PyTorch 单机多GPU 训练方法与原理整理
PyTorch 单机多GPU 训练方法与原理整理
这里整理一些PyTorch单机多核训练的方法和简单原理,目的是既能在写代码时知道怎么用,又能从原理上知道大致是怎么回事儿。
就目前来说,并行训练的方法可以根据的不同的并行对象分为——模型并行和数据并行。
模型并行:是网络太大,一张卡存不了,那么拆分,然后进行模型并行训练。
数据并行:多个显卡同时采用数据训练网络的副本。在这里仅先讨论数据并行。
PyTorch单机多核训练方案有两种:一种是利用nn.DataParallel实现,实现简单,不涉及多进程;另一种是用torch.nn.parallel.DistributedDataParallel和torch.utils.data.distributed.DistributedSampler结合多进程实现。第二种方式效率更高,但是实现起来稍难,第二种方式同时支持多节点分布式实现。方案二的效率要比方案一高,即使是在单运算节点上。
并行数据加载
先介绍一下数据并行的概念。
目前流行的深度学习框架(例如Pytorch和Tensorflow)为分布式培训提供内置支持。从广义上讲,从磁盘读取输入数据开始,加载数据涉及四个步骤:
- 将数据从磁盘加载到主机;
- 将数据从可分页内存传输到主机上的固定内存;
- 将数据从固定内存传输到GPU;
- 在GPU上向前和向后传递;
PyTorch 中的 Dataloader方法 提供使用多个进程(通过将 num_workers> 0 设置)从磁盘加载数据以及将多页数据从可分页内存到固定内存的能力(通过设置 pin_memory = True)。
一般的,对于大批量的数据,若仅有一个线程用于加载数据,则数据加载时间占主导地位,这意味着无论我们如何加快数据处理速度,性能都会受到数据加载时间的限制。现在,设置num_workers = 4(这四个进程是四个独立的进程) 以及 pin_memory = True。这样,可以使用多个进程从磁盘读取不重叠的数据,并启动生产者-消费者线程以将这些进程读取的数据从可分页的内存转移到固定的内存。
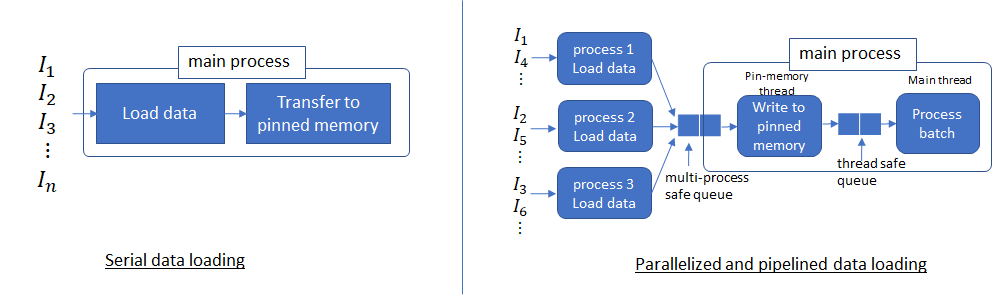
多个进程能够更快地加载数据,并且当数据处理时间足够长时,流水线数据加载几乎可以完全隐藏数据加载延迟。这是因为在处理当前批次的同时,将从磁盘读取下一个批次的数据,并将其传输到固定内存。如果处理当前批次的时间足够长,则下一个批次的数据将立即可用。这个想法需要为num_workers 参数设置适当的值。设置此参数,以使从磁盘读取批处理数据的速度比GPU处理当前批处理的速度更快(但不能更高,因为这只会浪费多个进程使用的系统资源)。
接下来将介绍具体的实现方法,为了方便理解,这里用一个简单的CNN模型训练MNIST手写数据集,相关代码:
- model.py:定义一个简单的CNN网络
- data.py:MNIST训练集和数据集准备
- single_gpu_train.py:单GPU训练代码
方案一
核心在于使用nn.DataParallel将模型wrap一下,代码其他地方不需要做任何更改:
model = nn.DataParallel(model)
为方便说明,我们假设模型输入为(32, input_dim),这里的 32 表示batch_size,模型输出为(32, output_dim),使用 4 个GPU训练。nn.DataParallel起到的作用是将这 32 个样本拆成 4 份,发送给 4 个GPU 分别做 forward,然后生成 4 个大小为(8, output_dim)的输出,然后再将这 4 个输出都收集到cuda:0上并合并成(32, output_dim)。
详细流程:
forward:是将输入一个 batch 的数据均分成多份,分别送到对应的 GPU 进行计算。与 Module 相关的所有数据也都会以浅复制的方式复制多份。每个 GPU 在单独的线程上将针对各自的输入数据独立并行地进行 forward 计算。
backward:在主GPU上收集网络输出,并通过将网络输出与批次中每个元素的真实数据标签进行比较来计算损失函数值。接下来,损失值分散给各个GPU,每个GPU进行反向传播以计算梯度。最后,在主GPU上归约梯度、进行梯度下降,并更新主GPU上的模型参数。由于模型参数仅在主GPU上更新,而其他从属GPU此时并不是同步更新的,所以需要将更新后的模型参数复制到剩余的从属 GPU 中,以此来实现并行。
DataParallel会将定义的网络模型参数默认放在GPU 0上,所以dataparallel实质是可以看做把训练参数从GPU拷贝到其他的GPU同时训练,这样会导致内存和GPU使用率出现很严重的负载不均衡现象,即GPU 0的使用内存和使用率会大大超出其他显卡的使用内存,因为在这里GPU0作为master来进行梯度的汇总和模型的更新,再将计算任务下发给其他GPU,所以他的内存和使用率会比其他的高。
具体流程见下图:

可以看出,nn.DataParallel没有改变模型的输入输出,因此其他部分的代码不需要做任何更改,非常方便。但弊端是,后续的loss计算只会在cuda:0上进行,没法并行,因此会导致负载不均衡的问题。
如果把loss放在模型里计算的话,则可以缓解上述负载不均衡的问题,示意代码如下:
class Net:
def __init__(self,...):
# code
def forward(self, inputs, labels=None)
# outputs = fct(inputs)
# loss_fct = ...
if labels is not None:
loss = loss_fct(outputs, labels) # 在训练模型时直接将labels传入模型,在forward过程中计算loss
return loss
else:
return outputs
按照我们上面提到的模型并行逻辑,在每个GPU上会计算出一个loss,这些loss会被收集到cuda:0上并合并成长度为 4 的张量。这个时候在做backward的之前,必须对将这个loss张量合并成一个标量,一般直接取mean就可以。这在Pytorch官方文档nn.DataParallel函数中有提到:
When
modulereturns a scalar (i.e., 0-dimensional tensor) in forward(), this wrapper will return a vector of length equal to number of devices used in data parallelism, containing the result from each device.
这部分的例子可以参考:data_parallel_train.py
Note: DataParallel 中,batch size 设置必须为单卡的 n 倍,因为一个batch的数据会被主GPU分散为minibatch给其他GPU,但是在 DistributedDataParalle(方案二) 内,batch size 设置于单卡一样即可,因为各个GPU对应的进程独立从磁盘中加载数据,训练所设置的batch size就是每一个进程的batch size。
方案二(推荐)
方案二被成为分布式数据并行(distributed data parallel),是通过多进程实现(parallel.DistributedDataParallel)的,相比与方案一要复杂很多。可以从以下几个方面理解:
-
从一开始就会启动多个进程(进程数等于GPU数),每个进程独享一个GPU,每个进程都会独立地执行代码。这意味着每个进程都独立地初始化模型、训练,当然,在每次迭代过程中会通过进程间通信共享梯度,整合梯度,然后独立地更新参数。
-
每个进程都会初始化一份训练数据集,当然它们会使用数据集中的不同记录做训练,这相当于同样的模型喂进去不同的数据做训练,也就是所谓的数据并行。这是通过
torch.utils.data.distributed.DistributedSampler函数实现的,不过逻辑上也不难想到,只要做一下数据partition,不同进程拿到不同的parition就可以了,官方有一个简单的demo,感兴趣的可以看一下代码实现:Distributed Training -
进程通过
local_rank变量来标识自己,local_rank为0的为master,其他是slave。这个变量是torch.distributed包帮我们创建的,使用方法如下:import argparse # 必须引入 argparse 包 parser = argparse.ArgumentParser() parser.add_argument("--local_rank", type=int, default=-1) args = parser.parse_args()必须以如下方式运行代码:
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 train.py这样的话,
torch.distributed.launch就以命令行参数的方式将args.local_rank变量注入到每个进程中,每个进程得到的变量值都不相同。比如使用 4 个GPU的话,则 4 个进程获得的args.local_rank值分别为0、1、2、3。上述命令行参数
nproc_per_node表示每个节点需要创建多少个进程(使用几个GPU就创建几个);nnodes表示使用几个节点,因为我们是做单机多核训练,所以设为1。Note:
- 最新的pytorch提示,改为了torchrun,以单机多卡为例,启动方式为(更简单):
torchrun --standalone --nnodes=1 --nproc_per_node=4 train.py # --nnodes表示为物理节点数量 # --nproc_per_node表示为GPU数量-
torch.distributed.launch还有两个参数比较容易弄混,分别是**
rank和local_rank**.rank: 表现当前进程的序号,用于进程间通讯,表征进程优先级。rank = 0的主机为master节点。同时,rank=0的进程就是master进程,其可以通过如下的方式获取:
# 获取rank,每个进程都有自己的序号,各不相同 torch.distributed.get_rank()-
local_rank:这是每台机子上的进程的序号,进程内,GPU编号,非显式参数,由torch.distributed.launch内部指定。比方说,rank = 3,local_rank = 0表示第3个进程内的第1块GPU。获取方式如下:# 获取local_rank。一般情况下,你需要用这个local_rank来手动设置当前模型 #是跑在当前机器的哪块GPU上面的。 torch.distributed.local_rank() -
举个栗子 :4台机器(每台机器8张卡)进行分布式训练
通过 init_process_group() 对进程组进行初始化
初始化后 可以通过 get_world_size() 获取到 world_size
在该例中为32, 即有32个进程,其编号为0-31,即rank的取值范围, 可以通过 get_rank() 函数可以进行获取。 在每台机器上,local rank均为0-8,这是 local_rank 与 rank 的区别, local_rank 会对应到实际的 GPU ID 上
(单机多任务的情况下注意CUDA_VISIBLE_DEVICES的使用
控制不同程序可见的GPU devices)
-
与 nn.DataParallel分发数据的方式不同,parallel.DistributedDataParallel的batch_size是不进行整除的,也即是你设置了BS是多少,每个进程(GPU)的BS就是多少,但是其会对数据进行划分(第一个维度)。
举个例子来说:我们假设模型输入为(32, input_dim),数据集大小为12000,有4块GPU,那么每块GPU上的BS大小为32,数据集大小为12000/32=375/4=93.74,近似为94。12000/32是说明,按照BS等于32来划分,总共有375个input,又因为有4块GPU,因此每块GPU的input的数量为94.
-
因为每个进程都会初始化一份模型,为保证模型初始化过程中生成的随机权重相同,需要设置随机种子。方法如下:
def set_seed(seed): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed_all(seed)
使用方法通过如下示意代码展示:
from torch.utils.data.distributed import DistributedSampler # 负责分布式dataloader创建,也就是实现上面提到的partition。
# 负责创建 args.local_rank 变量,并接受 torch.distributed.launch 注入的值
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int, default=-1)
args = parser.parse_args()
# 每个进程根据自己的local_rank设置应该使用的GPU
torch.cuda.set_device(args.local_rank)
device = torch.device('cuda', args.local_rank)
# 初始化分布式环境,主要用来帮助进程间通信
torch.distributed.init_process_group(backend='nccl')
# 固定随机种子
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# 初始化模型
model = Net()
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 只 master 进程做 logging,否则输出会很乱
if args.local_rank == 0:
tb_writer = SummaryWriter(comment='ddp-training')
# 分布式数据集
train_sampler = DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, sampler=train_sampler, batch_size=batch_size) # 注意这里的batch_size是每个GPU上batch_size
# 分布式模型
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True)
详细代码参考:ddp_train.py
对比DataParallel,DistributedDataParallel的区别和优势如下
区别:DDP通过多进程实现的。也就是说操作系统会为每个GPU创建一个进程,从而避免了Python解释器GIL带来的性能开销。而DataParallel()是通过单进程控制多线程来实现的。
优势:
1、每个进程对应一个独立的训练过程,且只对梯度等少量数据进行信息交换。
在每次迭代中,每个进程具有自己的 optimizer ,并独立完成所有的优化步骤,进程内与一般的训练无异。
在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由 rank=0 的进程,将其 broadcast 到所有进程。之后,各进程用该梯度来独立的更新参数。(而 DataParallel是梯度汇总到gpu0,反向传播更新参数,再广播模型参数给其他的gpu) 由于各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。
而在 DataParallel 中,全程维护一个 optimizer,对各 GPU 上梯度进行求和,而在主 GPU 进行参数更新,之后再将模型参数 broadcast 到其他 GPU。
相较于 DataParallel,torch.distributed 传输的数据量更少,因此速度更快,效率更高。
2、每个进程包含独立的解释器和 GIL。
一般使用的Python解释器CPython:是用C语言实现Pyhon,是目前应用最广泛的解释器。全局锁使Python在多线程效能上表现不佳,全局解释器锁(Global Interpreter Lock)是Python用于同步线程的工具,使得任何时刻仅有一个线程在执行。
由于每个进程拥有独立的解释器和 GIL,消除了来自单个 Python 进程中的多个执行线程,模型副本或 GPU 的额外解释器开销和 GIL-thrashing ,因此可以减少解释器和 GIL 使用冲突。这对于严重依赖 Python runtime 的 models 而言,比如说包含 RNN 层或大量小组件的 models 而言,这尤为重要。
3、为什么尽管增加了复杂性,但还是考虑使用DistributedDataParallel而不是DataParallel:
如果模型太大而无法容纳在单个 GPU 上,则必须使用模型并行将其拆分到多个 GPU 中。 DistributedDataParallel与模型并行一起使用; DataParallel目前没有。
DataParallel是单进程,多线程,并且只能在单台机器上运行,而DistributedDataParallel是多进程,并且适用于单机和多机训练。 因此,即使在单机训练中,数据足够小以适合单机,DistributedDataParallel仍比DataParallel快。 DistributedDataParallel还预先复制模型,而不是在每次迭代时复制模型,并避免了全局解释器锁定。
如果您的两个数据都太大而无法容纳在一台计算机和上,而您的模型又太大了以至于无法安装在单个 GPU 上,则可以将模型并行(跨多个 GPU 拆分单个模型)与DistributedDataParallel结合使用。 在这种情况下,每个DistributedDataParallel进程都可以并行使用模型,而所有进程都将并行使用数据。
ddp有用的技巧
官方推荐使用方案二(ddp),所以这里收集ddp使用过程中的一些技巧。
set_epoch
set是在ddp过程中需要考虑的打乱数据顺序的,要不然每次epoch的数据顺序都是相同的,官方给出的回答描述如下:
In distributed mode, calling the
set_epoch()method at the beginning of each epoch before creating theDataLoaderiterator is necessary to make shuffling work properly across multiple epochs. Otherwise, the same ordering will be always used.
使用方法很简单,只需要在input之间添加该方法就可以了:
sampler = DistributedSampler(dataset) if is_distributed else None
loader = DataLoader(dataset, shuffle=(sampler is None),
sampler=sampler)
for epoch in range(start_epoch, n_epochs):
if is_distributed:
sampler.set_epoch(epoch)
train(loader)
torch.distributed.barrier
在读huggingface/transformers中的源码,比如examples/run_ner.py会看到一下代码:
# Load pretrained model and tokenizer
if args.local_rank not in [-1, 0]:
torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
# 这里有一点值得注意,不同进程的 barrier 实际上是互相对应的,必须所有进程都执行一次barrier,才会重新放行正常前进。
args.model_type = args.model_type.lower()
config_class, model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
config = config_class.from_pretrained(args.config_name if args.config_name else args.model_name_or_path,
num_labels=num_labels,
cache_dir=args.cache_dir if args.cache_dir else None)
tokenizer = tokenizer_class.from_pretrained(args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
do_lower_case=args.do_lower_case,
cache_dir=args.cache_dir if args.cache_dir else None)
model = model_class.from_pretrained(args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
cache_dir=args.cache_dir if args.cache_dir else None)
if args.local_rank == 0:
torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
上述代码要实现预训练模型的下载和读入内存,如果4个进程都分别下载一遍显然是不合理的,那如何才能实现只让一个进程下载呢?这个时候就可以使用barrier函数。当slave进程(local_rank!=0)运行到第一个if时就被barrier住了,只能等着,但master进程可以往下运行完成模型的下载和读入内存,但在第二个if语句时遇到barrier,那会不会被barrier住呢?答案是不会,因为master进程和slave进程集合在一起了(barrier),barrier会被解除,这样大家都往下执行。当然这时大家执行的进度不同,master进程已经执行过模型读入,所以从第二个if往下执行,而slave进程尚未执行模型读入,只会从第一个if往下执行。
可以看到barrier类似一个路障,进程会被拦住,直到所有进程都集合齐了才放行。适合这样的场景:只一个进程下载,其他进程可以使用下载好的文件;只一个进程预处理数据,其他进程使用预处理且cache好的数据等。
这里我遇到了一个大问题,就是比如我们想要做单一设备上的预测,不通过分布式的方法来预测,那么通过
torch.distributed.barrier方法时,就会出现所有进程卡住。虽然此时的GPU占用率是100%,但是没有任何程序在正常运行,不过在我找了好多博客之后,终于在Github上发现了类似的问题Using torch.distributed.barrier() makes the whole code hang。这里的方法简单来说,就是将原来的model(**input)用model.module(**input)来代替即可。至于为什么咱也不清楚😭。
同样还有其他方法——使用
no_grad()方法:# validate the model if gpu==0 : with torch.no_grad(): model.eval() for data, target in valid_loader: if torch.cuda.is_available: data, target = data.cuda(), target.cuda() output = model(data) loss = criterion(output, target) valid_loss += loss.item()*data.size(0)
模型保存
模型的保存与加载,与单GPU的方式有所不同。这里通通将参数以cpu的方式save进存储, 因为如果是保存的GPU上参数,pth文件中会记录参数属于的GPU号,则加载时会加载到相应的GPU上,这样就会导致如果你GPU数目不够时会在加载模型时报错,像下面这样:
RuntimeError: Attempting to deserialize object on CUDA device 1 but torch.cuda.device_count() is 1. Please use torch.load with map_location to map your storages to an existing device.
模型保存都是一致的,不过时刻记住方案二中你有多个进程在同时跑,所以会保存多个模型到存储上,如果使用共享存储就要注意文件名的问题,当然一般只在rank0进程上保存参数即可,因为所有进程的模型参数是同步的。
torch.save(model.module.cpu().state_dict(), "model.pth")
模型的加载:
param=torch.load("model.pth")
以下是huggingface/transformers代码中用到的模型保存代码
if torch.distributed.get_rank() == 0:
model_to_save = model.module if hasattr(model, "module") else model # Take care of distributed/parallel training(因为并行训练的方法,会在模型的key中多‘module’,也不知道为什么)
model_to_save.save_pretrained(args.output_dir)
tokenizer.save_pretrained(args.output_dir)
同一台机器上跑多个 ddp task
假设想在一台有4核GPU的电脑上跑两个ddp task,每个task使用两个核,很可能会需要如下错误:
RuntimeError: Address already in use
RuntimeError: NCCL error in: /opt/conda/conda-bld/pytorch_1544081127912/work/torch/lib/c10d/ProcessGroupNCCL.cpp:260, unhandled system error
原因是两个ddp task通讯地址冲突,这时候需要显示地设置每个task的地址
specifying a different master_addr and master_port in torch.distributed.launch
# 第一个task
export CUDA_VISIBLE_DEVICES="0,1"
python -m torch.distributed.launch --nproc_per_node=2 --master_addr=127.0.0.1 --master_port=29501 train.py
# 第二个task
export CUDA_VISIBLE_DEVICES="2,3"
python -m torch.distributed.launch --nproc_per_node=2 --master_addr=127.0.0.2 --master_port=29502 train.py
分布式模型部署,引入SyncBN,将普通BN替换成SyncBN(NLP中一般是没有BN的)。
为什么使用 SyncBN看这里:DDP系列第三篇:实战与技巧 - 知乎
使用 DistributedDataParallel 包装模型,它能帮助我们为不同 GPU 上求得的梯度进行 all reduce(即汇总不同 GPU 计算所得的梯度,并同步计算结果)。all reduce 后不同 GPU 中模型的梯度均为 all reduce 之前各 GPU 梯度的均值
BatchNorm之类的层在其计算中使用了整个批次统计信息,因此无法仅使用一部分批次在每个GPU上独立进行操作。 PyTorch提供SyncBatchNorm作为BatchNorm的替换/包装模块,该模块使用跨GPU划分的整个批次计算批次统计信息。
model = Model()
# 把模型移到对应的gpu
# 定义并把模型放置到单独的GPU上,需要在调用`model=DDP(model)`前做
model.to(device)
# 引入SyncBN,这句代码,会将普通BN替换成SyncBN。
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
# GPU 数目大于 1 才有必要分布式训练
if torch.cuda.device_count() > 1:
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[local_rank],
output_device=local_rank)
参考
-
Pytorch 分布式训练
-
WRITING DISTRIBUTED APPLICATIONS WITH PYTORCH
-
pytorch 多GPU训练总结(DataParallel的使用)
-
Pytorch 分布式训练
-
Distributed data parallel training in Pytorch
相关文章:

anaconda创建、删除虚拟环境指令
使用conda创建、删除虚拟环境指令{\color{Red}使用conda创建、删除虚拟环境指令}使用conda创建、删除虚拟环境指令 使用conda创建、删除虚拟环境指令{\color{Red}使用conda创建、删除虚拟环境指令}使用conda创建、删除虚拟环境指令 一、创建虚拟环境 二、查看虚拟环境 三、激活…...
NCDC气象数据的提取与处理(二):python批量转换isd-lite数据为xlsx
目录 1.完整代码(部分代码参考https://zhuanlan.zhihu.com/p/556150264) 2.工作过程 2.1输入 2.2过程 3.实际效果 本例使用的相关数据及代码可见 链接:https://pan.baidu.com/s/1EYE0U7RrHSGGk3vptZyNVg 提取码:6666 书接上…...
MD5密码实验——Python实现(完整解析版)
文章目录更新:前言实验环境实验内容实验操作步骤1.初始化四个缓冲区2.设置常数表、位移位数等参数3.增加填充4.分组处理5.输出处理实验结果实验心得实验代码MD5-Python.py更新: 感谢评论区的大佬指出错误,现已改进代码 之前的错误在于没有考…...
如何在vscode中下载python第三方库(jieba和wordcloud为例)
本文由来 本来我并不想写文章的,但是我发现,对于一个0基础的小白vscode用户而言,想完整的下载一个第三方库还是存在一定的问题,并且我在搜索文章的时候发现,完全没有小白教程,太难了,所以说我就…...
python安装使用pip安装numpy
相信大家最近都在忙,因为到开学和上班的时候了,我最近也很忙,忙的快要流泪,这不是要考计算机三级了吗!买了好厚一本书,备战过程中,最近洗头一次掉了100根不止的头发,有点恐惧&#x…...
yolov5ds-断点训练、继续训练、先终止训练并调整最终epoch(yolov5同样适用)
目录参考链接1. 训练过程中中断了,继续训练如果觉得数值差不多稳定了,但是距离最终设置的epoch还很远,所以想要停止训练但是又得到yolov5在运行完指定最大epoch后生成的一系列map、混淆矩阵等图2. 训练完原有epoch,但还继续训练&a…...

openCV第一篇
文章目录 前言:计算机眼中的图片 1. 图片的读取与显示 1.1 图片的读取 1.2 显示的图片 1.2.1 显示原始图片 1.2.2 灰度图 1.3 BGR转换成灰度图、RGB 2. 保存图片 3. 视频的读取与显示 4. 截取图像部分 5. 颜色通道提取 6. 边界填充 7. 数值计算 8.…...

基于Python构建机器学习Web应用
目录 一、内容介绍 1.Onnx模型 ①skl2onnx库安装 2.Netron安装 二、模型构建 1.数据加载 2.划分可训练特征与预测标签 3.训练模型 ①第三方库导入 ②数据集划分 ③SVC模型构建 ④精度评价 二、模型转换及可视化 1.参数配置 2.Onnx模型生成 3.可视化模型 四、构…...
python - 密码加密与解密
Python之密码加密与解密 - 对称算法一、对称加密1.1 安装第三方库 - PyCrypto1.2 加密实现二、非对称加密三、摘要算法3.1 md5加密3.2 sha1加密3.3 sha256加密3.4 sha384加密3.5 sha512加密3.6 “加盐”加密由于计算机软件的非法复制,通信的泄密、数据安全受到威胁。…...
百度飞桨PaddleSpeech的简单使用
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型,一些典型的应用示例如下:语音识别、语音翻译 (英译中)、语音合成、标点恢复等。…...
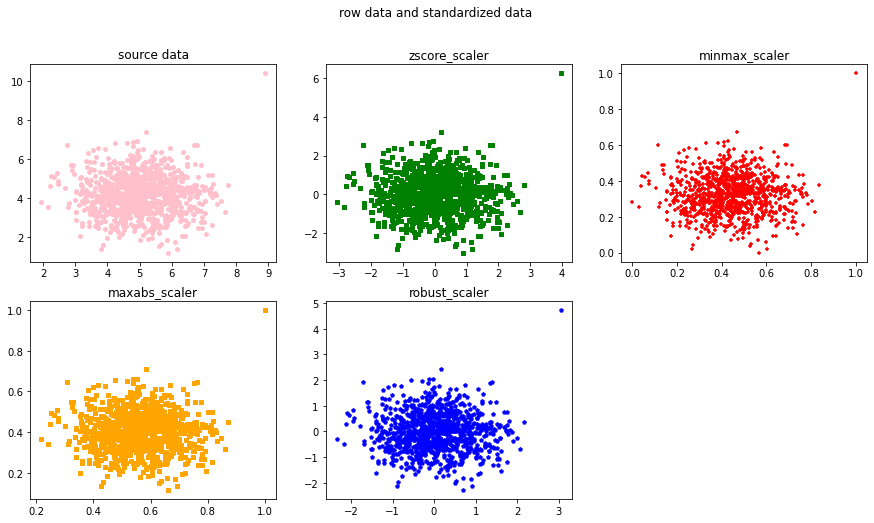
Python数据标准化
目录 一.数据标准化方式 1.实现中心化和正态分布的Z-Score 2.实现归一化的Max-Min 3.用于稀疏数据的MaxAbs 4.针对离群点的RobustScaler 二.Python针对以上几种标准化方法处理数据 三.总结 一.数据标准化方式 1.实现中心化和正态分布的Z-Score Z-Score标准化是基于原…...
Pycharm无法下载汉化包,一招教你搞定
Pycharm无法下载汉化包,一招教你搞定Pycharm直接导入汉化包Pycharm 无法采用自带的插件安装汉化包Pycharm直接导入汉化包 Pycharm 是可以直接导入汉化包的,这为很多初学者省区了不少麻烦。具体就是: 1:点击pycharm界面右上角的设…...

python成功实现“高配版”王者小游戏?【赠源码】
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 本游戏完整源码、素材: 点击此处跳转文末名片获取 咳咳,又是一款新的小游戏,就是大家熟悉的王者~ 来看我用python来实现高(di)配版的王者 是一款拿到代码运行后,…...
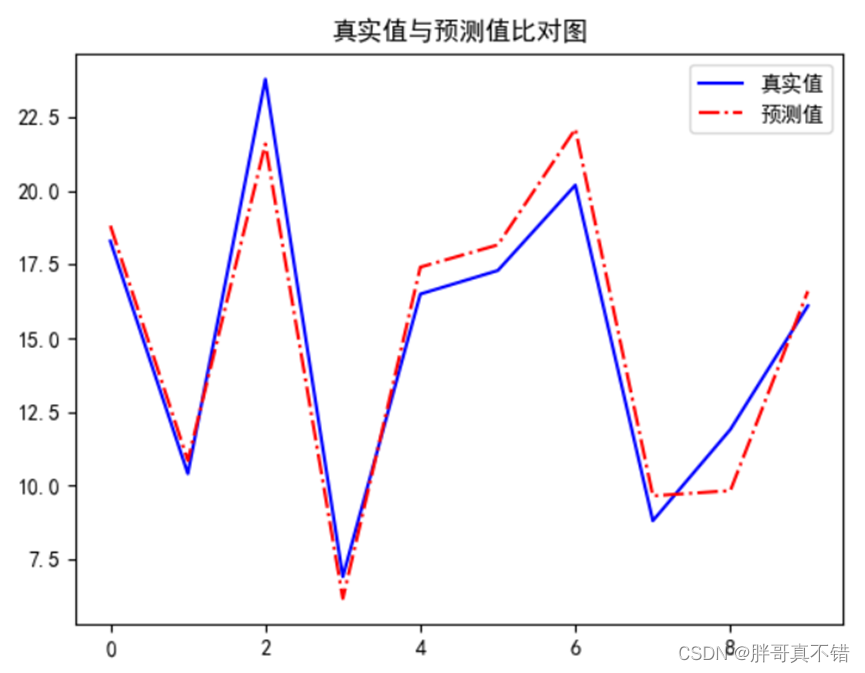
【项目实战】Python实现多元线性回归模型(statsmodels OLS算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 回归问题是一类预测连续值的问题,而能满足这样要求的数学模型称作回归模型,本项…...
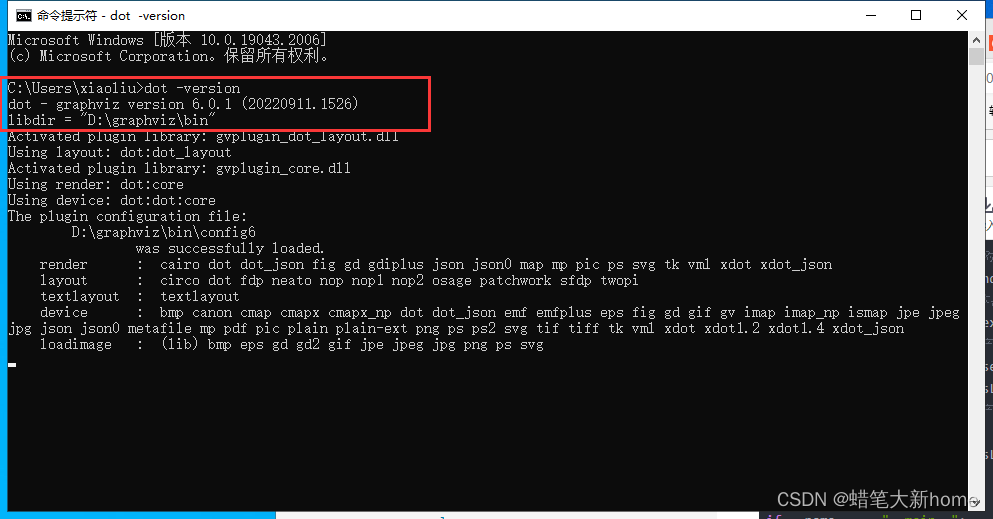
graphviz安装教程(2022最新版)初学者适用
1、首先在官网下载graphviz 下载网址:https://www.graphviz.org/download/ 2、安装。 打开第一步已经下载好的软件。点击下一步,在安装路径选择时可将安装路径修改为 D:\graphviz 接着一直点下一步,即可安装完成。 3、配置环境变量 右键…...

【Windows】搭建Pytorch环境(GPU版本,含CUDA、cuDNN),并在Pycharm上使用(零基础小白向)
文章目录前言一、安装CUDA1、检查电脑是否支持CUDA2、下载并安装CUDA3、下载并安装cuDNN二、安装Pytorch1、安装Anaconda2、切换清华镜像源3、创建环境并激活4、输入Pytorch安装命令5、测试三、在Pycharm上使用搭建好的环境参考文章前言 本人纯python小白,第一次使用…...
Tensorflow与CUDA、cudnn版本对应关系
不同版本的Tensorflow需对应不同的CUDA和cudnn版本,否者容易安装失败。可按下图所示,根据想要安装的Tensorflow版本,选择对应版本的CUDA和cudnn。 其中CUDA的下载链接为: CUDA Toolkit Archive | NVIDIA Developer cudnn下载链…...
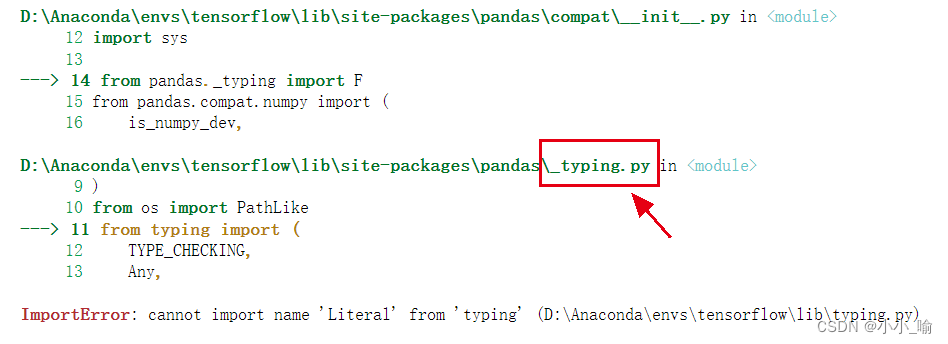
ImportError: cannot import name ‘Literal‘ from ‘typing‘ (D:\Anaconda\envs\tensorflow\lib\typing.py)
报错背景: 因为安装tensorflow-gpu版本需要,我把原来的新建的anaconda环境(我的名为tensorflow)中的python3.8降为了3.7。 在导入seaborn包时,出现了以下错误: ImportError: cannot import name Literal …...

100天精通Python(数据分析篇)——第67天:Pandas数据连接、合并、加入、添加、重构函数(merge、concat、join、append、stack、unstack)
文章目录 一、数据连接(pd.merge)1. left、right2. how3. on4. left_on、right_on5. sort6. suffixes7. left_index、right_index二、数据合并(pd.concat)1. index 没有重复的情况2. index 有重复的情况3. DataFrame合并时同时查看行索引和列索引有无重复三、数据加入(pd.…...
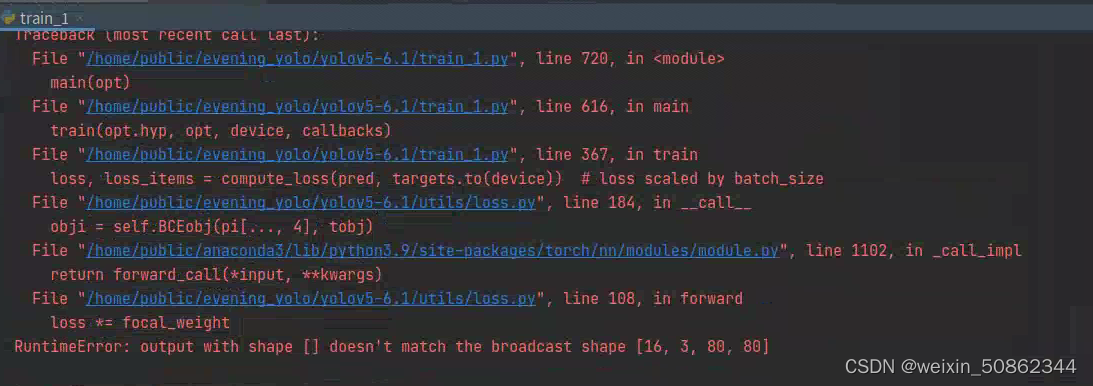
yolov5 优化系列(三):修改损失函数
1.使用 Focal loss 在util/loss.py中,computeloss类用于计算损失函数 # Focal lossg h[fl_gamma] # focal loss gammaif g > 0:BCEcls, BCEobj FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)其中这一段就是开启Focal loss的关键!!&…...
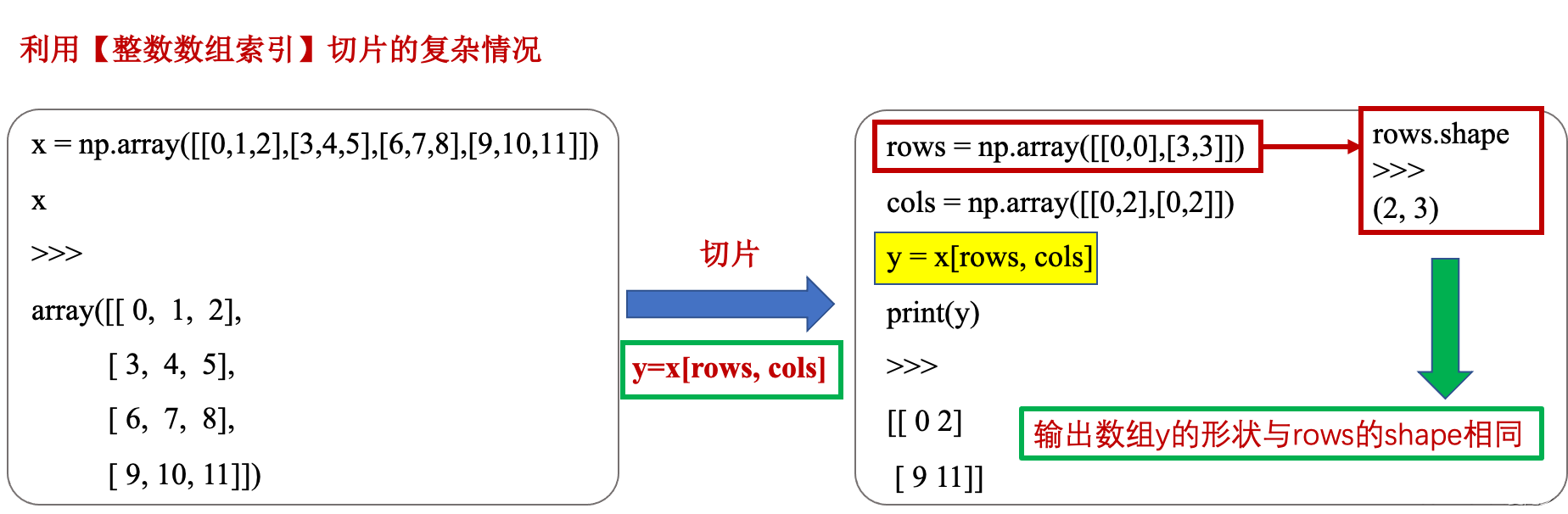
Python中数组切片的用法详解
Python中数组切片的用法详解一、python中“::-1”代表什么?二、python中“:”的用法三、python中数组切片三、numpy中的整数数组索引四、numpy中借助【切片 : 或 …与索引数组】组合进行复杂切片五、布尔索引六、花式索引一、python中“::-1”代表什么? …...
python 安装whl文件
前言 WHL文件是以Wheel格式保存的Python安装包,Wheel是Python发行版的标准内置包格式。在本质上是一个压缩包,WHL文件中包含了Python安装的py文件和元数据,以及经过编译的pyd文件,这样就使得它可以在不具备编译环境的条件下&#…...
Pycharm中安装pytorch
配置虚拟环境 为什么要安装虚拟环境?虚拟环境:把一部分内容独立出来,称之为容器。在容器中,安装我们自己想要的东西,比如不容版本的依赖包。各容器之间相互独立,互不影响。比如下载完 Anaconda 之后&#…...
Package | 解决 module ‘cv2‘ has no attribute ‘gapi_wip_gst_GStreamerPipeline‘
. 问题背景 由于这个问题出现了两回,决定记录一下。实验背景是使用opencv python库进行数据预处理,遇到报错信息如下: “ import cv2 File “/opt/conda/lib/python3.8/site-packages/cv2/init.py”, line 181, in bootstrap() File “/op…...
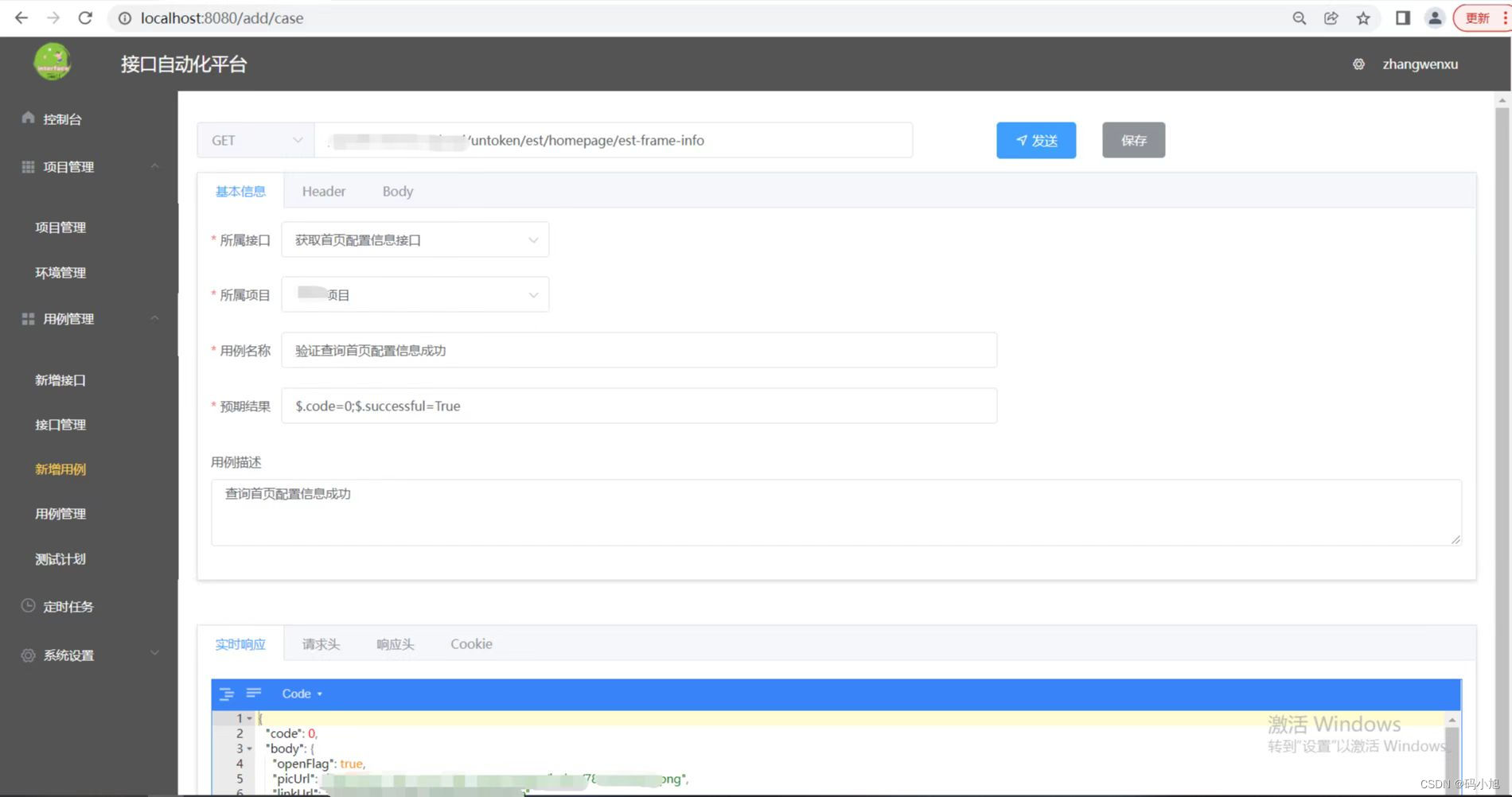
如何在项目中搭建python接口自动化框架?
文章目录前言一、框架目录介绍1、common模块读取Excel代码读取yaml代码(支持场景关联)jsonpath断言封装代码requests二次封装(get、post)configparser读取配置文件递归遍历字典常用方法log日志封装2、conf模块3、data模块4、case模…...
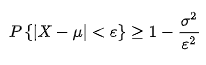
应用统计432考研复试复试提问总结精简版【一】
一、区间估计与假设检验的联系与区别 联系:二者利用样本进行推断,都属于推断统计区别: 原理: 前者是基于大概率,后者基于小概率;统计量:前者是构造枢轴量(不含未知参数,…...
Pytorch模型量化
在深度学习中,量化指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的bit来完成原本以浮点数完成的计算。这么做的好处主要有如下几点: 更少的模型体积,接近4倍的减少;可以更快的计算,由于…...

已解决Encountered error while trying to install package.> lxml
已解决(pip安装第三方模块lxml模块报错)Building wheels for collected packages: lxml Building wheel for lxml (setup.py) … error error: subprocess-exited-with-error python setup.py bdist_wheel did not run successfully. note: This error o…...

距离度量 —— 闵可夫斯基距离(Minkowski Distance)
Python学习系列文章:👉 目录 👈 文章目录一、概述二、计算公式1. 闵氏距离公式2. 闵氏距离的参数 p3. 闵氏距离的缺点一、概述 闵可夫斯基距离 (Minkowski Distance),也被称为 闵氏距离。它不仅仅是一种距离,而是将多…...
python(模块)xlwt
目录一、xlwt简介二、xlwt语法1、模块安装2、模块导入3、向xls文件中写入内容4、设置写入文件的格式4.1 字体设置(font)4.2 背景颜色设置(pattern)4.3 边框设置(borders)4.4 对齐方式设置(align…...

Pytorch中torch.unsqueeze()和torch.squeeze()函数解析
一. torch.squeeze()函数解析 1. 官网链接 torch.squeeze(),如下图所示: 2. torch.squeeze()函数解析 torch.squeeze(input, dimNone, outNone) squeeze()函数的功能是维度压缩。返回一个tensor(张量),其中 input…...
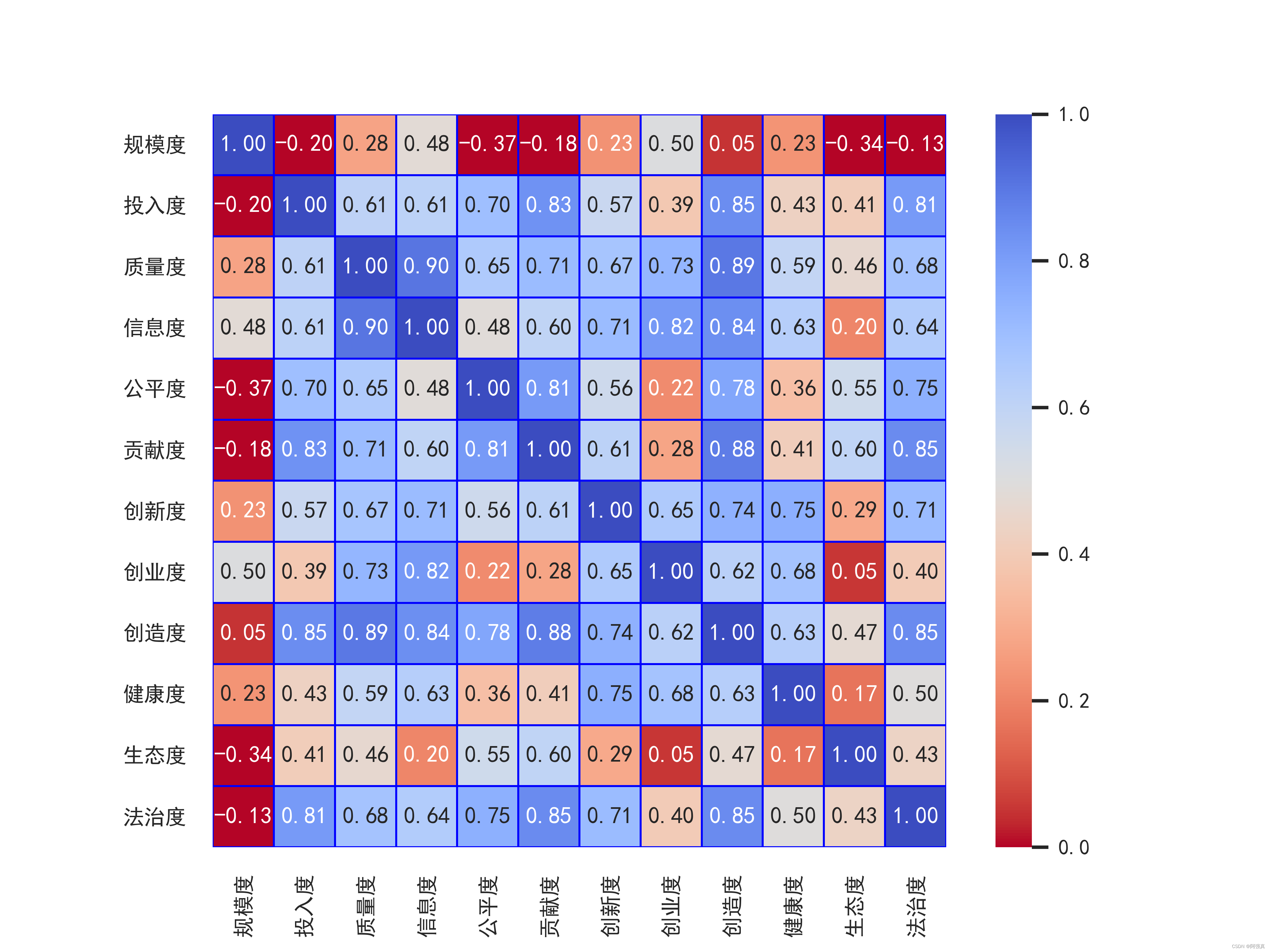
python绘制相关系数热力图
python绘制相关系数热力图一.数据说明和需要安装的库二.准备绘图三.设置配色,画出多幅图全部代码:本文讲述如何利用python绘制如上的相关系数热力图一.数据说明和需要安装的库 数据是31个省市有关教育的12个指标,如下所示。,在文…...
DeepSpeed使用指南(简略版)
现在的模型越来越大,动辄几B甚至几百B。但是显卡显存大小根本无法支撑训练推理。例如,一块RTX2090的10G显存,光把模型加载上去,就会OOM,更别提后面的训练优化。 作为传统pytorch Dataparallel的一种替代,D…...
【Python】tqdm 介绍与使用
文章目录一、tqdm 简介二、tqdm 使用1. 基于迭代对象运行: tqdm(iterator)2. tqdm(list)3. trange(i)4. 手动更新参考链接一、tqdm 简介 tqdm 是一个快速,可扩展的 Python 进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装…...
Pytorch机器学习(十)—— 目标检测中k-means聚类方法生成锚框anchor
Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 目录 Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 前言 一、K-means聚类 k-means代码 k-means算法 二、YOLO中使用k-means聚类生成anchor 读取VO…...
Python的占位格式符
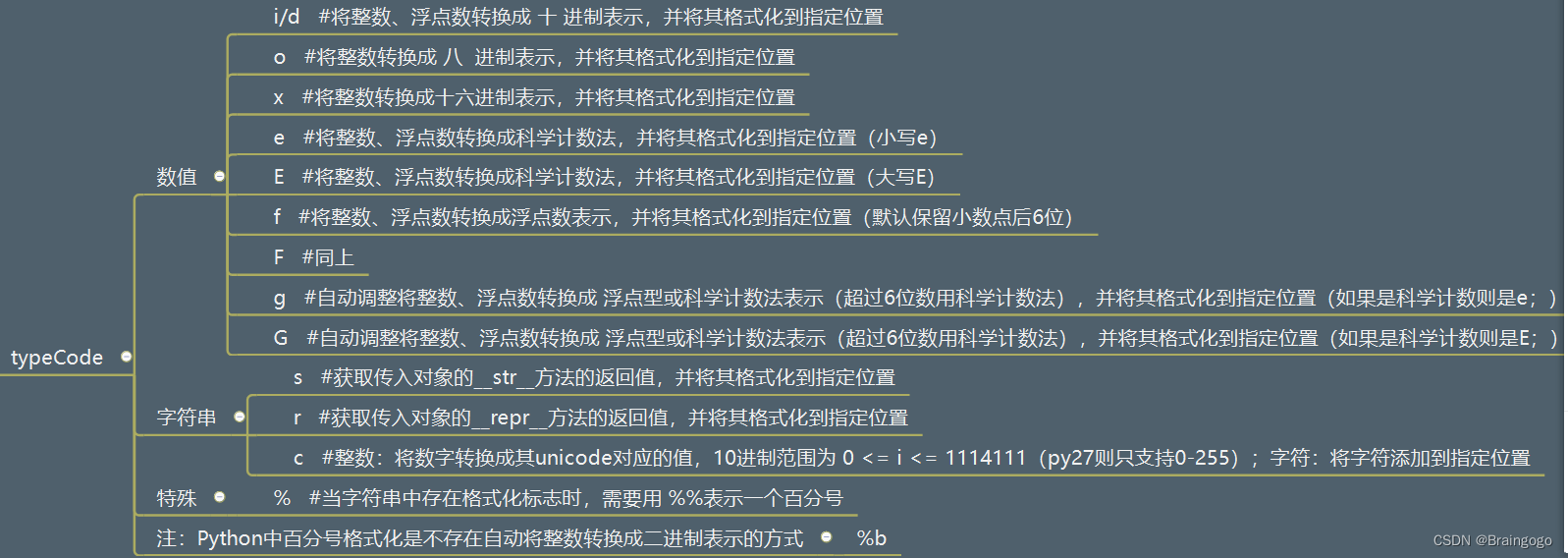
对于print函数里的语句 print("我的名字是%s, 年龄是%d"%(name, age)) 中的%s和%d叫做占位符,它们的完整形态是 %[(name)][flags][width][.precision]typecode 其中带有[]的前缀都是可以省略的。 [(name)]: (name)表示, 根据, 制定的名称(…...
关于sklearn库的安装
对于安装sklearn真的是什么问题都被我遇到了 例如pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(hostfiles.pythonhosted.org, port443): Read timed out.遇到了 这种也遇到了Requirement already satisfied: numpy in c:\users\yjq\appdata\roamin…...
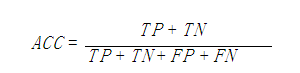
accuracy_score函数
1.acc计算原理 sklearn中accuracy_score函数计算了准确率。 在二分类或者多分类中,预测得到的label,跟真实label比较,计算准确率。 在multilabel(多标签问题)分类中,该函数会返回子集的准确率。如果对于一…...
怎么成为稚晖君?
如何成为IT大佬稚晖君——电子系统设计应具备的基本技能和方法论 快速提高电子技术的必经之路_一些老生常谈的道理 嵌入式AI入坑经历 稚晖君软件硬件开发环境总结 首先,机器学习深度学习这些和硬件是两个领域的内容,个人不建议一起学,注意力…...

Pandas库
Pandas是python第三方库,提供高性能易用数据类型和分析工具。Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用。pandas库引用: import pandas as pd 包括两个数据类型:Series(相当于一维数据类型)&…...

通过两道一年级数学题反思自己
背景 做完这两道题我开始反思自己,到底是什么限制了我?是我自己?是曾经教导我的老师?还是我的父母? 是考试吗?还是什么? 提目 1、正方体个数问题 2、相碰可能性 过程 静态思维: …...
深度学习—卷积神经网络(CNN)全笔记,附代码
本文内容为哔站学习笔记【卷积神经网络-CNN】深度学习(唐宇迪带你学AI):卷积神经网络理论详解与项目实战,计算机视觉,图像识别模块实战_哔哩哔哩_bilibili 目录 深度学习基础 什么是深度学习? 机器学习流…...
Building wheel for mmcv-full (setup.py) ... error解决办法!
mmdetection 安装后,根据官方给的程序安装mmcv时,出现:Building wheel for mmcv-full (setup.py) … error 环境:CUDA11.3, Pytorch1.11 安装根据官网给的安装程序:pip install mmcv-full -f https://download.openmm…...
联邦学习开山之作代码解读与收获
参考:联邦学习代码解读,超详细_一只揪的博客-CSDN博客_联邦学习代码 参考文献:[1602.05629] Communication-Efficient Learning of Deep Networks from Decentralized Data (arxiv.org) 参考代码:GitHub - AshwinRJ/Federated-L…...
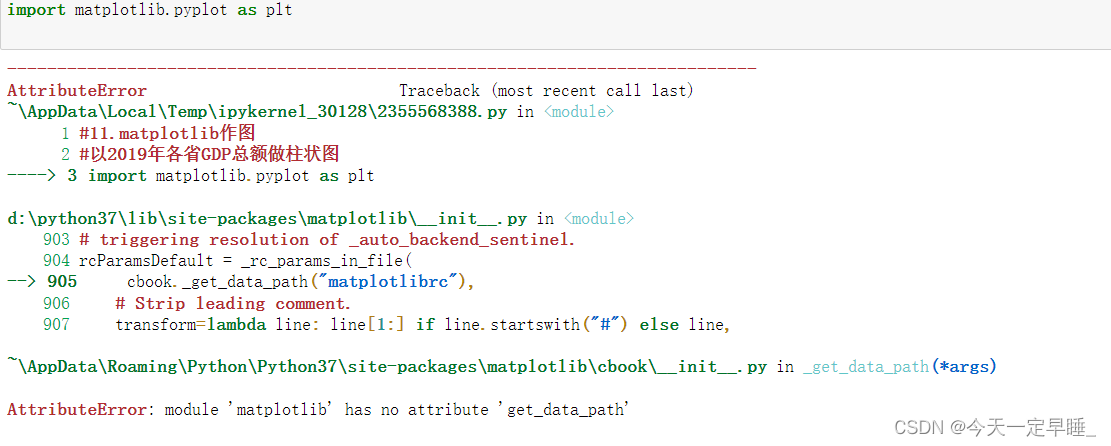
Python安装第三方库常用方法 超详细~
Python安装第三方库常用方法前言安装方法1. 通过pychram安装2. pip安装大法3. 下载whl文件到本地离线安装3.1 补充4.其他方法4.1 Python官方的Pypi菜单4.2 国内镜像源解决pip安装过慢的问题小结前言 在pyhton的学习中,相信大家通常都会碰到第三方库的安装问题&…...
Python--找出字符串中出现次数最多的字符及其出现的次数
方法一: 1、循环遍历列表或字符串,如果字符在字典中则值加1,如果不在则创建(key,value) 2、找到字典中,最大的value值 3、根据最大的value值,找对应的key值,打印出出现次数最多的字符 str &qu…...

滤波笔记一:卡尔曼滤波(Kalman Filtering)详解
本笔记是总结了B站DR_CAN的卡尔曼滤波器的课程,他的B站主页为:DR_CAN的个人空间_哔哩哔哩_bilibili PS:虽然我不是学自控的,但是老师真的讲的很好! 目录 Lesson1 递归算法 Lesson2 数学基础_数据融合_协方差矩阵_状态空间方程…...
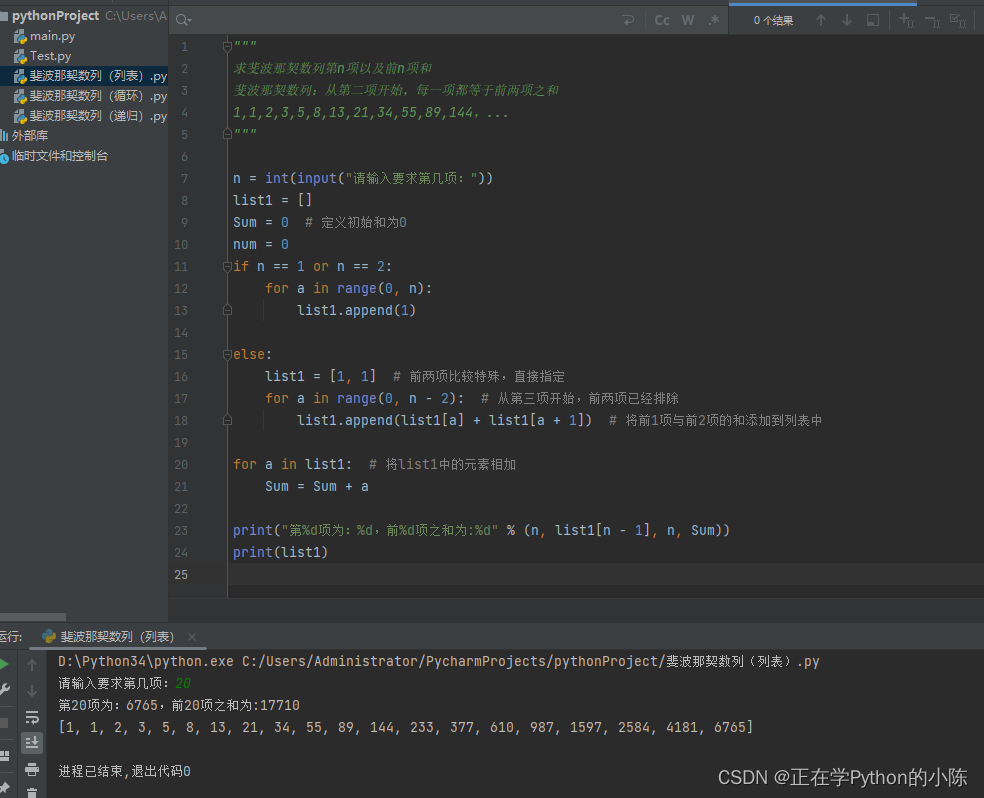
利用Python求斐波那契数列的第N项以及前N项和(循环、递归、集合)
著名的斐波那契数列,即从第三项开始,每一项都等于前两项之和。 之前写过利用Java语言来编写,由于最近正在学Python,所以将自己的想法记录在此,有需要的朋友可以参考一下。 写在前面:这里的三个方法其实思…...
一文速学(十八)-数据分析之Pandas处理文本数据(str/object)各类操作+代码一文详解(三)
目录 前言 一、子串提取 提取匹配首位子串 提取所有匹配项(extractall)...
Python数据分析-数据预处理
数据预处理 文章目录数据预处理1.前言2.数据探索2.1缺失值分析2.2 异常值分析2.2.1 简单统计量分析2.2.2 3$\sigma$原则2.2.3 箱线图分析2.3 一致性分析2.4 相关性分析3.数据预处理3.1 数据清洗3.1.1 缺失值处理3.1.2 异常值处理3.2 数据集成3.2.1 实体识别3.2.2 冗余属性识别3…...