头歌Python数据框、序列定义及数据处理应用实验闯关
粘贴答案不是目的
把Python学会这才叫做意义
童年的纸飞机
现在终于飞回我手里~~
文章目录
- 第1关:序列和数据框
- 第2关:外部数据文件读取
- 第3关:逻辑索引、切片方法,groupby 分组计算函数应用
- 第4关:数据框关联操作
- 第5关:数据框合并操作
- 第6关:序列移动计算方法应用
- 第7关:数据框切片(iloc、loc)方法
- 第8关:数据框排序
- 第9关:数据框综合应用案例
- 第10关:序列及简单随机抽样
- 第11关:序列及较复杂抽样
第1关:序列和数据框
这是网站给的答案,不过运行报错,其他关卡应该没问题。
#********** Begin **********#
#完成以下任务
#1.导入pandas包
#2.定义列表L1、L2,元组T1、T2
#L1=[1,-2,2.3,'hq']
#L2=['kl','ht','as','km']
#T1=(1,8,8,9)
#T2=(2,4,7,'hp')
#3.构造数据框,默认索引,列名依次为a,b,c,d,返回计算结果A
#4.构造数据框,索引为a,b,c,d,列名为L1,L2,T1,T2,返回计算结果B
def return_values():
import pandas as pd
L1 = [1,-2,2.3,'hq']
L2 = ['kl','ht','as','km']
T1 = (1,8,8,9)
T2 = (2,4,7,'hp')
data = {'a':L1,'b':L2,'c':T1,'d':T2}
A= pd.DataFrame(data) #默认索引,列名为a,b,c,d
t1 = pd.Series(L1,index = ['a','b','c','d'])
t2 = pd.Series(L2,index = ['a','b','c','d'])
t3 = pd.Series(T1,index = ['a','b','c','d'])
t4 = pd.Series(T2,index = ['a','b','c','d'])
t = {'L1':t1,'L2':t2,'T1':t3,'T2':t4}
B = pd.DataFrame(t) #索引为a,b,c,d,列名为L1,L2,T1,T2
return(A,B)
#********** End **********#
第2关:外部数据文件读取
#********** Begin **********#
#1.导入pandas包
#2.read_excel()函数读取“一、车次上车人数统计表.xlsx”中的数据,用一个数据框df1来存储,并输出第0行
#3.通过read_table()函数可以读取"txt1.txt"文件中的数据(不带表头),用一个数据框df2来表示,并输出第0行
#4.通过read_csv()函数读取用分块读取的方式读取“data.csv”文件,每次读取20000行,并输出每次读取的数据集行数
#5.输出格式为“第n次读取数据规模为:20000 /n (20000, 行数)”
#在函数中编写程序
def return_values():
import pandas as pd
df1 = pd.read_excel('一、车次上车人数统计表.xlsx')
df2 = pd.read_table('txt1.txt',header=None)
reader = pd.read_csv('data.csv',chunksize=20000)
k=0;
names = locals()#设置全局变量
for i in reader:
k=k+1
names['A%s'%k]=pd.DataFrame(i)#创建A1~Ak个变量,分别保存各分块
print('第'+str(k)+'次读取数据规模为: ',len(i))
print(i.shape)
#********** End **********#
第3关:逻辑索引、切片方法,groupby 分组计算函数应用
#********** Begin **********#
#本关任务:
#请读取地铁站点进出站客流数据表(Data.xlsx),表结构字段如下:
# 站点编号、日期、时刻、进站人数、出站人数
#完成以下任务:
#1)取出第0列,通过去重的方式获得地铁站点编号列表,记为code
#2)采用数据框中的groupby分组计算函数,统计出每个地铁站点每天的进站人数和出站人数,
# 计算结果采用一个数据框sat_num来表示,其中列标签依次为:站点编号、日期、进站人数和出站人数;
#3)计算出每个站点国庆节期间(10.1~10.7)的进站人数和出站人数,
# 计算结果用一个数据框sat_num2来表示,其中列标签依次为:A1_站点编号、A2_进站人数、A3_出站人数。
def return_values():
import pandas as pd
A=pd.read_excel('Data.xlsx')
code=list(A['站点编号'].unique())
B=A.groupby(['站点编号','日期'])['进站人数','出站人数'].sum()
c=list(B.index)
A1=[]
A2=[]
for i in range(len(c)):
r=c[i]
A1.append(r[0])
A2.append(r[1])
sat_num=pd.DataFrame({'A1_站点编号':A1,'A2_日期':A2,'A3_进站人数':B['进站人数'].values,
'A4_出站人数':B['出站人数'].values})
D=sat_num.iloc[sat_num['A2_日期'].values<='2015-10-07',:]
D1=D.groupby(['A1_站点编号'])['A3_进站人数','A4_出站人数'].sum()
sat_num2=pd.DataFrame({'A1_站点编号':list(D1.index),
'A2_进站人数':D1['A3_进站人数'].values,'A3_出站人数':D1['A4_出站人数'].values})
return(code,sat_num,sat_num2)
#********** End **********#
第4关:数据框关联操作
#********** Begin **********#
def return_values():
#1.导入pandas包
import pandas as pd
#2.定义两个字典 dict1 和 dict2
dict1={'code':['A01','A01','A01','A02','A02','A02','A03','A03'],
'month':['01','02','03','01','02','03','01','02'],
'price':[10,12,13,15,17,20,10,9]}
dict2={'code':['A01','A01','A01','A02','A02','A02'],
'month':['01','02','03','01','02','03'],
'vol':[10000,10110,20000,10002,12000,21000]}
#3.将两个字典转化为数据框;
dict1 = pd.DataFrame(dict1)
dict2 = pd.DataFrame(dict2)
#4.对两个数据框完成内连接、左连接、右连接;
df_inner=pd.merge(dict1,dict2,how='inner',on=['code','month'])#内连接
df_left=pd.merge(dict1,dict2,how='left',on=['code','month']) #左连接
df_right=pd.merge(dict1,dict2,how='right',on=['code','month']) #右连接
return(df_inner,df_left,df_right)
#********** End **********#
第5关:数据框合并操作
#********** Begin **********#
def return_values():
import pandas as pd
import numpy as np
#1.定义三个字典dict1、dict2和dict3
dict1={'a':[2,2,'kt',6],'b':[4,6,7,8],'c':[6,5,np.nan,6]}
dict2={'d':[8,9,10,11],'e':['p',16,10,8]}
dict3={'a':[1,2],'b':[2,3],'c':[3,4],'d':[4,5],'e':[5,6]}
#2.将三个字典转化为数据框df1、df2、df3;
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)
df3 = pd.DataFrame(dict3)
#3.df1和df2进行水平合并,合并后的数据框记为df4;
df4 = pd.concat([df1,df2],axis=1)
#4.df3和df4垂直合并,并修改合并后的index为按默认顺序排列,修改合并后的数据框记为df5
df5 = pd.concat([df3,df4],axis=0)
return(df4,df5)
#********** End **********#
第6关:序列移动计算方法应用
#********** Begin **********#
def return_values():
#1.导入pandas包
import pandas as pd
#2.定义列表L
L=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]
#3.把列表L转化为序列S
S = pd.Series(L)
#4.针对S实现周期为10的移动求和、求平均值、求最大值、求最小值的计算
Sum = S.rolling(10).sum()
mean = S.rolling(10).mean()
max1 = S.rolling(10).max()
min1 = S.rolling(10).min()
return(L,S,Sum)
#********** End **********#
第7关:数据框切片(iloc、loc)方法
#********** Begin **********#
#1、导入pdndas包
#2、读取地铁站点进出站客流数据表(Data.xlsx),字段依次为:
# 站点编号、日期、时刻、进站人数、出站人数
#3、采用索引(iloc)实现的方式,获取135站点
# 10月1日-10月2日早上9-11点3个时刻的进站客流量数据(取所有字段),记为A
#4、采用列标签(loc)实现方式,获取135站点
# 10月1日-10月2日早上9-11点3个时刻的进站客流量数据(取所有字段),记为B。
def return_values():
import pandas as pd
#索引实现
read = pd.read_excel('Data.xlsx')
zhandian = read.iloc[read['站点编号'].values==135,:]
riqi = zhandian.iloc[zhandian['日期'].values<'2015-10-03',:]
shike = riqi.iloc[riqi['时刻'].values>=9,:]
shike1 = shike.iloc[shike['时刻'].values<=11,:]
A1 = read['站点编号'].values==135
A2 = read['日期'].values<'2015-10-03'
A3 = read['时刻'].values>=9
A4 = read['时刻'].values<=11
A = read.iloc[A1&A2&A3&A4,[0,1,2,3]]
read = pd.read_excel('Data.xlsx')
zhandian = read.loc[read['站点编号'].values==135,:]
riqi = zhandian.loc[zhandian['日期'].values<'2015-10-03',:]
shike = riqi.loc[riqi['时刻'].values>=9,:]
shike1 = shike.loc[shike['时刻'].values<=11,:]
A1 = read['站点编号'].values==135
A2 = read['日期'].values<'2015-10-03'
A3 = read['时刻'].values>=9
A4 = read['时刻'].values<=11
B = read.loc[A1&A2&A3&A4,:]
return(A,B)
#********** End **********#
第8关:数据框排序
#********** Begin **********#
#1.导入pandas包
#2.用read_excel()函数读取“data.xlsx"表,用数据框read表示
#3.提取600000.SH代码交易数据,并按交易日期从小到大进行排序,记为data
#4.对整个数据框read,按代码、交易日期从小到大进行排序
def return_values():
import pandas as pd
read = pd.read_excel('data.xlsx')
data = read.iloc[read['代码'].values=='600000.SH',:].sort_values('交易日期',axis=0)
da2 = read.sort_values(['代码','交易日期'])
return(data,da2)
#********** End **********#
第9关:数据框综合应用案例
#********** Begin **********#
#本关任务:
#读取地铁站点进出站客流数据表(Data.xlsx),统计计算获得每个站点每个时刻(除去国庆期间)的总进站客流量和总出站客流量,
#用一个数据框来R表示,结果返回R,列名依次为:A1_站点编号、A2_时刻、A3_总进站客流、A4_总出站客流
def return_values():
import pandas as pd
import numpy as np
#读取数据
df = pd.read_excel('Data.xlsx')
df=df.iloc[df['日期'].values>='2015-10-08',:]
station = df.iloc[:,0].unique()
time = df.iloc[:,2].unique()
A1 =[]
A2 =[]
A3 =[]
A4 =[]
for i in range(len(station)):
d1=df.iloc[df['站点编号'].values==station[i],:]
for j in range(len(time)):
sk = d1['时刻'].unique()
if time[j] in sk:
jz_sum = d1.iloc[d1['时刻'].values==time[j],3].sum()
cz_sum = d1.iloc[d1['时刻'].values==time[j],4].sum()
A1.append(station[i])
A2.append(time[j])
A3.append(jz_sum)
A4.append(cz_sum)
df0=pd.DataFrame({'A1_站点编号':A1,'A2_时刻':A2,'A3_总进站客流':A3,'A4_总出站客流':A4})
df0.to_excel('各站点各时刻进出站客流数据.xlsx')
return(df0)
#********** End **********#
第10关:序列及简单随机抽样
#********** Begin **********#
#1.定义一个列表code,编号为1~30
#2.对code,按30个元素一次随机抽样,记为A
#3.返回结果,为序列s,其中index为编号,值为抽样结果
def return_values():
import random
import pandas as pd
code=list(range(1,31))
A=random.sample(code,30)
s=pd.Series(A,index=code)
return s
第11关:序列及较复杂抽样
#********** Begin **********#
def return_values():
#定义一个数据框A,index为默认序号(0~39),代表每一位同学
#数据框A的第0列表示每位同学随机抽签的第1种题型的序号,第1、2、3、4列依次类推
#知识点,考查random.randint(),随机整数的生成应用
import random
import pandas as pd
t1=[]
t2=[]
t3=[]
t4=[]
t5=[]
for i in range(40):
t1.append(random.randint(1,70))
t2.append(random.randint(1,80))
t3.append(random.randint(1,50))
t4.append(random.randint(1,30))
t5.append(random.randint(1,20))
A=pd.DataFrame({'t1':t1,'t2':t2,'t3':t3,'t4':t4,'t5':t5})
return A
#********** End **********#
相关文章:

使用pip下载时提示“You are using pip version 8.1.1, however version 22.1 is available.“
在使用pip install下载其他包时,报了错,如图: 提示:“You are using pip version 8.1.1, however version 22.1 is available. You should consider upgrading via the ‘pip install --upgrade pip’ command.” 根据提示&#…...

YOLOV8-gradcam 热力图可视化 即插即用 不需要对源码做任何修改!
YOLOV8 GradCam 热力图可视化. 本文给大家带来yolov8-gradcam热力图可视化,这个可视化是即插即用,不需要对源码做任何修改喔!给您剩下的不少麻烦! 代码链接:yolo-gradcam 里面还有yolov5和v7的热力图可视化代码&#…...
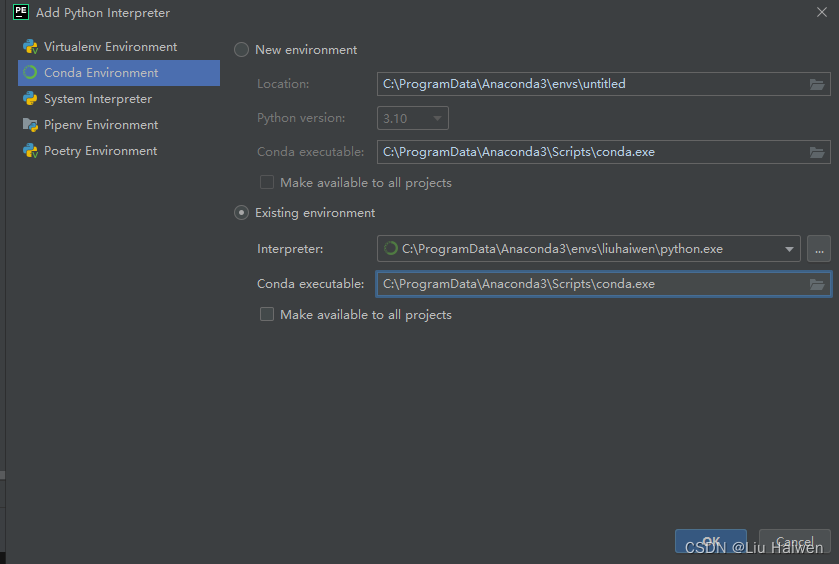
Anaconda创建虚拟环境并在Pycharm中使用创建好的环境
Anaconda创建虚拟环境并在Pycharm中使用创建好的环境1.Anaconda创建虚拟环境2.Pycharm中使用创建好的环境3.2022.12.8更新Anaconda的优势在于可以很方便地管理自己的工具包、开发环境和Python版本,同时还能使用不同的虚拟环境隔离不同要求的项目。假如你已经安装好了…...

python二级题库(百分之九十原题) 刷题软件推荐 第二套
目录 一、选择题 二、基本操作 三、简单应用 四、综合应用 刷题软件(模拟python二级考试): 公众h:露露IT 回复:python二级 一、选择题 1、下列叙述中正确的是()。 A.在栈中,栈…...

【模拟 简易银行系统~python】
目录~python面向对象编程之模拟银行系统相关程序代码如下:运行效果如下:pandas 每日一练:运行结果为:66、绘制sku_cost_prc的密度曲线运行效果为:67、计算后一天与前一天sku_cost_prc的差值运行结果为:68、…...

【YOLOv7/YOLOv5系列改进NO.52】融入YOLOv8中的C2f模块
文章目录 前言一、解决问题二、基本原理三、YOLOv5添加方法四、YOLOv7添加方法五、总结前言 作为当前先进的深度学习目标检测算法YOLOv7,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点…...

PyTorch 单机多GPU 训练方法与原理整理
PyTorch 单机多GPU 训练方法与原理整理 这里整理一些PyTorch单机多核训练的方法和简单原理,目的是既能在写代码时知道怎么用,又能从原理上知道大致是怎么回事儿。 就目前来说,并行训练的方法可以根据的不同的并行对象分为——模型并行和数据…...
anaconda创建、删除虚拟环境指令
使用conda创建、删除虚拟环境指令{\color{Red}使用conda创建、删除虚拟环境指令}使用conda创建、删除虚拟环境指令 使用conda创建、删除虚拟环境指令{\color{Red}使用conda创建、删除虚拟环境指令}使用conda创建、删除虚拟环境指令 一、创建虚拟环境 二、查看虚拟环境 三、激活…...
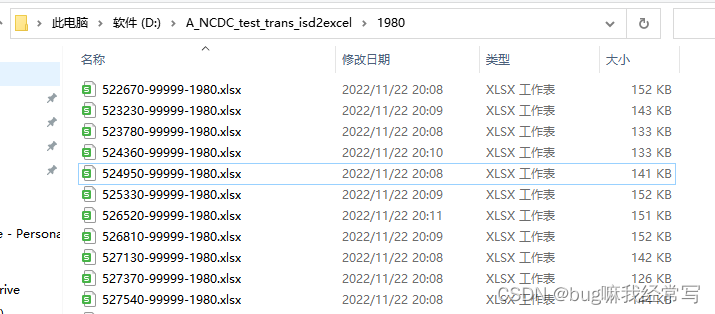
NCDC气象数据的提取与处理(二):python批量转换isd-lite数据为xlsx
目录 1.完整代码(部分代码参考https://zhuanlan.zhihu.com/p/556150264) 2.工作过程 2.1输入 2.2过程 3.实际效果 本例使用的相关数据及代码可见 链接:https://pan.baidu.com/s/1EYE0U7RrHSGGk3vptZyNVg 提取码:6666 书接上…...
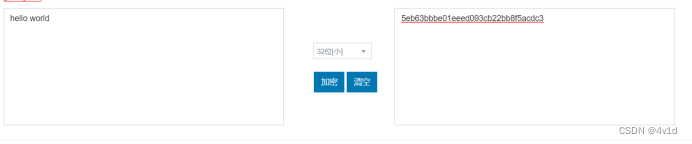
MD5密码实验——Python实现(完整解析版)
文章目录更新:前言实验环境实验内容实验操作步骤1.初始化四个缓冲区2.设置常数表、位移位数等参数3.增加填充4.分组处理5.输出处理实验结果实验心得实验代码MD5-Python.py更新: 感谢评论区的大佬指出错误,现已改进代码 之前的错误在于没有考…...
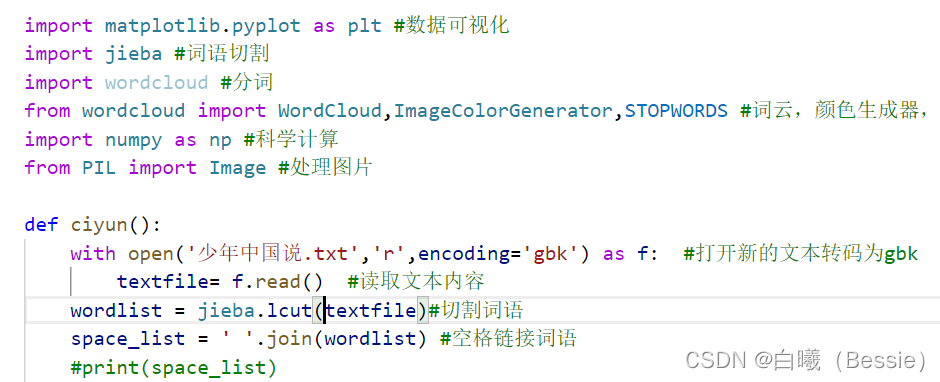
如何在vscode中下载python第三方库(jieba和wordcloud为例)
本文由来 本来我并不想写文章的,但是我发现,对于一个0基础的小白vscode用户而言,想完整的下载一个第三方库还是存在一定的问题,并且我在搜索文章的时候发现,完全没有小白教程,太难了,所以说我就…...
python安装使用pip安装numpy
相信大家最近都在忙,因为到开学和上班的时候了,我最近也很忙,忙的快要流泪,这不是要考计算机三级了吗!买了好厚一本书,备战过程中,最近洗头一次掉了100根不止的头发,有点恐惧&#x…...
yolov5ds-断点训练、继续训练、先终止训练并调整最终epoch(yolov5同样适用)
目录参考链接1. 训练过程中中断了,继续训练如果觉得数值差不多稳定了,但是距离最终设置的epoch还很远,所以想要停止训练但是又得到yolov5在运行完指定最大epoch后生成的一系列map、混淆矩阵等图2. 训练完原有epoch,但还继续训练&a…...

openCV第一篇
文章目录 前言:计算机眼中的图片 1. 图片的读取与显示 1.1 图片的读取 1.2 显示的图片 1.2.1 显示原始图片 1.2.2 灰度图 1.3 BGR转换成灰度图、RGB 2. 保存图片 3. 视频的读取与显示 4. 截取图像部分 5. 颜色通道提取 6. 边界填充 7. 数值计算 8.…...

基于Python构建机器学习Web应用
目录 一、内容介绍 1.Onnx模型 ①skl2onnx库安装 2.Netron安装 二、模型构建 1.数据加载 2.划分可训练特征与预测标签 3.训练模型 ①第三方库导入 ②数据集划分 ③SVC模型构建 ④精度评价 二、模型转换及可视化 1.参数配置 2.Onnx模型生成 3.可视化模型 四、构…...
python - 密码加密与解密
Python之密码加密与解密 - 对称算法一、对称加密1.1 安装第三方库 - PyCrypto1.2 加密实现二、非对称加密三、摘要算法3.1 md5加密3.2 sha1加密3.3 sha256加密3.4 sha384加密3.5 sha512加密3.6 “加盐”加密由于计算机软件的非法复制,通信的泄密、数据安全受到威胁。…...
百度飞桨PaddleSpeech的简单使用
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型,一些典型的应用示例如下:语音识别、语音翻译 (英译中)、语音合成、标点恢复等。…...
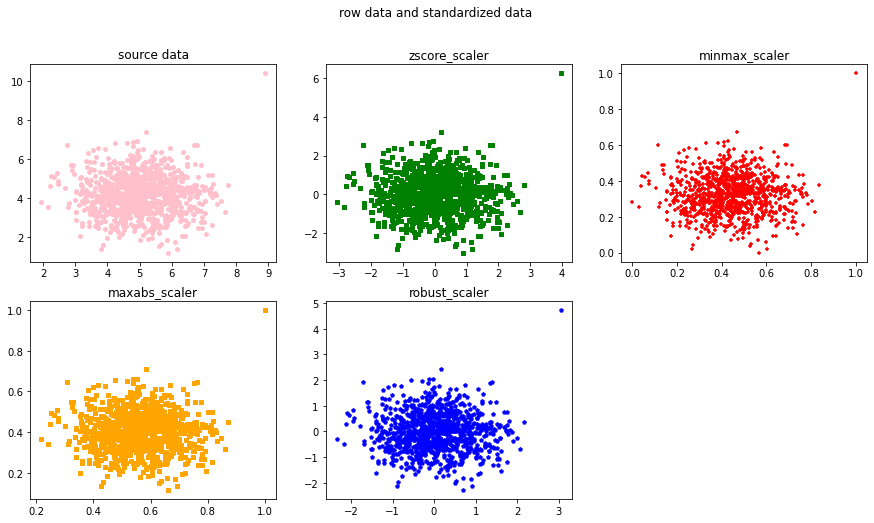
Python数据标准化
目录 一.数据标准化方式 1.实现中心化和正态分布的Z-Score 2.实现归一化的Max-Min 3.用于稀疏数据的MaxAbs 4.针对离群点的RobustScaler 二.Python针对以上几种标准化方法处理数据 三.总结 一.数据标准化方式 1.实现中心化和正态分布的Z-Score Z-Score标准化是基于原…...
Pycharm无法下载汉化包,一招教你搞定
Pycharm无法下载汉化包,一招教你搞定Pycharm直接导入汉化包Pycharm 无法采用自带的插件安装汉化包Pycharm直接导入汉化包 Pycharm 是可以直接导入汉化包的,这为很多初学者省区了不少麻烦。具体就是: 1:点击pycharm界面右上角的设…...

python成功实现“高配版”王者小游戏?【赠源码】
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 本游戏完整源码、素材: 点击此处跳转文末名片获取 咳咳,又是一款新的小游戏,就是大家熟悉的王者~ 来看我用python来实现高(di)配版的王者 是一款拿到代码运行后,…...
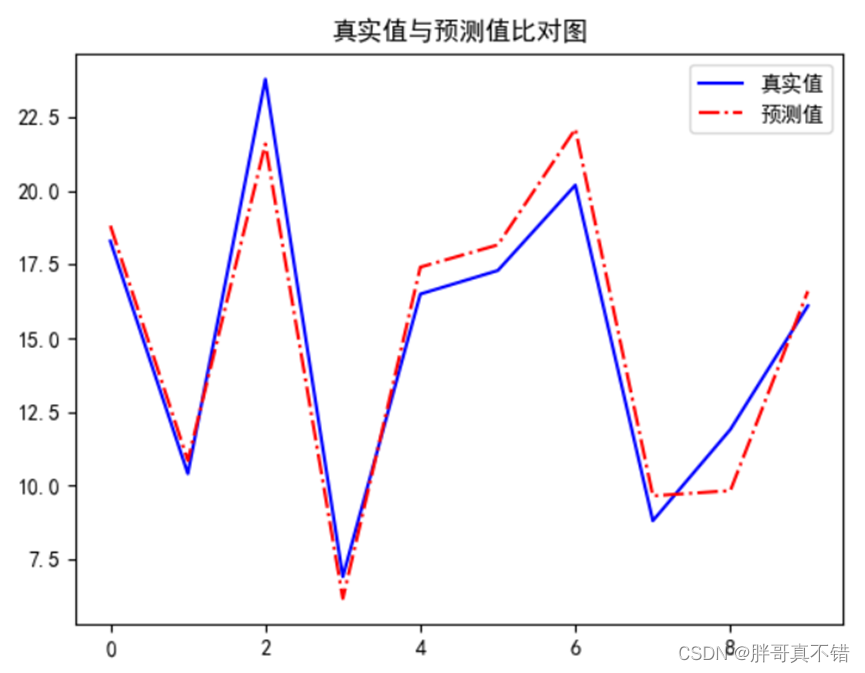
【项目实战】Python实现多元线性回归模型(statsmodels OLS算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 回归问题是一类预测连续值的问题,而能满足这样要求的数学模型称作回归模型,本项…...
graphviz安装教程(2022最新版)初学者适用
1、首先在官网下载graphviz 下载网址:https://www.graphviz.org/download/ 2、安装。 打开第一步已经下载好的软件。点击下一步,在安装路径选择时可将安装路径修改为 D:\graphviz 接着一直点下一步,即可安装完成。 3、配置环境变量 右键…...

【Windows】搭建Pytorch环境(GPU版本,含CUDA、cuDNN),并在Pycharm上使用(零基础小白向)
文章目录前言一、安装CUDA1、检查电脑是否支持CUDA2、下载并安装CUDA3、下载并安装cuDNN二、安装Pytorch1、安装Anaconda2、切换清华镜像源3、创建环境并激活4、输入Pytorch安装命令5、测试三、在Pycharm上使用搭建好的环境参考文章前言 本人纯python小白,第一次使用…...
Tensorflow与CUDA、cudnn版本对应关系
不同版本的Tensorflow需对应不同的CUDA和cudnn版本,否者容易安装失败。可按下图所示,根据想要安装的Tensorflow版本,选择对应版本的CUDA和cudnn。 其中CUDA的下载链接为: CUDA Toolkit Archive | NVIDIA Developer cudnn下载链…...
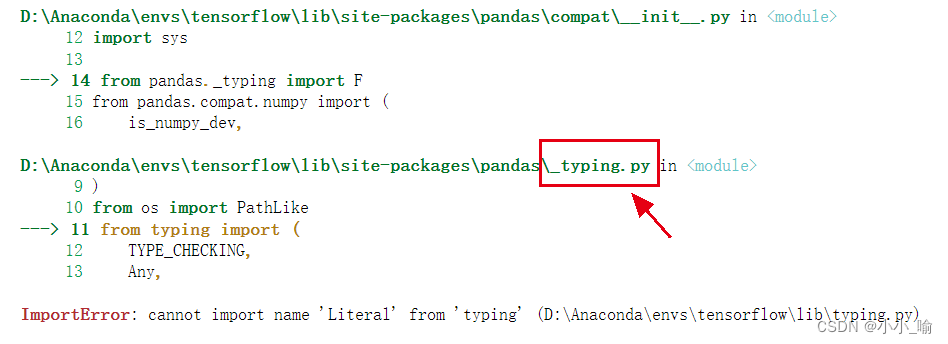
ImportError: cannot import name ‘Literal‘ from ‘typing‘ (D:\Anaconda\envs\tensorflow\lib\typing.py)
报错背景: 因为安装tensorflow-gpu版本需要,我把原来的新建的anaconda环境(我的名为tensorflow)中的python3.8降为了3.7。 在导入seaborn包时,出现了以下错误: ImportError: cannot import name Literal …...

100天精通Python(数据分析篇)——第67天:Pandas数据连接、合并、加入、添加、重构函数(merge、concat、join、append、stack、unstack)
文章目录 一、数据连接(pd.merge)1. left、right2. how3. on4. left_on、right_on5. sort6. suffixes7. left_index、right_index二、数据合并(pd.concat)1. index 没有重复的情况2. index 有重复的情况3. DataFrame合并时同时查看行索引和列索引有无重复三、数据加入(pd.…...
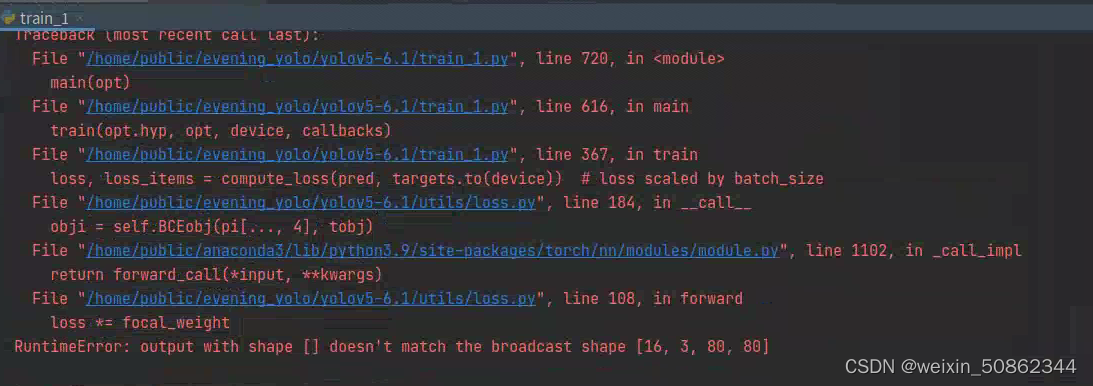
yolov5 优化系列(三):修改损失函数
1.使用 Focal loss 在util/loss.py中,computeloss类用于计算损失函数 # Focal lossg h[fl_gamma] # focal loss gammaif g > 0:BCEcls, BCEobj FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)其中这一段就是开启Focal loss的关键!!&…...
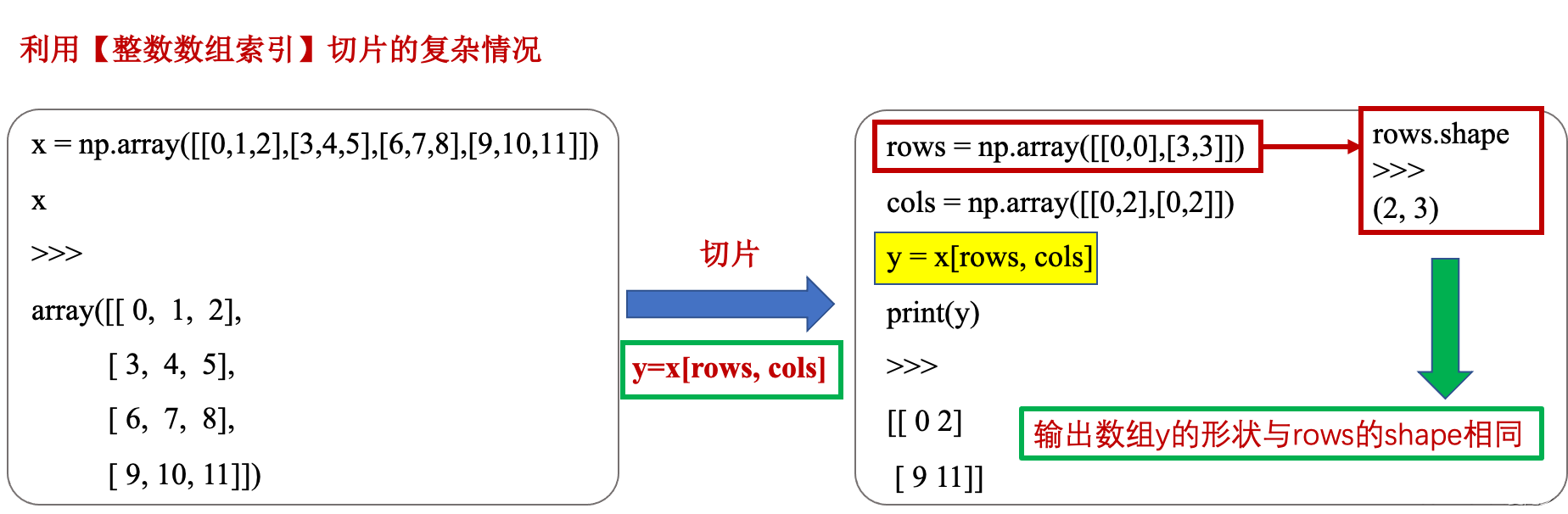
Python中数组切片的用法详解
Python中数组切片的用法详解一、python中“::-1”代表什么?二、python中“:”的用法三、python中数组切片三、numpy中的整数数组索引四、numpy中借助【切片 : 或 …与索引数组】组合进行复杂切片五、布尔索引六、花式索引一、python中“::-1”代表什么? …...
python 安装whl文件
前言 WHL文件是以Wheel格式保存的Python安装包,Wheel是Python发行版的标准内置包格式。在本质上是一个压缩包,WHL文件中包含了Python安装的py文件和元数据,以及经过编译的pyd文件,这样就使得它可以在不具备编译环境的条件下&#…...
Pycharm中安装pytorch
配置虚拟环境 为什么要安装虚拟环境?虚拟环境:把一部分内容独立出来,称之为容器。在容器中,安装我们自己想要的东西,比如不容版本的依赖包。各容器之间相互独立,互不影响。比如下载完 Anaconda 之后&#…...
Package | 解决 module ‘cv2‘ has no attribute ‘gapi_wip_gst_GStreamerPipeline‘
. 问题背景 由于这个问题出现了两回,决定记录一下。实验背景是使用opencv python库进行数据预处理,遇到报错信息如下: “ import cv2 File “/opt/conda/lib/python3.8/site-packages/cv2/init.py”, line 181, in bootstrap() File “/op…...
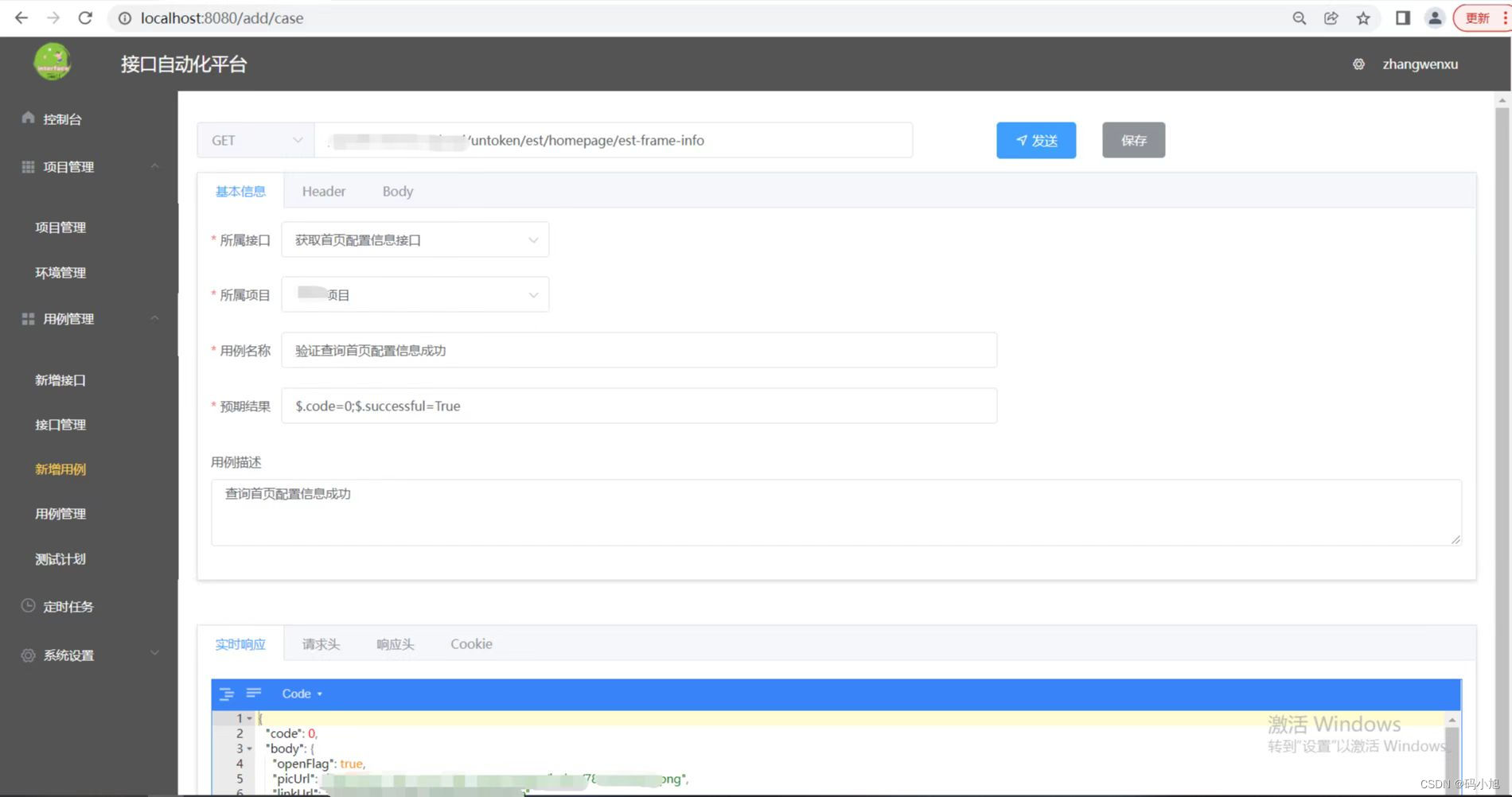
如何在项目中搭建python接口自动化框架?
文章目录前言一、框架目录介绍1、common模块读取Excel代码读取yaml代码(支持场景关联)jsonpath断言封装代码requests二次封装(get、post)configparser读取配置文件递归遍历字典常用方法log日志封装2、conf模块3、data模块4、case模…...
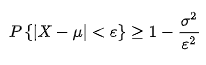
应用统计432考研复试复试提问总结精简版【一】
一、区间估计与假设检验的联系与区别 联系:二者利用样本进行推断,都属于推断统计区别: 原理: 前者是基于大概率,后者基于小概率;统计量:前者是构造枢轴量(不含未知参数,…...
Pytorch模型量化
在深度学习中,量化指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的bit来完成原本以浮点数完成的计算。这么做的好处主要有如下几点: 更少的模型体积,接近4倍的减少;可以更快的计算,由于…...

已解决Encountered error while trying to install package.> lxml
已解决(pip安装第三方模块lxml模块报错)Building wheels for collected packages: lxml Building wheel for lxml (setup.py) … error error: subprocess-exited-with-error python setup.py bdist_wheel did not run successfully. note: This error o…...

距离度量 —— 闵可夫斯基距离(Minkowski Distance)
Python学习系列文章:👉 目录 👈 文章目录一、概述二、计算公式1. 闵氏距离公式2. 闵氏距离的参数 p3. 闵氏距离的缺点一、概述 闵可夫斯基距离 (Minkowski Distance),也被称为 闵氏距离。它不仅仅是一种距离,而是将多…...
python(模块)xlwt
目录一、xlwt简介二、xlwt语法1、模块安装2、模块导入3、向xls文件中写入内容4、设置写入文件的格式4.1 字体设置(font)4.2 背景颜色设置(pattern)4.3 边框设置(borders)4.4 对齐方式设置(align…...

Pytorch中torch.unsqueeze()和torch.squeeze()函数解析
一. torch.squeeze()函数解析 1. 官网链接 torch.squeeze(),如下图所示: 2. torch.squeeze()函数解析 torch.squeeze(input, dimNone, outNone) squeeze()函数的功能是维度压缩。返回一个tensor(张量),其中 input…...
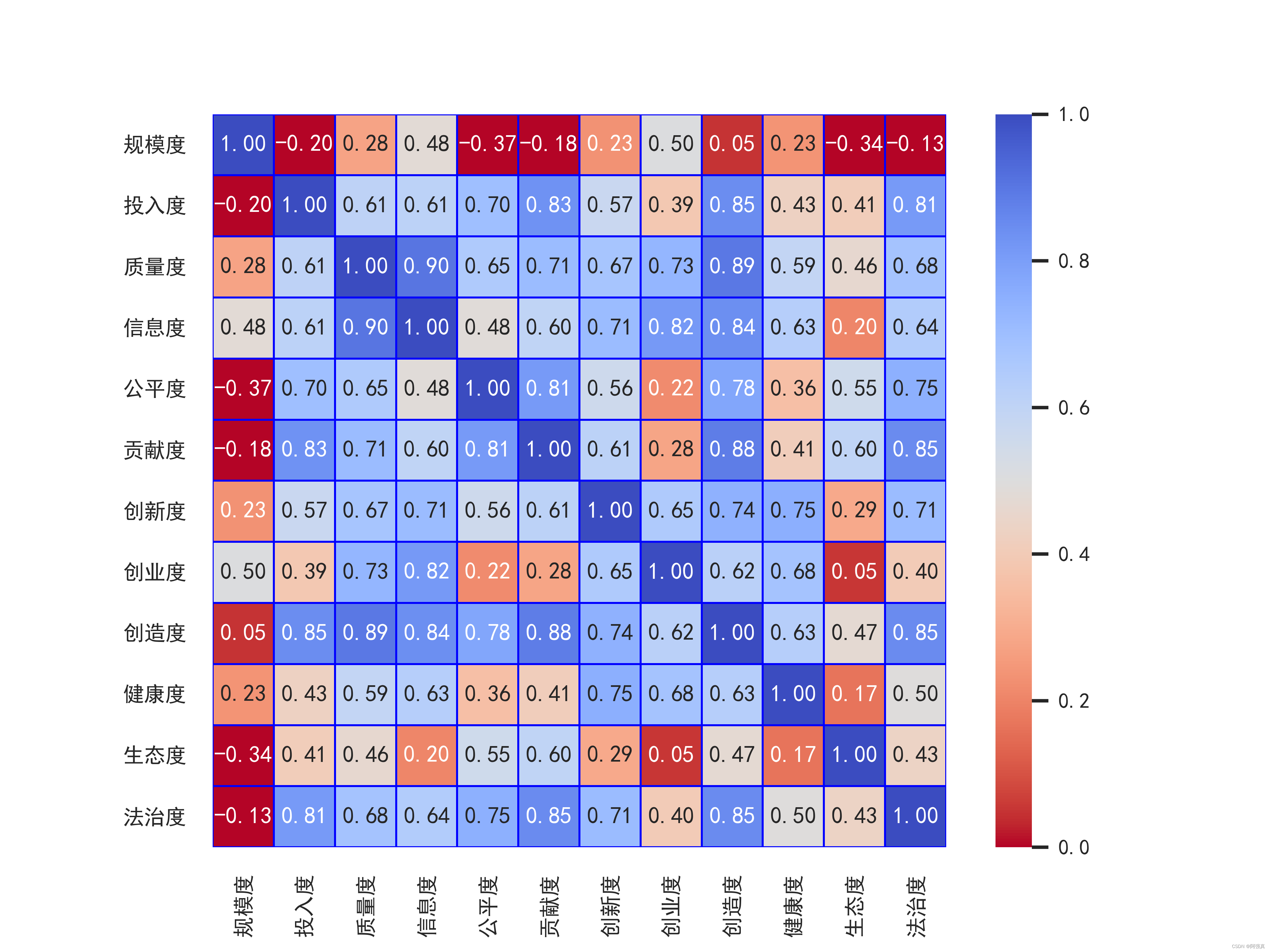
python绘制相关系数热力图
python绘制相关系数热力图一.数据说明和需要安装的库二.准备绘图三.设置配色,画出多幅图全部代码:本文讲述如何利用python绘制如上的相关系数热力图一.数据说明和需要安装的库 数据是31个省市有关教育的12个指标,如下所示。,在文…...
DeepSpeed使用指南(简略版)
现在的模型越来越大,动辄几B甚至几百B。但是显卡显存大小根本无法支撑训练推理。例如,一块RTX2090的10G显存,光把模型加载上去,就会OOM,更别提后面的训练优化。 作为传统pytorch Dataparallel的一种替代,D…...
【Python】tqdm 介绍与使用
文章目录一、tqdm 简介二、tqdm 使用1. 基于迭代对象运行: tqdm(iterator)2. tqdm(list)3. trange(i)4. 手动更新参考链接一、tqdm 简介 tqdm 是一个快速,可扩展的 Python 进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装…...
Pytorch机器学习(十)—— 目标检测中k-means聚类方法生成锚框anchor
Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 目录 Pytorch机器学习(十)—— YOLO中k-means聚类方法生成锚框anchor 前言 一、K-means聚类 k-means代码 k-means算法 二、YOLO中使用k-means聚类生成anchor 读取VO…...
Python的占位格式符
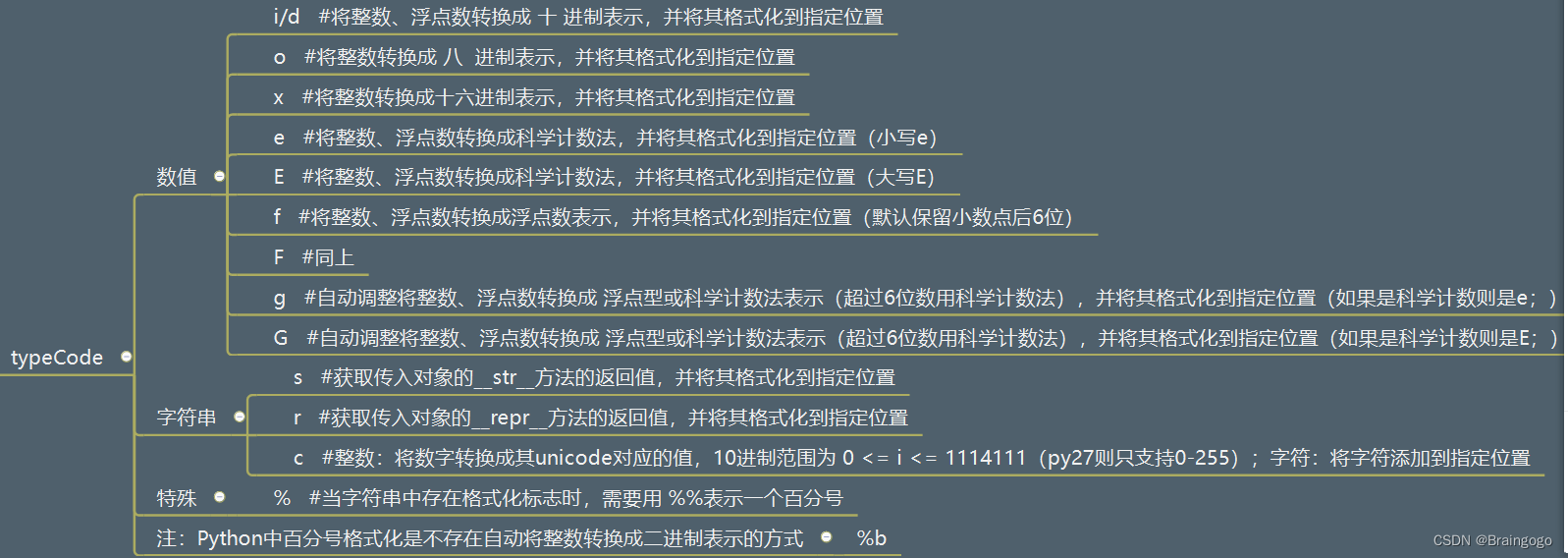
对于print函数里的语句 print("我的名字是%s, 年龄是%d"%(name, age)) 中的%s和%d叫做占位符,它们的完整形态是 %[(name)][flags][width][.precision]typecode 其中带有[]的前缀都是可以省略的。 [(name)]: (name)表示, 根据, 制定的名称(…...
关于sklearn库的安装
对于安装sklearn真的是什么问题都被我遇到了 例如pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(hostfiles.pythonhosted.org, port443): Read timed out.遇到了 这种也遇到了Requirement already satisfied: numpy in c:\users\yjq\appdata\roamin…...
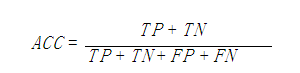
accuracy_score函数
1.acc计算原理 sklearn中accuracy_score函数计算了准确率。 在二分类或者多分类中,预测得到的label,跟真实label比较,计算准确率。 在multilabel(多标签问题)分类中,该函数会返回子集的准确率。如果对于一…...
怎么成为稚晖君?
如何成为IT大佬稚晖君——电子系统设计应具备的基本技能和方法论 快速提高电子技术的必经之路_一些老生常谈的道理 嵌入式AI入坑经历 稚晖君软件硬件开发环境总结 首先,机器学习深度学习这些和硬件是两个领域的内容,个人不建议一起学,注意力…...

Pandas库
Pandas是python第三方库,提供高性能易用数据类型和分析工具。Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用。pandas库引用: import pandas as pd 包括两个数据类型:Series(相当于一维数据类型)&…...

通过两道一年级数学题反思自己
背景 做完这两道题我开始反思自己,到底是什么限制了我?是我自己?是曾经教导我的老师?还是我的父母? 是考试吗?还是什么? 提目 1、正方体个数问题 2、相碰可能性 过程 静态思维: …...
深度学习—卷积神经网络(CNN)全笔记,附代码
本文内容为哔站学习笔记【卷积神经网络-CNN】深度学习(唐宇迪带你学AI):卷积神经网络理论详解与项目实战,计算机视觉,图像识别模块实战_哔哩哔哩_bilibili 目录 深度学习基础 什么是深度学习? 机器学习流…...
Building wheel for mmcv-full (setup.py) ... error解决办法!
mmdetection 安装后,根据官方给的程序安装mmcv时,出现:Building wheel for mmcv-full (setup.py) … error 环境:CUDA11.3, Pytorch1.11 安装根据官网给的安装程序:pip install mmcv-full -f https://download.openmm…...