python接口自动化测试(一)
一.既然我们有这些的接口测试工具,为什么要做接口做自动化?
1、敏捷开发,接口一般数量很大,团队实现接口测试,版本控制。
2、功能太死板,有些接口完全无法实现(复杂的加密接口,签名接口等)
3、接口项目当中有多种不同协议的接口。
4、排错,定位接口问题不方便,结合抓包实现。
5、没有办法生成美观的报告。
6、多接口串联,数据库验证,日志监控。
7、有些公司做web自动化+接口自动化。
二、python+requests模块
requests第三方库,主要用于发送http请求,做接口自动化。
#安装
pip install requests
三、接口自动化之requests全局观
| 请求 | |
|---|---|
| requests. get() | 发送get请求 |
| requests. post() | 发送post请求 |
| requests. delete() | 发送delete请求 |
| requests .put() | 发送put请求 |
| requests. request() | 最核心的方法 |
import requests
rep = requests.request();
| 响应 | |
|---|---|
| rep.text | 返回字符串的数据(文本格式) |
| rep.content | 返回字节格式的数据(图片、文件) |
| rep.json() | 返回字典格式的数据(json格式) |
| rep.status_code | 状态码 |
| rep.reason | 返回状态信息 |
| rep.cookies | 返回cookie信息 |
| rep.encoding | 返回编码格式 |
| rep.headers | 返回响应头信息 |
四、接口实战
请求方式:get post put delete
请求参数类型: 键值对,JSON格式,文件格式
unittest、pytest管理用例框架:
前提是要安装pytest
pip install pytest
pytest默认规则:
1.py文件必须以test _ 开头或者 _ test结尾。
2类名必须以 Test 开头
3.测试用例必须以 test_ 开头
注意:
1、get请求通过params传递参数。
2、post请求通过json或者data传参。他们的区别是什么?
data
数据报文: dict字典类型,那么默认情况下请求头: application/x-www-form-urlencoded,
表示以form表单的方式传参,格式: a=1&b=2&c=3
数据报文: str类型,那么默认情况下: text/plain(如果是字典格式需要转换成str格式传参)
json
数据报文:不管是dict还是str类型,默认都是application/json ,格式: ({"a":1,"b".2)
data = {"tag": {"id": 134, "name": "广东人"}}
rep = requests.post(url=url, data=json.dumps(data))
json.dumps(data)序列化 把字典格式的数据转换成str格式.
json.loads(data)反序列化 把str格式转换成字典格式
总结:
data只能传递简单的只有键值对的dict或者是str格式。
json一般只能传dict格式(简单和嵌套都可以)
#3、文件传参files,且一定要open
data={
"media":open(r"E:\shu.png","rb")
}
rep = requests.post(url=url, files=data)
# 以下代码运行不起来,但是写法没错
import pytest
import requests
class TestSendRequest:
access_token=""
def test_get_token(self):
# 发送get请求
url = "https://api.weixin.qq.com/cgi-bin/token"
data = {
"grant_type": "client_credential",
"appid": "自己找素材",
"secret": "自己找素材"
}
rep = requests.get(url=url, params=data)
print(rep.json())
TestSendRequest.access_token = rep.json()["access_token"]
def test_edit_flag(self):
# 发送post请求(data和json只需要传一个,data和json的区别)
url = "https://api.weixin.qq.com/cgi-bin/token/tags/update?access_token=" + TestSendRequest.access_token + ""
data = {"tag": {"id": 134, "name": "广东人"}}
rep = requests.post(url=url, json=data)
print(rep.json())
if __name__ == '__main__':
#-vs 打印调试信息
pytest.main(['-vs'])
1、cookie鉴权: 网页的接口基本上都要做cookie鉴权。(不常用)
(给了token和请求头,但是请求还是fail,需要做cookie鉴权)
import re
import pytest
import requests
class TestSendRequest:
cks=""
#需要带请求头的接口以及需要cookie关 联的接口如何测试?
def test_start(self):
url = "http://47.107.116.139/phpwind/"
rep=requests.get(url=url)
print (rep.text)
#通过正则表达式获取鉴权码
TestSendRequest.csrf_token= re.search( 'name="csrf_token" value="(.*?)"', rep.text)[1]
print(TestSendRequest.csrf_token)
TestSendRequest.cks=rep.cookies
#请求需要带请求头的接口
def test_login(self) :
url = "http://47.107.116.139/phpwind/index.php?m=u&c=login&a=dorun"
data = {
"username" : "msxy",
"password" :"msxy",
"csrf_token": TestSendRequest.csrf_token,
"backurl": "http://47. 107.116.139/ phpwind/",
"invite": ""
}
headers = {
"Accept": "application/json,text/ javascript, / ; q=0.01",
"X一Requested-With" : "XMLHttpRequest"
}
rep = requests. post (url=url, data=data , headers=headers,cookies=TestSendRequest.cks )
print (rep.json() )
if __name__ == '__main__':
#-vs 打印调试信息
pytest.main(['-vs'])
2、通过session实现cookie鉴权(常用)
import re
import pytest
import requests
class TestSendRequest:
csrf_token=""
session = requests.session()
#需要带请求头的接口以及需要cookie关 联的接口如何测试?
def test_start(self):
url = "http://47.107.116.139/phpwind/"
rep=requests.get(url=url)
print (rep.text)
#通过正则表达式获取鉴权码
TestSendRequest.csrf_token= re.search( 'name="csrf_token" value="(.*?)"', rep.text)[1]
print(TestSendRequest.csrf_token
#请求需要带请求头的接口
def test_login(self) :
url = "http://47.107.116.139/phpwind/index.php?m=u&c=login&a=dorun"
data = {
"username" : "msxy",
"password" :"msxy",
"csrf_token": TestSendRequest.csrf_token,
"backurl": "http://47. 107.116.139/ phpwind/",
"invite": ""
}
headers = {
"Accept": "application/json,text/ javascript, / ; q=0.01",
"X一Requested-With" : "XMLHttpRequest"
}
rep = TestSendRequest.session.post (url=url, data=data , headers=headers)
print (rep.json() )
if __name__ == '__main__':
#-vs 打印调试信息
pytest.main(['-vs'])
接口自动化测试框架封装
第一步 统一请求方式
rep=requests.request(请求方式,地址,参数…)
def test_get_token(self):
# 发送get请求
url = "https://api.weixin.qq.com/cgi-bin/token"
data = {
"grant_type": "client_credential",
"appid": "wx6b11b3efd1cdc290",
"secret": "106a9c6157c4db5f602991873819529d"
}
rep = requests.request("get",url=url, params=data)
print(rep.json())
TestSendRequest.access_token = rep.json()["access_token"]
Pytest全局观
1、它可以和所有的自动化测试工具selenium、requests、appium结合实现web自动化、接口自动化以及app自动化;
2、跳过用例、失败用例重跑;
3、结合allure生成美观的测试报告;
4、和Jenkins持续集成;
5、有很多的强大插件。
1、常用操作(一)
项目的在根目录下创建requirements.txt文件
注意:(#是我自己为了方便看代码的解释,复制请删除)
#pytest框架
pytest
#生产html测试报告
pytest-html
#多线程运行
pytest-xdist
#改变测试用例的执行顺序
pytest-ordering
#失败用例重跑
pytest-rerunfailures
#生产allure测试报告
allure-pytest
#在命令窗口使用 安装这个文件里面的插件
pip install -r requirements.txt
2、常用操作(二)运行方式
在根目录下创建python.ini文件
#提示这是pytest文件
[pytest]
#执行方法,-m "smoke" 只执行冒烟用例,要想执行其他用例 删除-m以及后面的
addopts = -vs -m "smoke"
#文件路径
testpaths = ./ui
#文件以test_开头
python_files = test_*.py
#类名以Test开头
python_classes = Test*
#用例以test_开头
python_functions = test_*
#对用例进行分组 在用例上@pytest.mark.smoke,就执行加了这样的用例
markers =
smoke:maoyan
若没有建立python.ini文件
在主程序中输出结果如下表达:
if __name__ == '__main__':
'''
v 输出更加详细的运行信息
-s 输出调试信息
-n 多线程运行
--reruns数字 失败用例重跑
--html='报告的路径'
'''
#写了pytest.ini
pytest.main()
# pytest.main(['-vs','-n=2'])
# pytest.main(['-vs','--reruns=2'])
# pytest.main(['-vs','--html=./report.html'])
3、常用操作(三)前置后置
setUp()/tearDown() 在每个用例之前/之后执行一次
setUp_class()/tearDown_class() 在每个类之前/之后执行一次
实现部分的前置
部分前置:
@pytest.fixture(scope=“作用域”,params=“数据驱动”,autouse=“自动执行”,ids=“自定义参数名”,name=“重命名”)
作用域: function(默认)、class、module、package/session
import requests
import re
import pytest
#部分前置
@pytest.fixture(scope="function")
def conn_database():
print("连接数据库")
#可以通过yield唤醒teardown的功能,就是返回,yield和return都有返回数据的意思
#但是yield返回多次及多个数据,return只返回一次且return后面的代码不执行
yield
print("关闭数据库")```
class Test:
def test_edit_flag(self,conn_database):
url=''
data={"tag":{"id":134,"name":"小李"}}
rep=Test.session.request('post',url,json=data
一般情况下:
@pytest.fixture()和conftest.py文件一起使用
conftest.py文件
1.conftest.py:文件是单独存放**@pytest.fixture()**的方法,可以实现多个py文件共享前置配置
2.conftest.py:不需要导入直接使用,可以直接使用
3.conftest.py:可以有多个,也可以有多个不同层级
import pytest
@pytest.fixture(scope="function")
def conn_database():
print("连接数据库")
yield
print("关闭数据库")
4、接口自动化测试框架封装(接口关联封装)
1、创建 common 文件夹,创建 yaml_util.py 文件
import os
import yaml
class YamlUtil:
#读取extract.yml文件
def read_extract_yaml(self,key):
with open(os.getcwd()+"./extract.yml",mode="r",encoding="utf-8") as f:
value=yaml.load(stream=f,Loader=yaml.FullLoader)
return value[key]
#写入extract.yml文件
def read_extract_yaml(self,data):
with open(os.getcwd()+"./extract.yml",mode="w",encoding="utf-8") as f:
yaml.dump(data=data,stream=f,allow_unicode=True)
#清除extract.yml文件
def clearn_extract_yaml(self):
with open(os.getcwd()+"./extract.yml",mode="w",encoding="utf-8") as f:
f.truncate()
2、创建extract.yml文件
3、创建conftest.py文件
import pytest
from common.yaml_util import YamlUtil
#autouse 自动执行,无需调用
#scope 作用域(session)
@pytest.fixture(scope="session",autouse=True)
def clearn_Yaml():
YamlUtil().clearn_extract_yaml()
5、pytest断言
# result ==>{"errcode": 0,"message":"数据返回成功"}
result = rep.json()
# 第一种
assert result['errcode'] == 0
#第二种
assert 'errcode' in rep.json()
#比较多个或者用and
assert 'errcode' in rep.json()
assert 'message' in rep.json()
assert 'errcode' in rep.json() and 1==1
6、allure-pytest生成allure测试报告
6.1、官网下载allure:
https://github.com/allure-framework/allure2/releases
下载 .zip 的包,放到没有中文的路径下,然后把E:\allure-2.13.7\bin配置到环境变量的path里面哦
6.2、重启pycharm 通过:allure --version验证(若没有打开pycharm,则跳过)
6.3、执行命令
(1)在temp目录下生成临时的json文件的报告,在pytest.ini文件下写 - -alluredir ./temp
在当前目录下创建temp目录
[pytest]
#执行方法
addopts = -vs --alluredir ./temp
#文件路径
testpaths = ./ui
#文件以test_开头
python_files = test_*.py
#类名以Test开头
python_classes = Test*
#用例以test_开头
python_functions = test_*
(2)通过临时的json文件生成allure报告(在reports目录下),在all.py文件写
os.system(“allure generate temp -o reports --clean”)
在当前目录下创建 reports目录
import pytest
if __name__ == '__main__':
pytest.main()
os.system("allure generate temp -o reports --clean")
6.4、allure报告的定制
相关文章:
【毕业设计】基于大数据的抖音短视频数据分析与可视化 - python 大数据 可视化
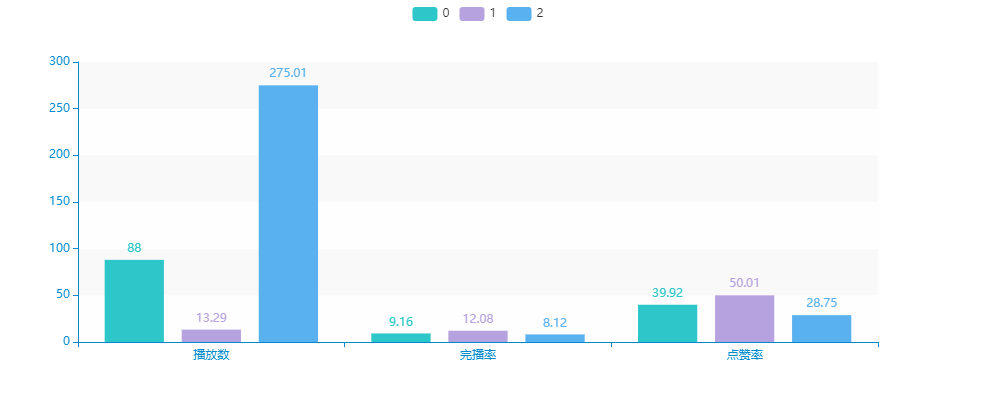
文章目录0 前言1 课题背景2 数据清洗3 数据可视化地区-用户观看时间分界线每周观看观看路径发布地点视频时长整体点赞、完播4 进阶分析相关性分析留存率5 深度分析客户价值判断5 最后0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的…...
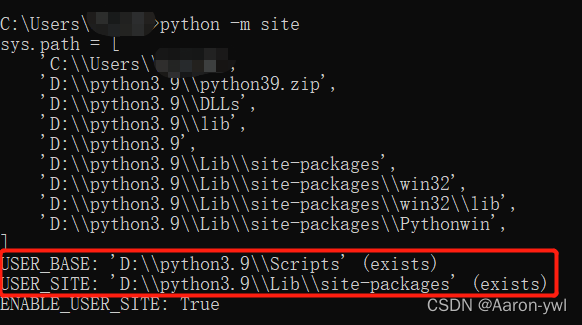
修改pip安装路径的方法
当我们需要安装python的第三方库时,通常都是打开cmd输入pip install xxx去安装。 但是默认安装路径在C盘,极大占用空间,看看我的C盘空间,已经不足了!!! 所以我们修改pip的安装路径这个步骤是很…...
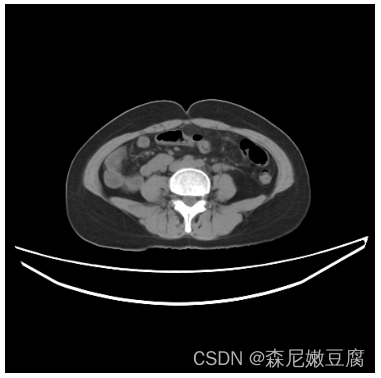
Python CT图像预处理——nii格式读取、重采样、窗宽窗位设置
文章目录nii格式CT数据读取读写nii格式文件查看重采样窗宽窗位设置方法一:手动设置窗宽窗位方法二:nii格式CT数据读取 遇到nii格式的CT数据,可以通过nibabel包进行数据的读、写、查看等操作。下面列出常见操作。 读写nii格式文件 nibabel读…...

python学生成绩管理系统【完整版】
✅作者简介:大家好我是hacker707,大家可以叫我hacker,新星计划第三季python赛道Top1🏆 📃个人主页:hacker707的csdn博客 🔥系列专栏:python 💬推荐一款模拟面试、刷题神器Ǵ…...
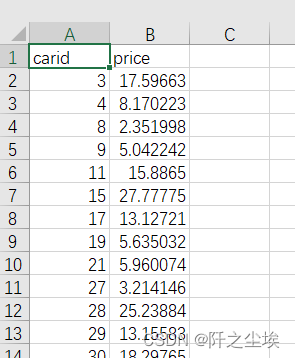
Python数据分析案例07——二手车估价(机器学习全流程,数据清洗、特征工程、模型选择、交叉验证、网格搜参、预测储存)
案例背景 本次案例来自2021年matchcop大数据竞赛A题数据集。要预测二手车的价格。训练集3万条数据,测试集5千条。官方给了二手车的很多特征,有的是已知的,有的是匿名的。要求就是做模型去预测测试集的二手车的价格。价格是一个连续变量&…...
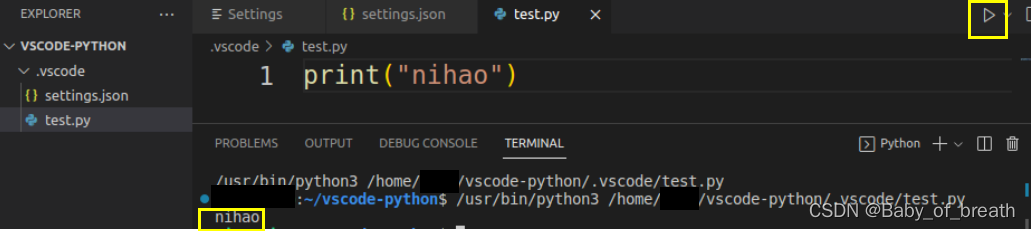
vscode运行python程序
系统:Ubuntu18.04 一、安装python插件 打开vscode,找到最右侧的Extensions,在上方搜索栏搜索python如大红框所圈,点击Install,安装即可。 二、创建python项目(.py存放的文件夹) 笔者习惯存放…...
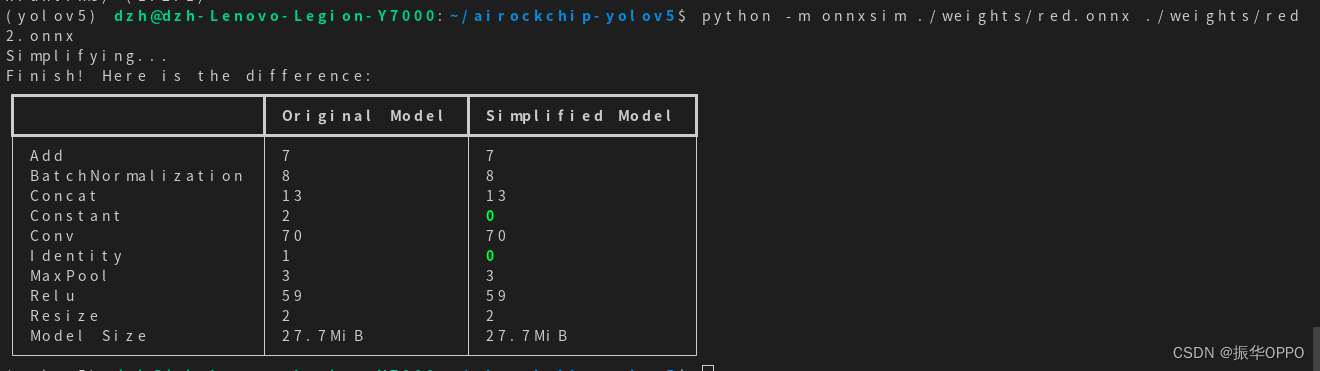
【yolov5】pytorch模型导出为onnx模型
博主想拿官网的yolov5训练好pt模型,然后转换成rknn模型,然后在瑞芯微开发板上调用模型检测。但是官网的版本对npu不友好,所以采用改进结构的版本: 将Focus层改成Conv层将Swish激活函数改成Relu激活函数 自带的预训练模型是预测80类…...
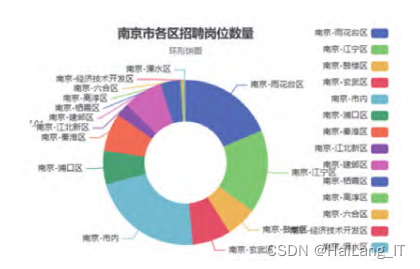
毕业设计-基于大数据招聘岗位可视化系统-python
目录 前言 课题背景和意义 实现技术思路 实现效果图样例 前言 📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科…...
No module named ‘cv2‘ 解决办法 (No module named ‘numpy‘ 等所有报错均可解决)
实在不行可以私信我解决! 1.关于离线pip install 库爆winErro[10061]的问题原因 使用了局域网,没有链接到网络 1.1 解决方法: 1.链接网络 2.假如离线安装 pip install imgaug.whl 库,但是imgaug依赖 shapely库。因此要安装imgaug库之前&…...
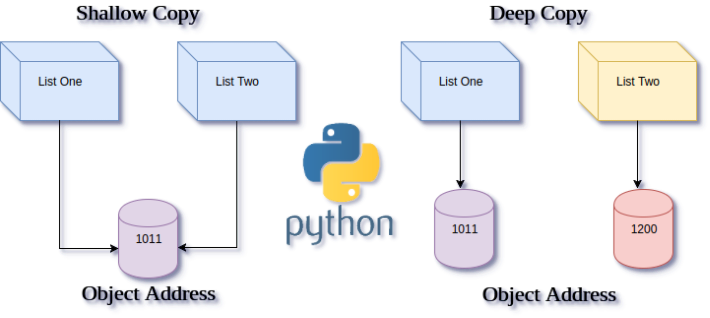
详细分析Python中深浅拷贝的区别
简而言之: 深浅拷贝的区别关键在于拷贝的对象类型是否可变。 我们可以总结出以下三条规则: 对于可变对象来说,深拷贝和浅拷贝都会开辟新地址,完成对象的拷贝而对于不可变对象来说,深浅拷贝都不会开辟新地址ÿ…...
django+drf_haystack+elasticsearch+ik+高亮显示
0.前提准备 环境 1. 准备好django2.2 2. 创建一个app 3.elasticsearch7.5启动 4.可视化工具(实在没有,也没啥) models.py from django.db import models# Create your models here.class Article(models.Model):title models.CharField(verbose_name文章标题, max_length22…...

头歌Python数据框、序列定义及数据处理应用实验闯关
粘贴答案不是目的 把Python学会这才叫做意义 童年的纸飞机 现在终于飞回我手里~~ 文章目录第1关:序列和数据框第2关:外部数据文件读取第3关:逻辑索引、切片方法,groupby 分组计算函数应用第4关:数据框关联操作第5关…...

使用pip下载时提示“You are using pip version 8.1.1, however version 22.1 is available.“
在使用pip install下载其他包时,报了错,如图: 提示:“You are using pip version 8.1.1, however version 22.1 is available. You should consider upgrading via the ‘pip install --upgrade pip’ command.” 根据提示&#…...

YOLOV8-gradcam 热力图可视化 即插即用 不需要对源码做任何修改!
YOLOV8 GradCam 热力图可视化. 本文给大家带来yolov8-gradcam热力图可视化,这个可视化是即插即用,不需要对源码做任何修改喔!给您剩下的不少麻烦! 代码链接:yolo-gradcam 里面还有yolov5和v7的热力图可视化代码&#…...
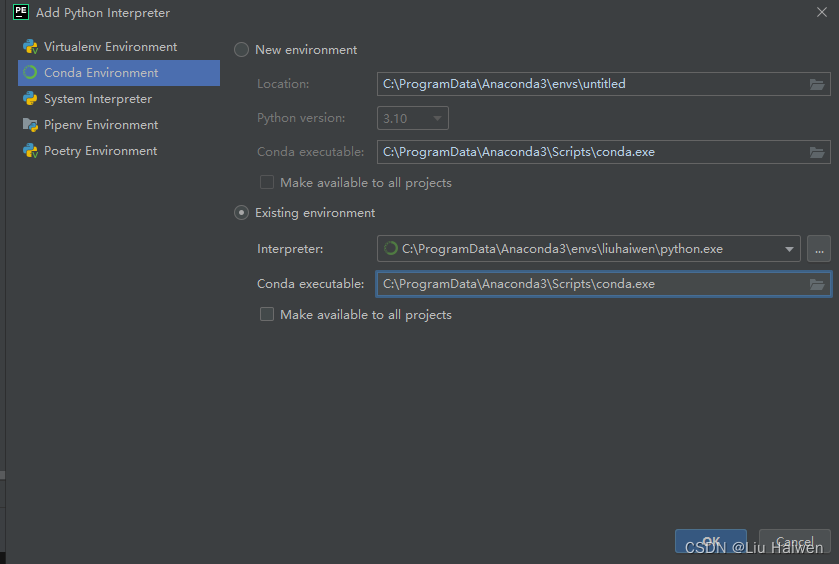
Anaconda创建虚拟环境并在Pycharm中使用创建好的环境
Anaconda创建虚拟环境并在Pycharm中使用创建好的环境1.Anaconda创建虚拟环境2.Pycharm中使用创建好的环境3.2022.12.8更新Anaconda的优势在于可以很方便地管理自己的工具包、开发环境和Python版本,同时还能使用不同的虚拟环境隔离不同要求的项目。假如你已经安装好了…...

python二级题库(百分之九十原题) 刷题软件推荐 第二套
目录 一、选择题 二、基本操作 三、简单应用 四、综合应用 刷题软件(模拟python二级考试): 公众h:露露IT 回复:python二级 一、选择题 1、下列叙述中正确的是()。 A.在栈中,栈…...

【模拟 简易银行系统~python】
目录~python面向对象编程之模拟银行系统相关程序代码如下:运行效果如下:pandas 每日一练:运行结果为:66、绘制sku_cost_prc的密度曲线运行效果为:67、计算后一天与前一天sku_cost_prc的差值运行结果为:68、…...
【YOLOv7/YOLOv5系列改进NO.52】融入YOLOv8中的C2f模块
文章目录 前言一、解决问题二、基本原理三、YOLOv5添加方法四、YOLOv7添加方法五、总结前言 作为当前先进的深度学习目标检测算法YOLOv7,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点…...

PyTorch 单机多GPU 训练方法与原理整理
PyTorch 单机多GPU 训练方法与原理整理 这里整理一些PyTorch单机多核训练的方法和简单原理,目的是既能在写代码时知道怎么用,又能从原理上知道大致是怎么回事儿。 就目前来说,并行训练的方法可以根据的不同的并行对象分为——模型并行和数据…...
anaconda创建、删除虚拟环境指令
使用conda创建、删除虚拟环境指令{\color{Red}使用conda创建、删除虚拟环境指令}使用conda创建、删除虚拟环境指令 使用conda创建、删除虚拟环境指令{\color{Red}使用conda创建、删除虚拟环境指令}使用conda创建、删除虚拟环境指令 一、创建虚拟环境 二、查看虚拟环境 三、激活…...
NCDC气象数据的提取与处理(二):python批量转换isd-lite数据为xlsx
目录 1.完整代码(部分代码参考https://zhuanlan.zhihu.com/p/556150264) 2.工作过程 2.1输入 2.2过程 3.实际效果 本例使用的相关数据及代码可见 链接:https://pan.baidu.com/s/1EYE0U7RrHSGGk3vptZyNVg 提取码:6666 书接上…...
MD5密码实验——Python实现(完整解析版)
文章目录更新:前言实验环境实验内容实验操作步骤1.初始化四个缓冲区2.设置常数表、位移位数等参数3.增加填充4.分组处理5.输出处理实验结果实验心得实验代码MD5-Python.py更新: 感谢评论区的大佬指出错误,现已改进代码 之前的错误在于没有考…...
如何在vscode中下载python第三方库(jieba和wordcloud为例)
本文由来 本来我并不想写文章的,但是我发现,对于一个0基础的小白vscode用户而言,想完整的下载一个第三方库还是存在一定的问题,并且我在搜索文章的时候发现,完全没有小白教程,太难了,所以说我就…...
python安装使用pip安装numpy
相信大家最近都在忙,因为到开学和上班的时候了,我最近也很忙,忙的快要流泪,这不是要考计算机三级了吗!买了好厚一本书,备战过程中,最近洗头一次掉了100根不止的头发,有点恐惧&#x…...
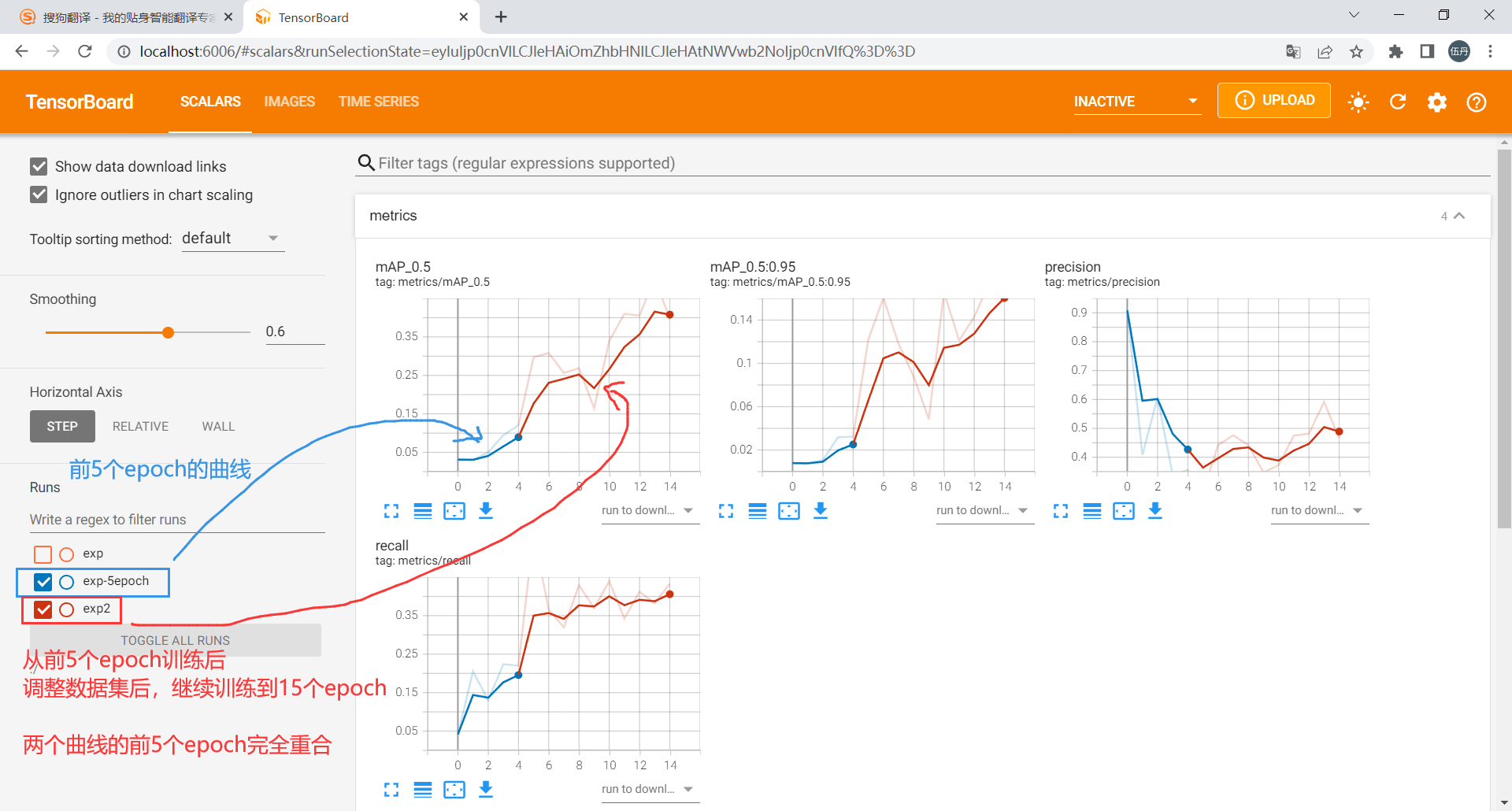
yolov5ds-断点训练、继续训练、先终止训练并调整最终epoch(yolov5同样适用)
目录参考链接1. 训练过程中中断了,继续训练如果觉得数值差不多稳定了,但是距离最终设置的epoch还很远,所以想要停止训练但是又得到yolov5在运行完指定最大epoch后生成的一系列map、混淆矩阵等图2. 训练完原有epoch,但还继续训练&a…...

openCV第一篇
文章目录 前言:计算机眼中的图片 1. 图片的读取与显示 1.1 图片的读取 1.2 显示的图片 1.2.1 显示原始图片 1.2.2 灰度图 1.3 BGR转换成灰度图、RGB 2. 保存图片 3. 视频的读取与显示 4. 截取图像部分 5. 颜色通道提取 6. 边界填充 7. 数值计算 8.…...

基于Python构建机器学习Web应用
目录 一、内容介绍 1.Onnx模型 ①skl2onnx库安装 2.Netron安装 二、模型构建 1.数据加载 2.划分可训练特征与预测标签 3.训练模型 ①第三方库导入 ②数据集划分 ③SVC模型构建 ④精度评价 二、模型转换及可视化 1.参数配置 2.Onnx模型生成 3.可视化模型 四、构…...
python - 密码加密与解密
Python之密码加密与解密 - 对称算法一、对称加密1.1 安装第三方库 - PyCrypto1.2 加密实现二、非对称加密三、摘要算法3.1 md5加密3.2 sha1加密3.3 sha256加密3.4 sha384加密3.5 sha512加密3.6 “加盐”加密由于计算机软件的非法复制,通信的泄密、数据安全受到威胁。…...
百度飞桨PaddleSpeech的简单使用
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型,一些典型的应用示例如下:语音识别、语音翻译 (英译中)、语音合成、标点恢复等。…...
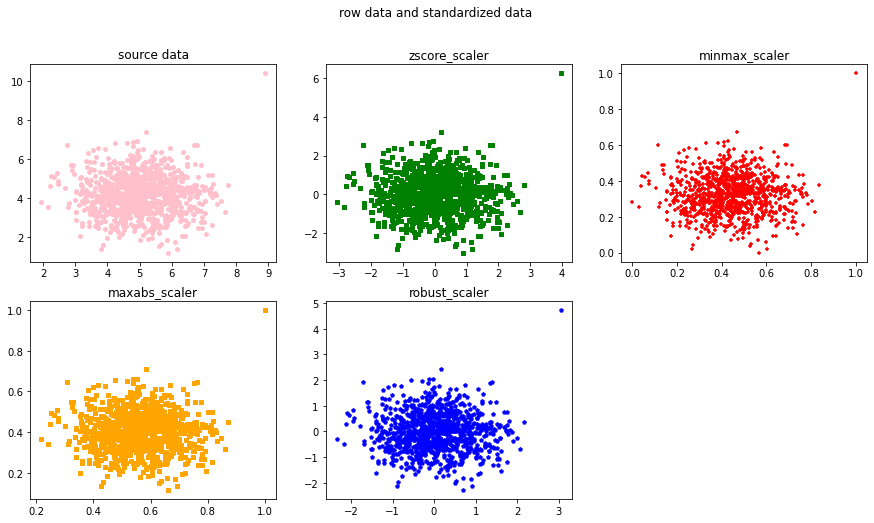
Python数据标准化
目录 一.数据标准化方式 1.实现中心化和正态分布的Z-Score 2.实现归一化的Max-Min 3.用于稀疏数据的MaxAbs 4.针对离群点的RobustScaler 二.Python针对以上几种标准化方法处理数据 三.总结 一.数据标准化方式 1.实现中心化和正态分布的Z-Score Z-Score标准化是基于原…...
Pycharm无法下载汉化包,一招教你搞定
Pycharm无法下载汉化包,一招教你搞定Pycharm直接导入汉化包Pycharm 无法采用自带的插件安装汉化包Pycharm直接导入汉化包 Pycharm 是可以直接导入汉化包的,这为很多初学者省区了不少麻烦。具体就是: 1:点击pycharm界面右上角的设…...

python成功实现“高配版”王者小游戏?【赠源码】
前言 嗨喽~大家好呀,这里是魔王呐 ❤ ~! 本游戏完整源码、素材: 点击此处跳转文末名片获取 咳咳,又是一款新的小游戏,就是大家熟悉的王者~ 来看我用python来实现高(di)配版的王者 是一款拿到代码运行后,…...
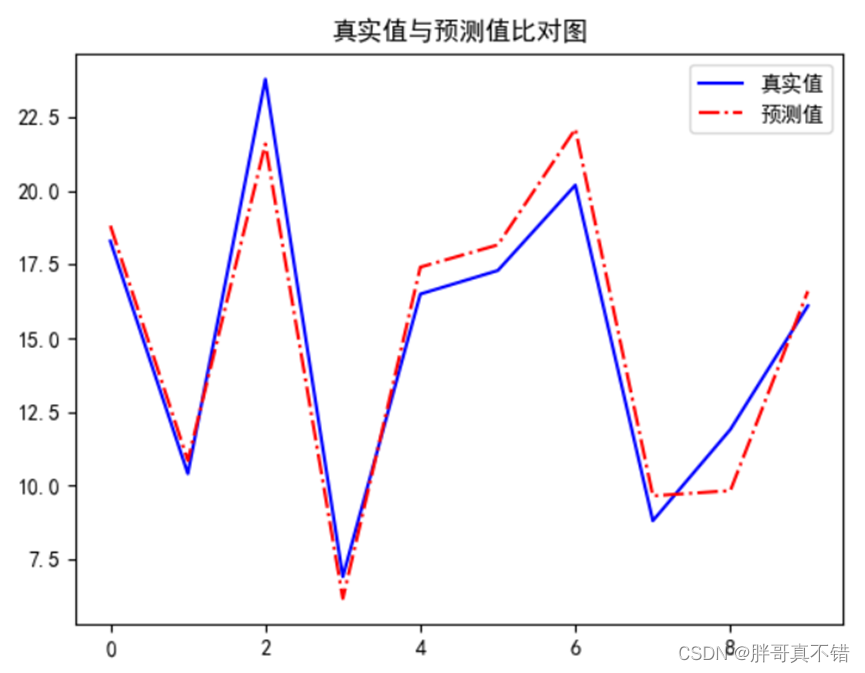
【项目实战】Python实现多元线性回归模型(statsmodels OLS算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 回归问题是一类预测连续值的问题,而能满足这样要求的数学模型称作回归模型,本项…...
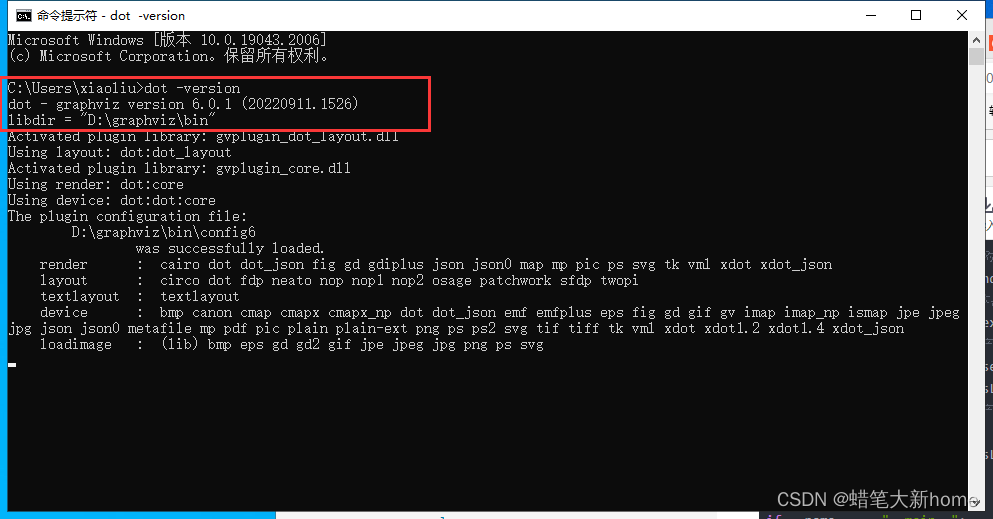
graphviz安装教程(2022最新版)初学者适用
1、首先在官网下载graphviz 下载网址:https://www.graphviz.org/download/ 2、安装。 打开第一步已经下载好的软件。点击下一步,在安装路径选择时可将安装路径修改为 D:\graphviz 接着一直点下一步,即可安装完成。 3、配置环境变量 右键…...

【Windows】搭建Pytorch环境(GPU版本,含CUDA、cuDNN),并在Pycharm上使用(零基础小白向)
文章目录前言一、安装CUDA1、检查电脑是否支持CUDA2、下载并安装CUDA3、下载并安装cuDNN二、安装Pytorch1、安装Anaconda2、切换清华镜像源3、创建环境并激活4、输入Pytorch安装命令5、测试三、在Pycharm上使用搭建好的环境参考文章前言 本人纯python小白,第一次使用…...
Tensorflow与CUDA、cudnn版本对应关系
不同版本的Tensorflow需对应不同的CUDA和cudnn版本,否者容易安装失败。可按下图所示,根据想要安装的Tensorflow版本,选择对应版本的CUDA和cudnn。 其中CUDA的下载链接为: CUDA Toolkit Archive | NVIDIA Developer cudnn下载链…...
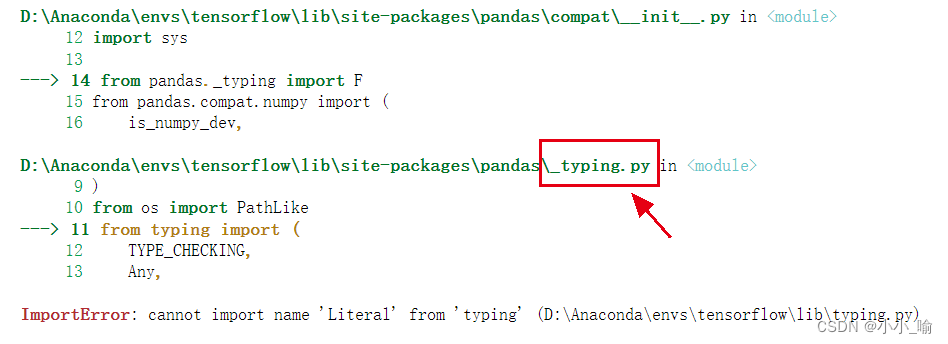
ImportError: cannot import name ‘Literal‘ from ‘typing‘ (D:\Anaconda\envs\tensorflow\lib\typing.py)
报错背景: 因为安装tensorflow-gpu版本需要,我把原来的新建的anaconda环境(我的名为tensorflow)中的python3.8降为了3.7。 在导入seaborn包时,出现了以下错误: ImportError: cannot import name Literal …...

100天精通Python(数据分析篇)——第67天:Pandas数据连接、合并、加入、添加、重构函数(merge、concat、join、append、stack、unstack)
文章目录 一、数据连接(pd.merge)1. left、right2. how3. on4. left_on、right_on5. sort6. suffixes7. left_index、right_index二、数据合并(pd.concat)1. index 没有重复的情况2. index 有重复的情况3. DataFrame合并时同时查看行索引和列索引有无重复三、数据加入(pd.…...
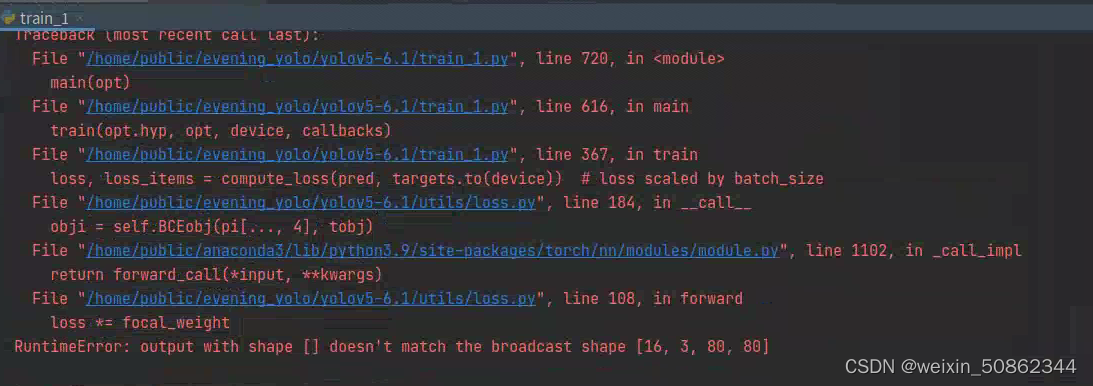
yolov5 优化系列(三):修改损失函数
1.使用 Focal loss 在util/loss.py中,computeloss类用于计算损失函数 # Focal lossg h[fl_gamma] # focal loss gammaif g > 0:BCEcls, BCEobj FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)其中这一段就是开启Focal loss的关键!!&…...
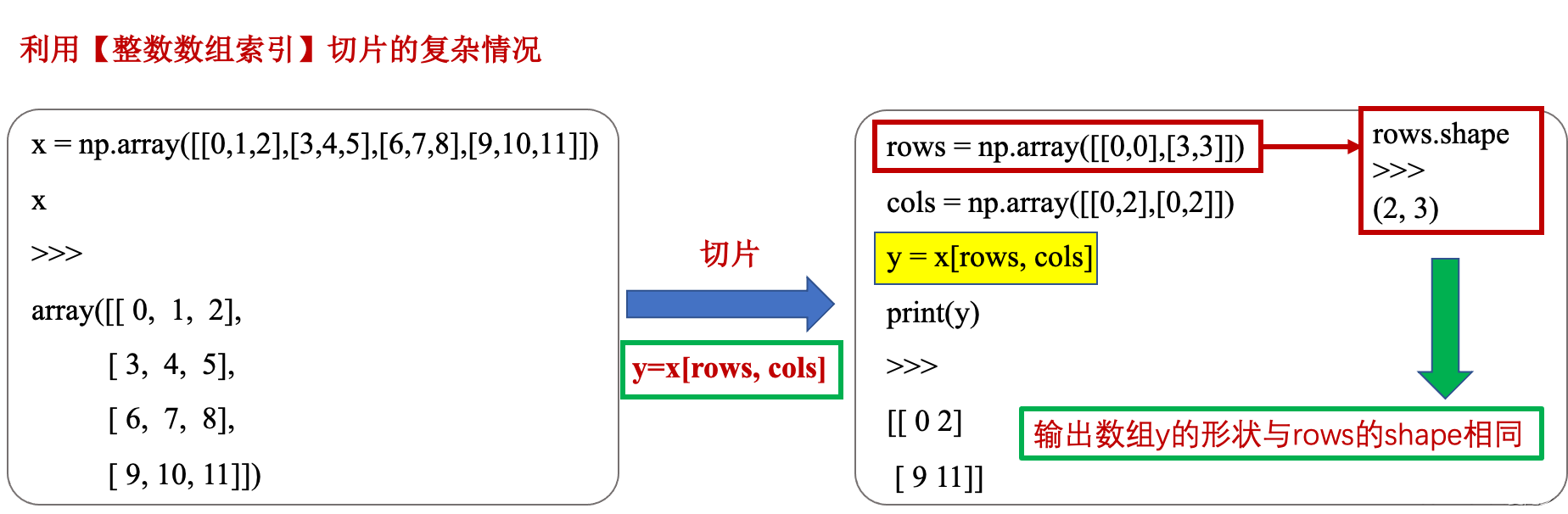
Python中数组切片的用法详解
Python中数组切片的用法详解一、python中“::-1”代表什么?二、python中“:”的用法三、python中数组切片三、numpy中的整数数组索引四、numpy中借助【切片 : 或 …与索引数组】组合进行复杂切片五、布尔索引六、花式索引一、python中“::-1”代表什么? …...
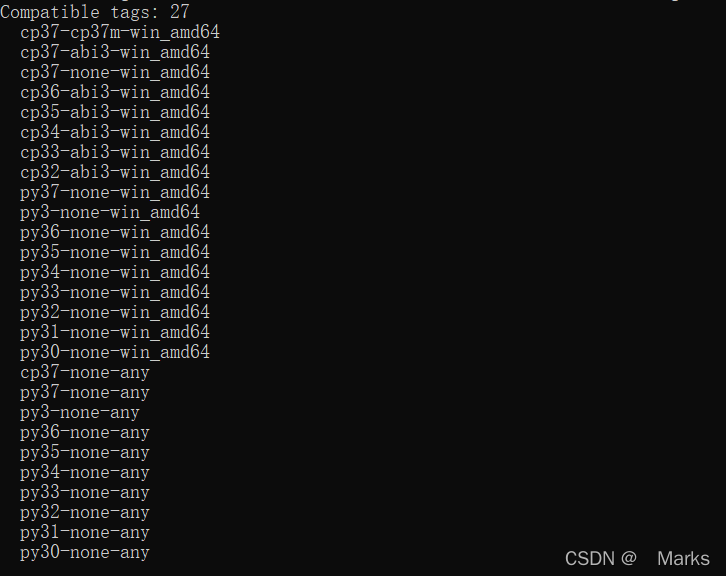
python 安装whl文件
前言 WHL文件是以Wheel格式保存的Python安装包,Wheel是Python发行版的标准内置包格式。在本质上是一个压缩包,WHL文件中包含了Python安装的py文件和元数据,以及经过编译的pyd文件,这样就使得它可以在不具备编译环境的条件下&#…...
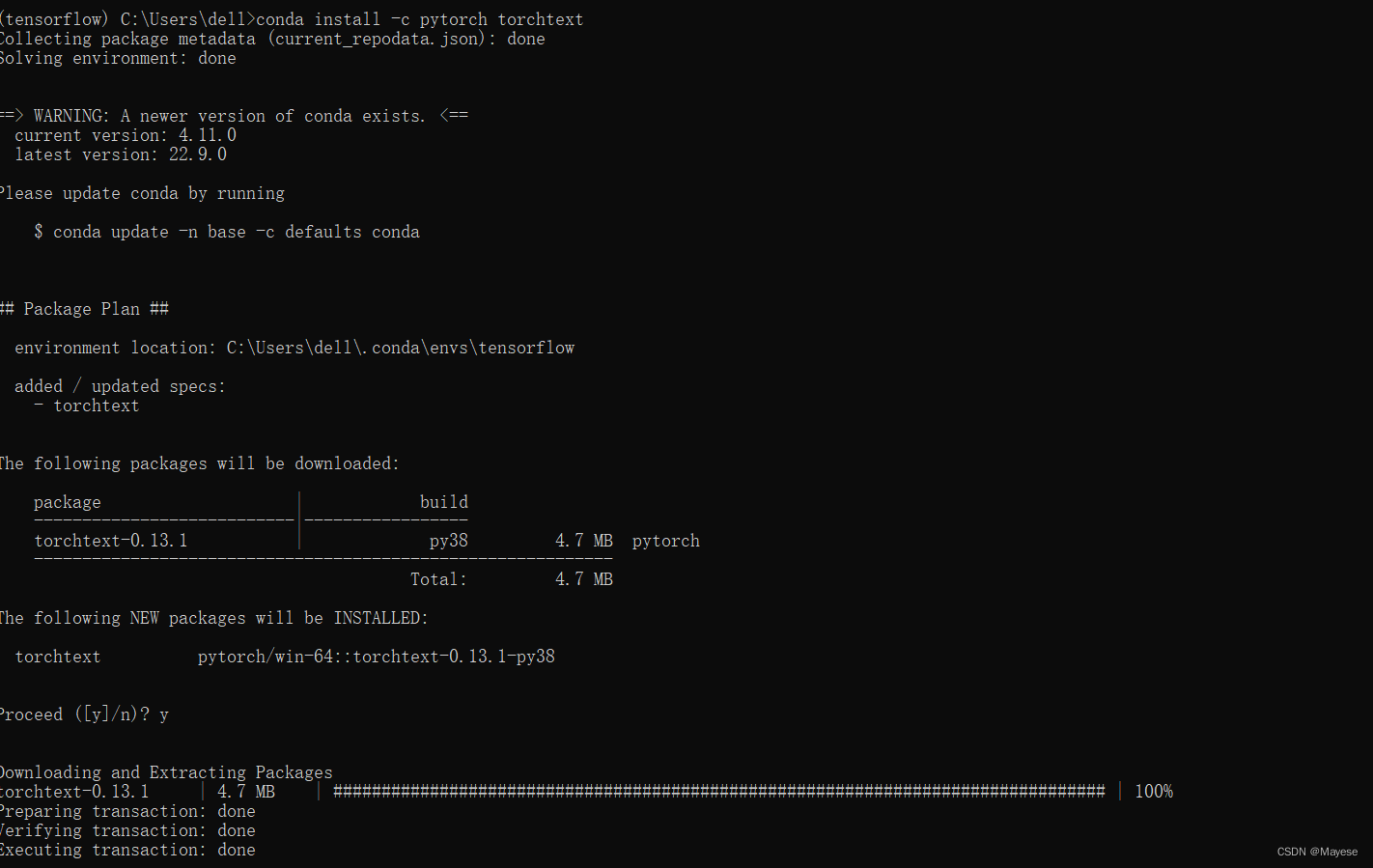
Pycharm中安装pytorch
配置虚拟环境 为什么要安装虚拟环境?虚拟环境:把一部分内容独立出来,称之为容器。在容器中,安装我们自己想要的东西,比如不容版本的依赖包。各容器之间相互独立,互不影响。比如下载完 Anaconda 之后&#…...
Package | 解决 module ‘cv2‘ has no attribute ‘gapi_wip_gst_GStreamerPipeline‘
. 问题背景 由于这个问题出现了两回,决定记录一下。实验背景是使用opencv python库进行数据预处理,遇到报错信息如下: “ import cv2 File “/opt/conda/lib/python3.8/site-packages/cv2/init.py”, line 181, in bootstrap() File “/op…...
如何在项目中搭建python接口自动化框架?
文章目录前言一、框架目录介绍1、common模块读取Excel代码读取yaml代码(支持场景关联)jsonpath断言封装代码requests二次封装(get、post)configparser读取配置文件递归遍历字典常用方法log日志封装2、conf模块3、data模块4、case模…...
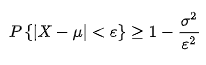
应用统计432考研复试复试提问总结精简版【一】
一、区间估计与假设检验的联系与区别 联系:二者利用样本进行推断,都属于推断统计区别: 原理: 前者是基于大概率,后者基于小概率;统计量:前者是构造枢轴量(不含未知参数,…...
Pytorch模型量化
在深度学习中,量化指的是使用更少的bit来存储原本以浮点数存储的tensor,以及使用更少的bit来完成原本以浮点数完成的计算。这么做的好处主要有如下几点: 更少的模型体积,接近4倍的减少;可以更快的计算,由于…...

已解决Encountered error while trying to install package.> lxml
已解决(pip安装第三方模块lxml模块报错)Building wheels for collected packages: lxml Building wheel for lxml (setup.py) … error error: subprocess-exited-with-error python setup.py bdist_wheel did not run successfully. note: This error o…...

距离度量 —— 闵可夫斯基距离(Minkowski Distance)
Python学习系列文章:👉 目录 👈 文章目录一、概述二、计算公式1. 闵氏距离公式2. 闵氏距离的参数 p3. 闵氏距离的缺点一、概述 闵可夫斯基距离 (Minkowski Distance),也被称为 闵氏距离。它不仅仅是一种距离,而是将多…...
python(模块)xlwt
目录一、xlwt简介二、xlwt语法1、模块安装2、模块导入3、向xls文件中写入内容4、设置写入文件的格式4.1 字体设置(font)4.2 背景颜色设置(pattern)4.3 边框设置(borders)4.4 对齐方式设置(align…...

Pytorch中torch.unsqueeze()和torch.squeeze()函数解析
一. torch.squeeze()函数解析 1. 官网链接 torch.squeeze(),如下图所示: 2. torch.squeeze()函数解析 torch.squeeze(input, dimNone, outNone) squeeze()函数的功能是维度压缩。返回一个tensor(张量),其中 input…...