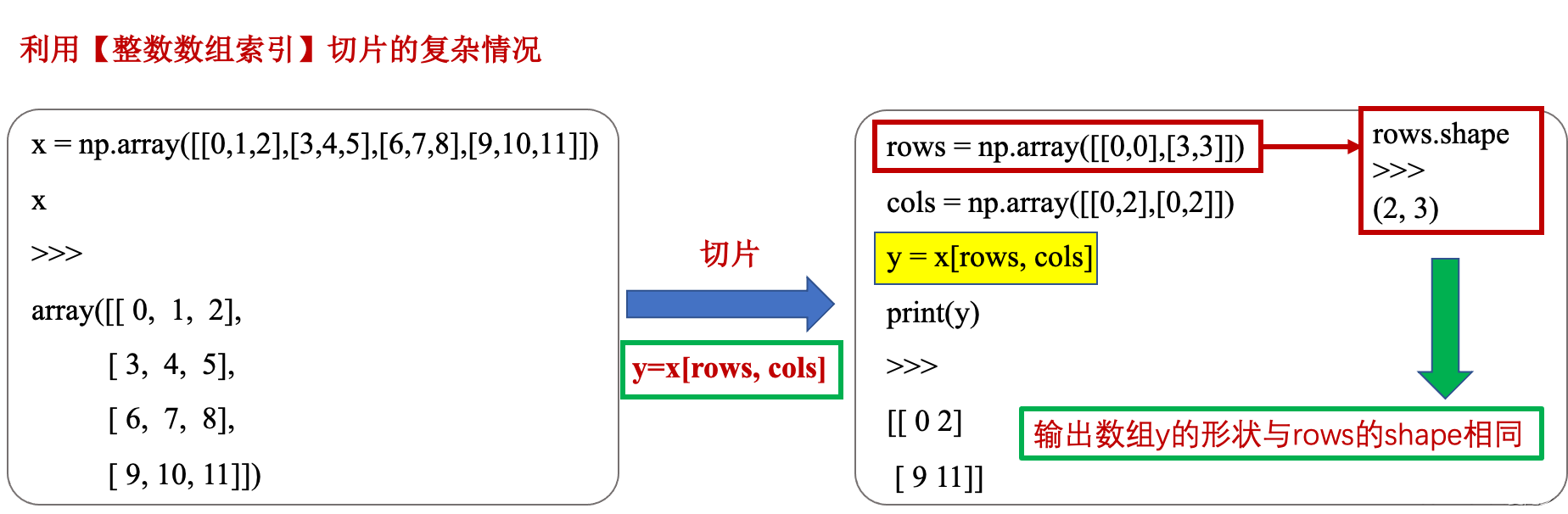
Python中数组切片的用法详解
Python中数组切片的用法详解一、python中“::-1”代表什么?二、python中“:”的用法三、python中数组切片三、numpy中的整数数组索引四、numpy中借助【切片 : 或 …与索引数组】组合进行复杂切片五、布尔索引六、花式索引一、python中“::-1”代表什么? …...
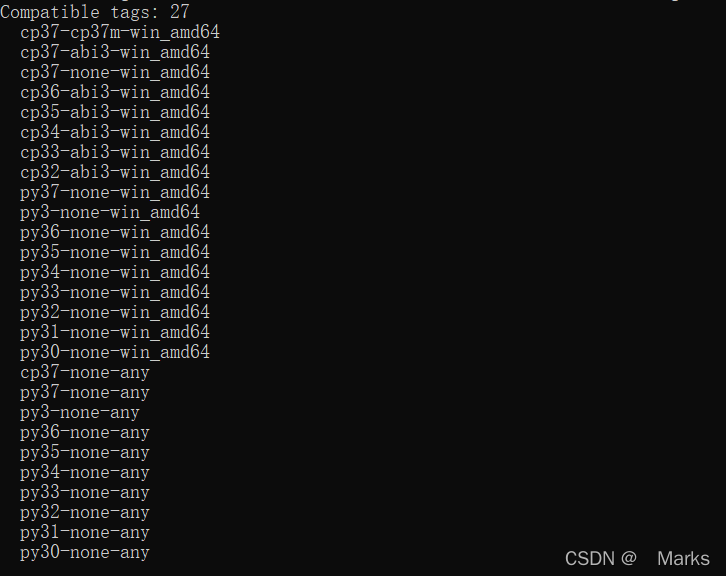
python 安装whl文件
前言 WHL文件是以Wheel格式保存的Python安装包,Wheel是Python发行版的标准内置包格式。在本质上是一个压缩包,WHL文件中包含了Python安装的py文件和元数据,以及经过编译的pyd文件,这样就使得它可以在不具备编译环境的条件下&#…...
Pycharm中安装pytorch
配置虚拟环境 为什么要安装虚拟环境?虚拟环境:把一部分内容独立出来,称之为容器。在容器中,安装我们自己想要的东西,比如不容版本的依赖包。各容器之间相互独立,互不影响。比如下载完 Anaconda 之后&#…...
Package | 解决 module ‘cv2‘ has no attribute ‘gapi_wip_gst_GStreamerPipeline‘
. 问题背景 由于这个问题出现了两回,决定记录一下。实验背景是使用opencv python库进行数据预处理,遇到报错信息如下: “ import cv2 File “/opt/conda/lib/python3.8/site-packages/cv2/init.py”, line 181, in bootstrap() File “/op…...
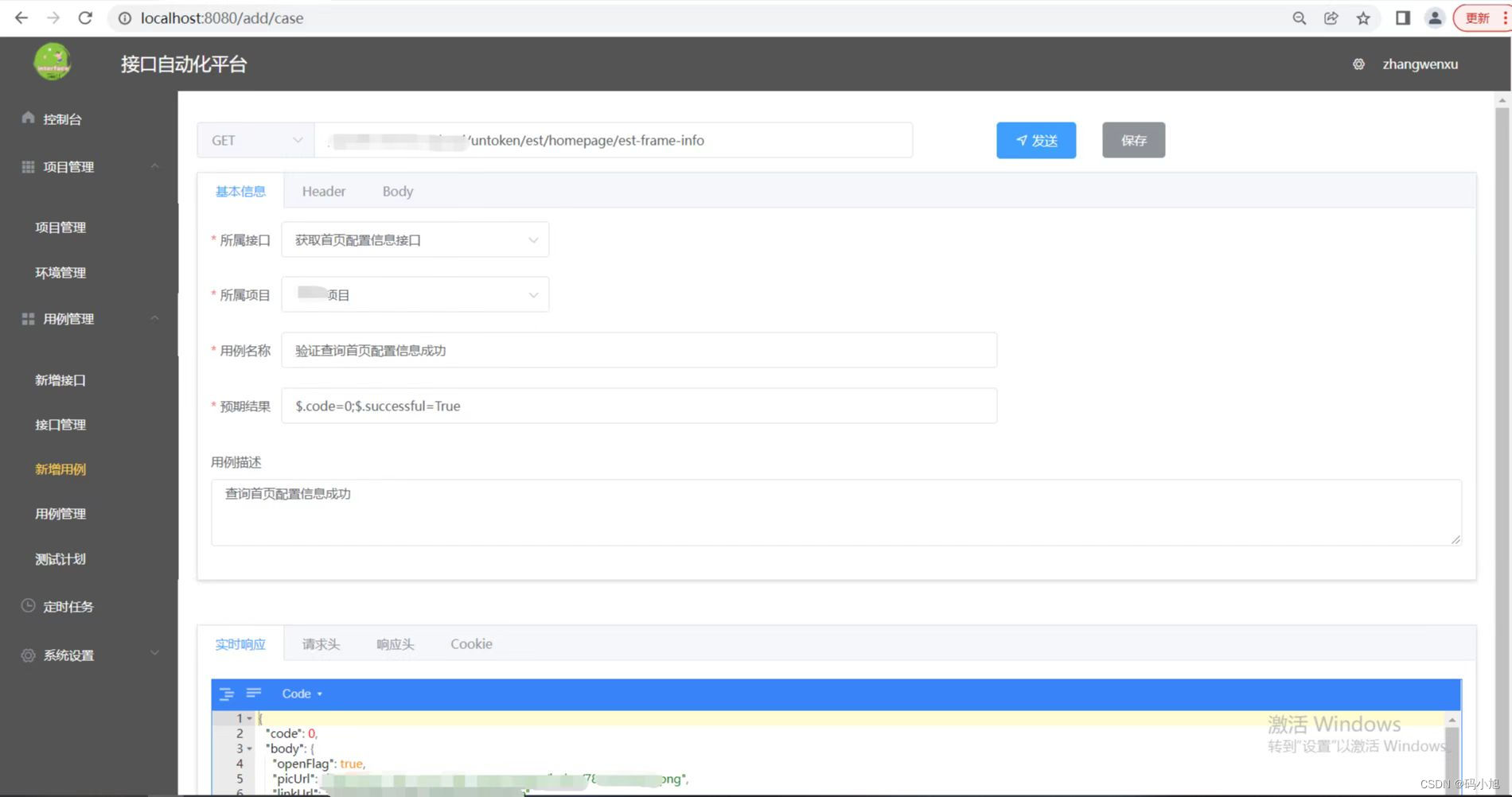
如何在项目中搭建python接口自动化框架?
文章目录前言一、框架目录介绍1、common模块读取Excel代码读取yaml代码(支持场景关联)jsonpath断言封装代码requests二次封装(get、post)configparser读取配置文件递归遍历字典常用方法log日志封装2、conf模块3、data模块4、case模…...
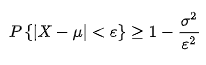
应用统计432考研复试复试提问总结精简版【一】
一、区间估计与假设检验的联系与区别 联系:二者利用样本进行推断,都属于推断统计区别: 原理: 前者是基于大概率,后者基于小概率;统计量:前者是构造枢轴量(不含未知参数,…...
Pytorch模型量化
在深度学习中,量化指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的bit来完成原本以浮点数完成的计算。这么做的好处主要有如下几点: 更少的模型体积,接近4倍的减少;可以更快的计算,由于…...

已解决Encountered error while trying to install package.> lxml
已解决(pip安装第三方模块lxml模块报错)Building wheels for collected packages: lxml Building wheel for lxml (setup.py) … error error: subprocess-exited-with-error python setup.py bdist_wheel did not run successfully. note: This error o…...

距离度量 —— 闵可夫斯基距离(Minkowski Distance)
Python学习系列文章:👉 目录 👈 文章目录一、概述二、计算公式1. 闵氏距离公式2. 闵氏距离的参数 p3. 闵氏距离的缺点一、概述 闵可夫斯基距离 (Minkowski Distance),也被称为 闵氏距离。它不仅仅是一种距离,而是将多…...
python(模块)xlwt
目录一、xlwt简介二、xlwt语法1、模块安装2、模块导入3、向xls文件中写入内容4、设置写入文件的格式4.1 字体设置(font)4.2 背景颜色设置(pattern)4.3 边框设置(borders)4.4 对齐方式设置(align…...

Pytorch中torch.unsqueeze()和torch.squeeze()函数解析
一. torch.squeeze()函数解析 1. 官网链接 torch.squeeze(),如下图所示: 2. torch.squeeze()函数解析 torch.squeeze(input, dimNone, outNone) squeeze()函数的功能是维度压缩。返回一个tensor(张量),其中 input…...
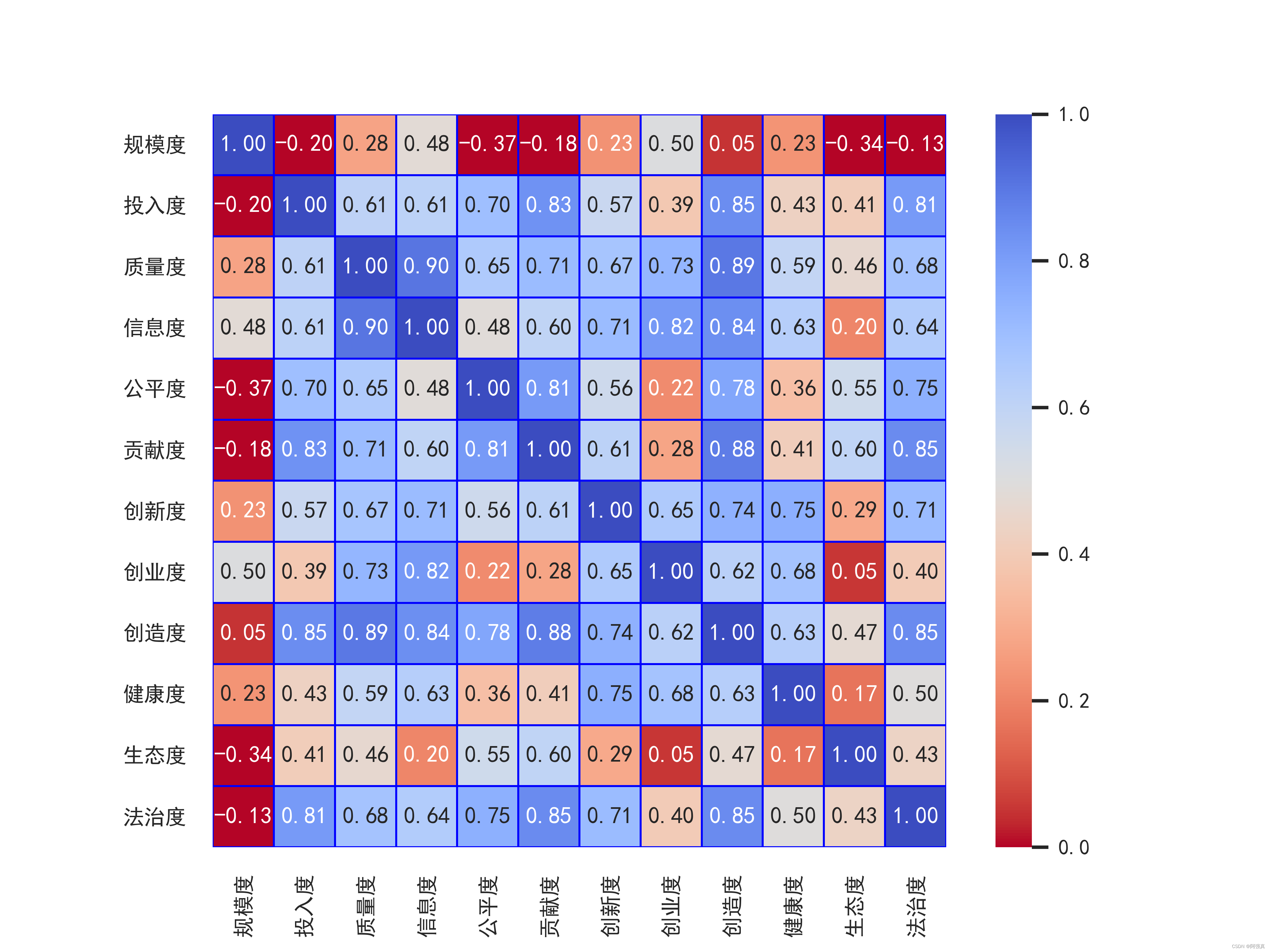
python绘制相关系数热力图
python绘制相关系数热力图一.数据说明和需要安装的库二.准备绘图三.设置配色,画出多幅图全部代码:本文讲述如何利用python绘制如上的相关系数热力图一.数据说明和需要安装的库 数据是31个省市有关教育的12个指标,如下所示。,在文…...
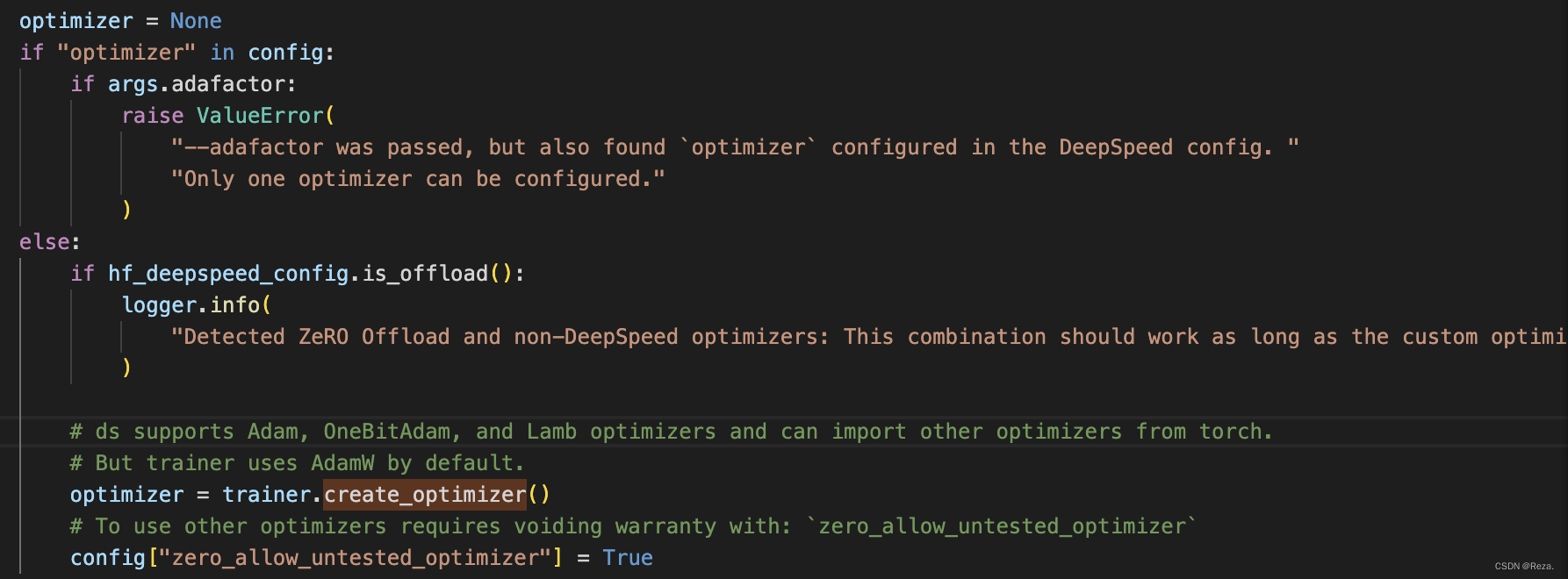
DeepSpeed使用指南(简略版)
现在的模型越来越大,动辄几B甚至几百B。但是显卡显存大小根本无法支撑训练推理。例如,一块RTX2090的10G显存,光把模型加载上去,就会OOM,更别提后面的训练优化。 作为传统pytorch Dataparallel的一种替代,D…...
【Python】tqdm 介绍与使用
文章目录一、tqdm 简介二、tqdm 使用1. 基于迭代对象运行: tqdm(iterator)2. tqdm(list)3. trange(i)4. 手动更新参考链接一、tqdm 简介 tqdm 是一个快速,可扩展的 Python 进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装…...
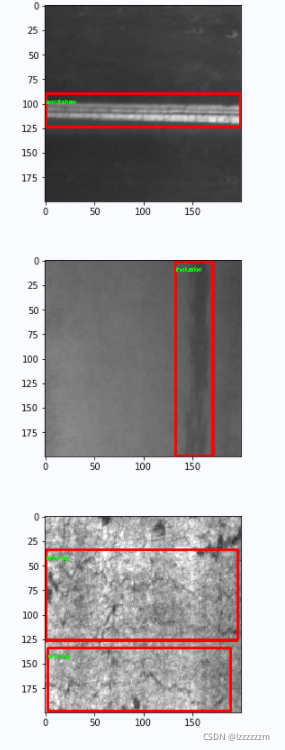
Pytorch机器学习(十)—— 目标检测中k-means聚类方法生成锚框anchor
Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 目录 Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 前言 一、K-means聚类 k-means代码 k-means算法 二、YOLO中使用k-means聚类生成anchor 读取VO…...
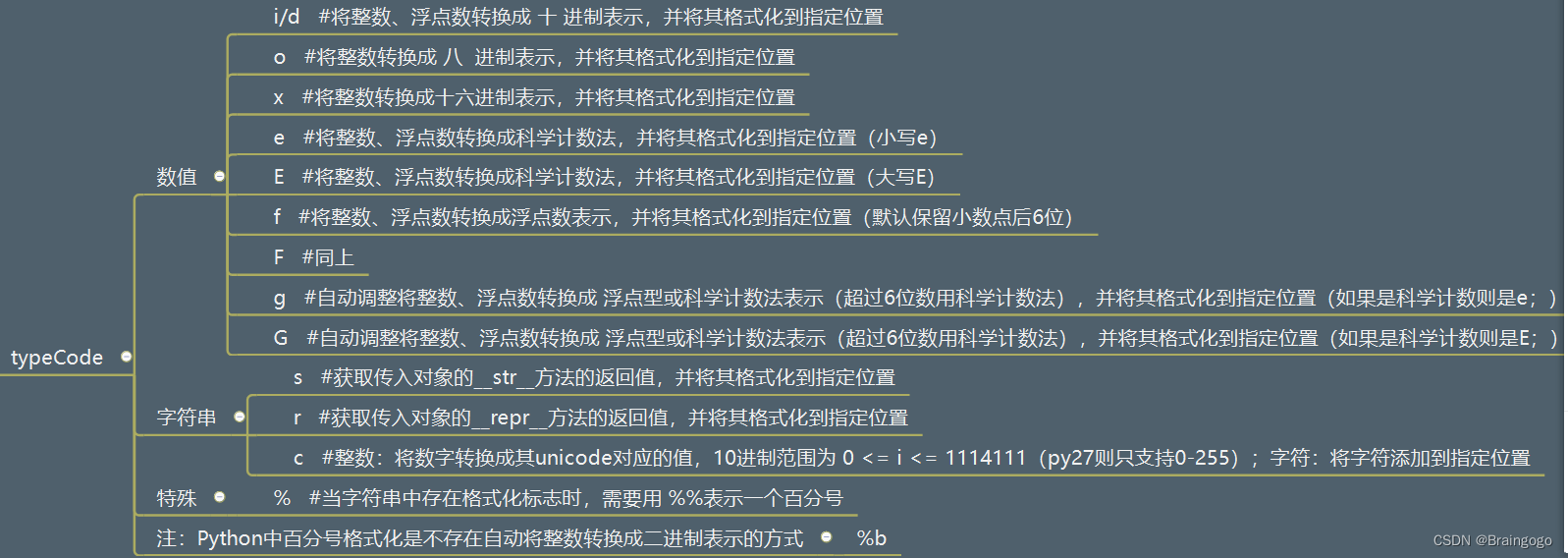
Python的占位格式符
对于print函数里的语句 print("我的名字是%s, 年龄是%d"%(name, age)) 中的%s和%d叫做占位符,它们的完整形态是 %[(name)][flags][width][.precision]typecode 其中带有[]的前缀都是可以省略的。 [(name)]: (name)表示, 根据, 制定的名称(…...
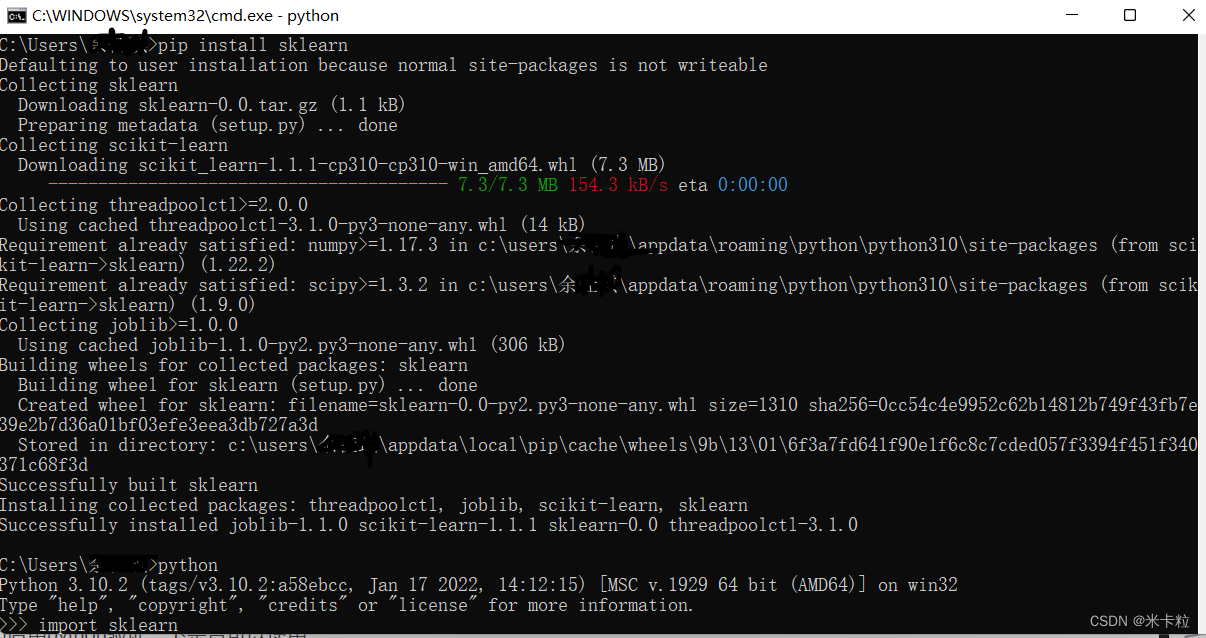
关于sklearn库的安装
对于安装sklearn真的是什么问题都被我遇到了 例如pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(hostfiles.pythonhosted.org, port443): Read timed out.遇到了 这种也遇到了Requirement already satisfied: numpy in c:\users\yjq\appdata\roamin…...
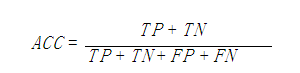
accuracy_score函数
1.acc计算原理 sklearn中accuracy_score函数计算了准确率。 在二分类或者多分类中,预测得到的label,跟真实label比较,计算准确率。 在multilabel(多标签问题)分类中,该函数会返回子集的准确率。如果对于一…...
怎么成为稚晖君?
如何成为IT大佬稚晖君——电子系统设计应具备的基本技能和方法论 快速提高电子技术的必经之路_一些老生常谈的道理 嵌入式AI入坑经历 稚晖君软件硬件开发环境总结 首先,机器学习深度学习这些和硬件是两个领域的内容,个人不建议一起学,注意力…...

Pandas库
Pandas是python第三方库,提供高性能易用数据类型和分析工具。Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用。pandas库引用: import pandas as pd 包括两个数据类型:Series(相当于一维数据类型)&…...

通过两道一年级数学题反思自己
背景 做完这两道题我开始反思自己,到底是什么限制了我?是我自己?是曾经教导我的老师?还是我的父母? 是考试吗?还是什么? 提目 1、正方体个数问题 2、相碰可能性 过程 静态思维: …...
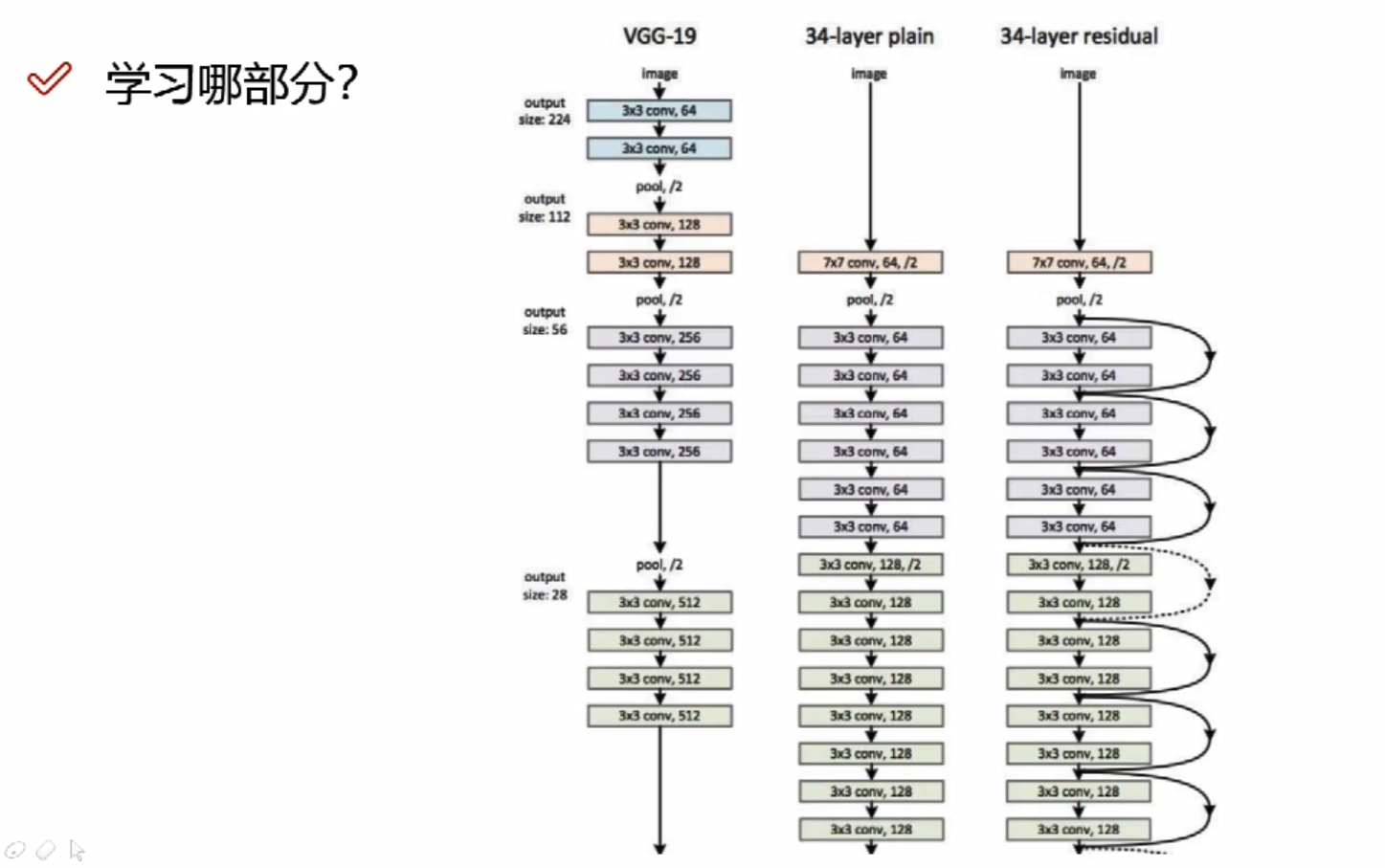
深度学习—卷积神经网络(CNN)全笔记,附代码
本文内容为哔站学习笔记【卷积神经网络-CNN】深度学习(唐宇迪带你学AI):卷积神经网络理论详解与项目实战,计算机视觉,图像识别模块实战_哔哩哔哩_bilibili 目录 深度学习基础 什么是深度学习? 机器学习流…...
Building wheel for mmcv-full (setup.py) ... error解决办法!
mmdetection 安装后,根据官方给的程序安装mmcv时,出现:Building wheel for mmcv-full (setup.py) … error 环境:CUDA11.3, Pytorch1.11 安装根据官网给的安装程序:pip install mmcv-full -f https://download.openmm…...
联邦学习开山之作代码解读与收获
参考:联邦学习代码解读,超详细_一只揪的博客-CSDN博客_联邦学习代码 参考文献:[1602.05629] Communication-Efficient Learning of Deep Networks from Decentralized Data (arxiv.org) 参考代码:GitHub - AshwinRJ/Federated-L…...
Python安装第三方库常用方法 超详细~
Python安装第三方库常用方法前言安装方法1. 通过pychram安装2. pip安装大法3. 下载whl文件到本地离线安装3.1 补充4.其他方法4.1 Python官方的Pypi菜单4.2 国内镜像源解决pip安装过慢的问题小结前言 在pyhton的学习中,相信大家通常都会碰到第三方库的安装问题&…...
Python--找出字符串中出现次数最多的字符及其出现的次数
方法一: 1、循环遍历列表或字符串,如果字符在字典中则值加1,如果不在则创建(key,value) 2、找到字典中,最大的value值 3、根据最大的value值,找对应的key值,打印出出现次数最多的字符 str &qu…...

滤波笔记一:卡尔曼滤波(Kalman Filtering)详解
本笔记是总结了B站DR_CAN的卡尔曼滤波器的课程,他的B站主页为:DR_CAN的个人空间_哔哩哔哩_bilibili PS:虽然我不是学自控的,但是老师真的讲的很好! 目录 Lesson1 递归算法 Lesson2 数学基础_数据融合_协方差矩阵_状态空间方程…...
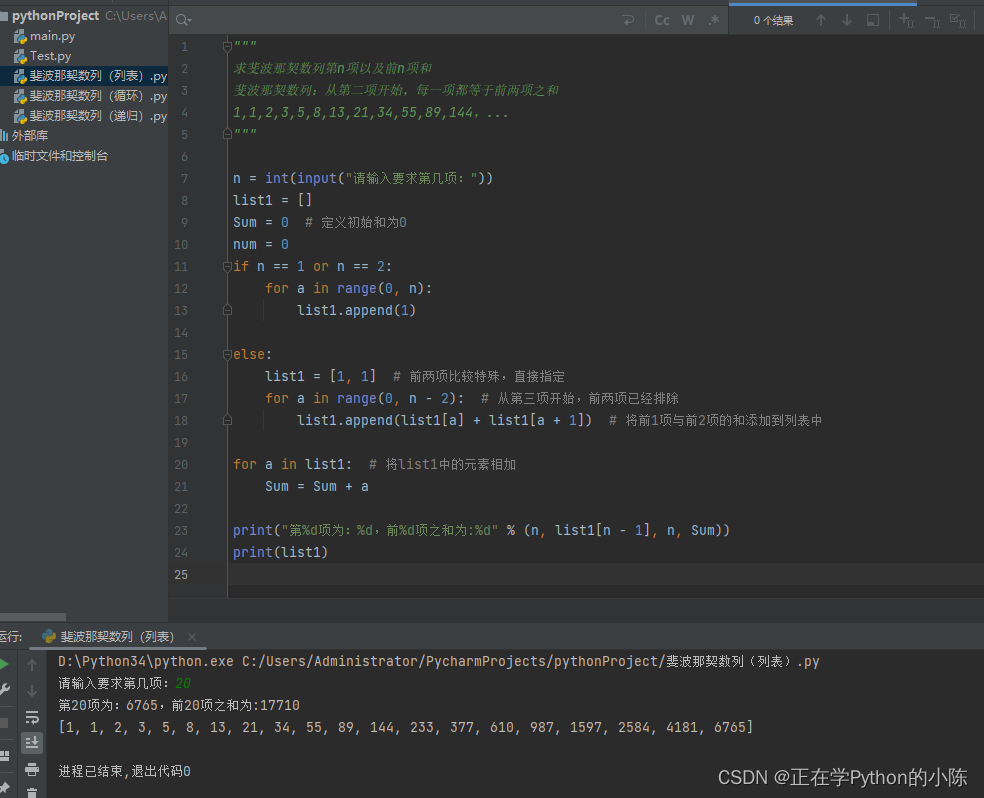
利用Python求斐波那契数列的第N项以及前N项和(循环、递归、集合)
著名的斐波那契数列,即从第三项开始,每一项都等于前两项之和。 之前写过利用Java语言来编写,由于最近正在学Python,所以将自己的想法记录在此,有需要的朋友可以参考一下。 写在前面:这里的三个方法其实思…...